Inspiration
A large amount of data is collected annually and released to the public, however, there is no easily accessible avenue to read and understand this data for a Canadian. Retrieving information about specific areas of Canada can be difficult to find and documentation is sparse and requires significant background knowledge. Thus, there needs to be a system which allows Canadians to view this data easily and reasonably without having to navigate through endless pages and download and parse datasets.
What it does
