-

-

-
-

-

-

-
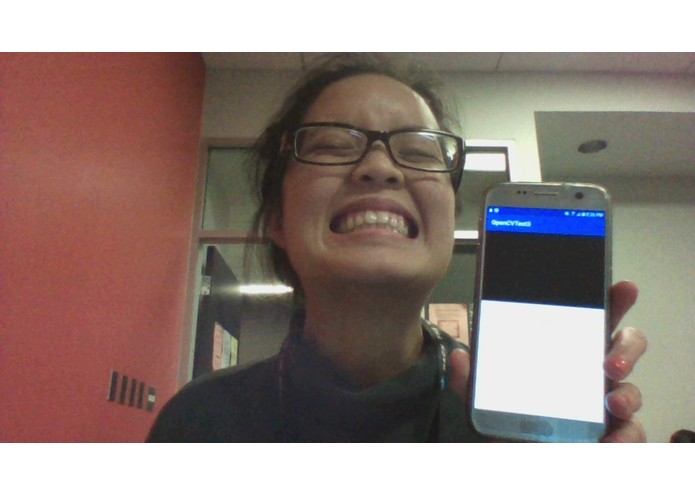
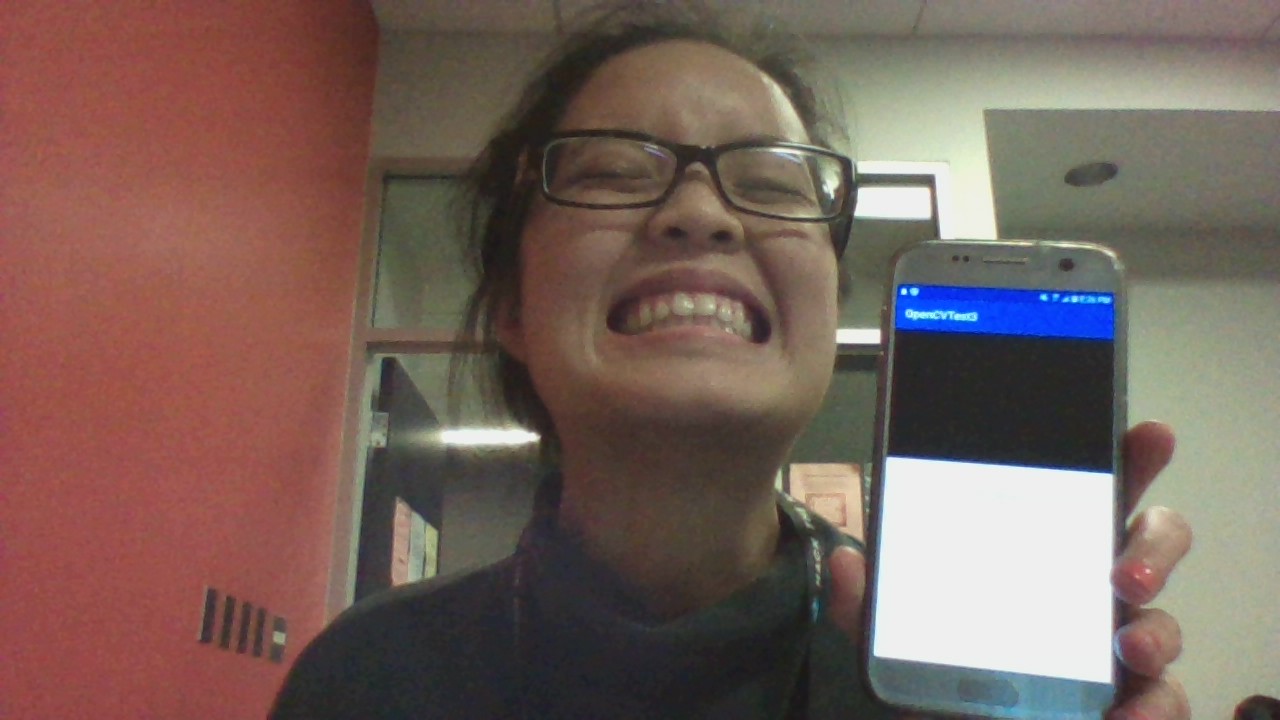
A really bad photo of the unfinished app





Inspiration
When I first saw this problem, I knew I wanted to do it. It was an interesting problem because of the severity of the problem, as well as the unknown environment made the challenge look more alluring. Initially, I was with another team who wanted to create another hack, but after attending the Workshop, I knew I had to do it as my heart yearned for it, and I already had a general idea of basic concepts I wanted to incorporate when solving this issue - a bit of image recognition, a bit of machine learning, all ideas I knew very well. As someone who has worked with Photoshop, Premiere, and After Effects for over 10-15 years of her life, I was excited to implement those skills sets within the problem. Within the next 33 hours, I worked alone trying to solve this problem.
What it does
The app I have created serves to automate the process of detecting unknown/foreign/suspicious behavior and targets within media, whether it is in real time or imported. By automating this process using object detection, we are able to increase the efficiency and speed of the task being done. In addition to automation, the app serves as a platform for other functions, such as detecting and "creating" extensive information about an environment, and altering the image to enhance image processing for further refinement of information with real time footage and previous images. This information will be stored for increasing machine learning algorithms to better predict other anomalies as well as be used as a reference point for any reoccurance in behavior.
The main functions of this app are to: automate identification via object detection, uses template matching to further construct the environment around them, alteration of an image in real time using edge detection, thermal vision, thresholds, white balance, bilateral filters for denoising, and level curves, and detection of foreign movement using marked anomalies and CNNs. These are the most important features in order to solve the problem. It solves the problem through means of automation, detection of change of behavior and identifying abnormalities, and processing images for detection and further refinement. All this information is stored to be viewed after later.
How I built it
The main platform of this hack is through an app. It is an app as the idea behind it was for it to be used either remotely and transmits data into a mobile device, or to be used in real time should personnel be needed to go into the field. The app was made through Android Studio using Open CV libraries. Open CV had a lot of useful pre trained models such as image configuration with various features (face detection, object detection, marked anomalies, template matching, average movement for videos, etc,), so I wanted to incorporate this in a user friendly device.
Challenges I ran into
I was unfamiliar with all the technology I used; I have never coded in Python (my initial plan), Android Studio, OpenCV, or TensorFlow, so it took me a lot longer to perform as I had major setbacks. Because I decided on this project last minute, I spent a good chunk of my time devoted to just installing the required software. In addition, because I was a team of one person, it was hard bouncing back ideas, which made my reflection process a lot harder and longer. Thus, I found myself to have focused too much on a certain aspect of a problem which wasn't deemed as valuable or directly solving the problem.
Accomplishments that I'm proud of
First and foremost, I'm proud of myself to have the guts to leave my team to work on this project that I was really passionate and excited about, despite having to work on it alone. I think it really shows that I will go after what I want, despite being scared, and that's something I'm proud of (and can't believe I did...). I am proud to have learned a lot in this experience when starting with nothing; I now have a deeper understanding of deep neural networks, creating a basic app, using OpenCV on a phone, and the potential CV has. Making this app all alone makes it a lot more satisfying. I am also proud to have been told that I had a very unique vision, as that is something I want to continue to provide. Whether or not my algorithm functions properly, I like knowing that I had a clear direction on how to solve this problem.
What I learned
I learned a lot in this experience as I started with nothing; I now have a deeper understanding of deep neural networks, creating a basic app, using OpenCV on a phone, and the potential CV has. I have also learned the dangers of working on Windows and using Java. In retrospect, I would have solved this problem directly without Android Studio, as it complicates the problem in itself. I would have just stuck with OpenCV and Python. If I had time, I would have trained my models using TensorFlow, as it is a very powerful tool. I would have also tried to use YOLO/SSD to perform more object detection
What's next for CANSOFCOM
Further developments will come to aid in bridging footage from different angles using methods of triangulation. This is a hardware and software endeavor. I would also like to create a library based on old data (faces, weapons, etc) to be used during object detection, and would like to see this process detect changes over a long span of time. This would be helpful for tracking data such as the effects of climate change overtime or how a human grows and their body affects it.


Log in or sign up for Devpost to join the conversation.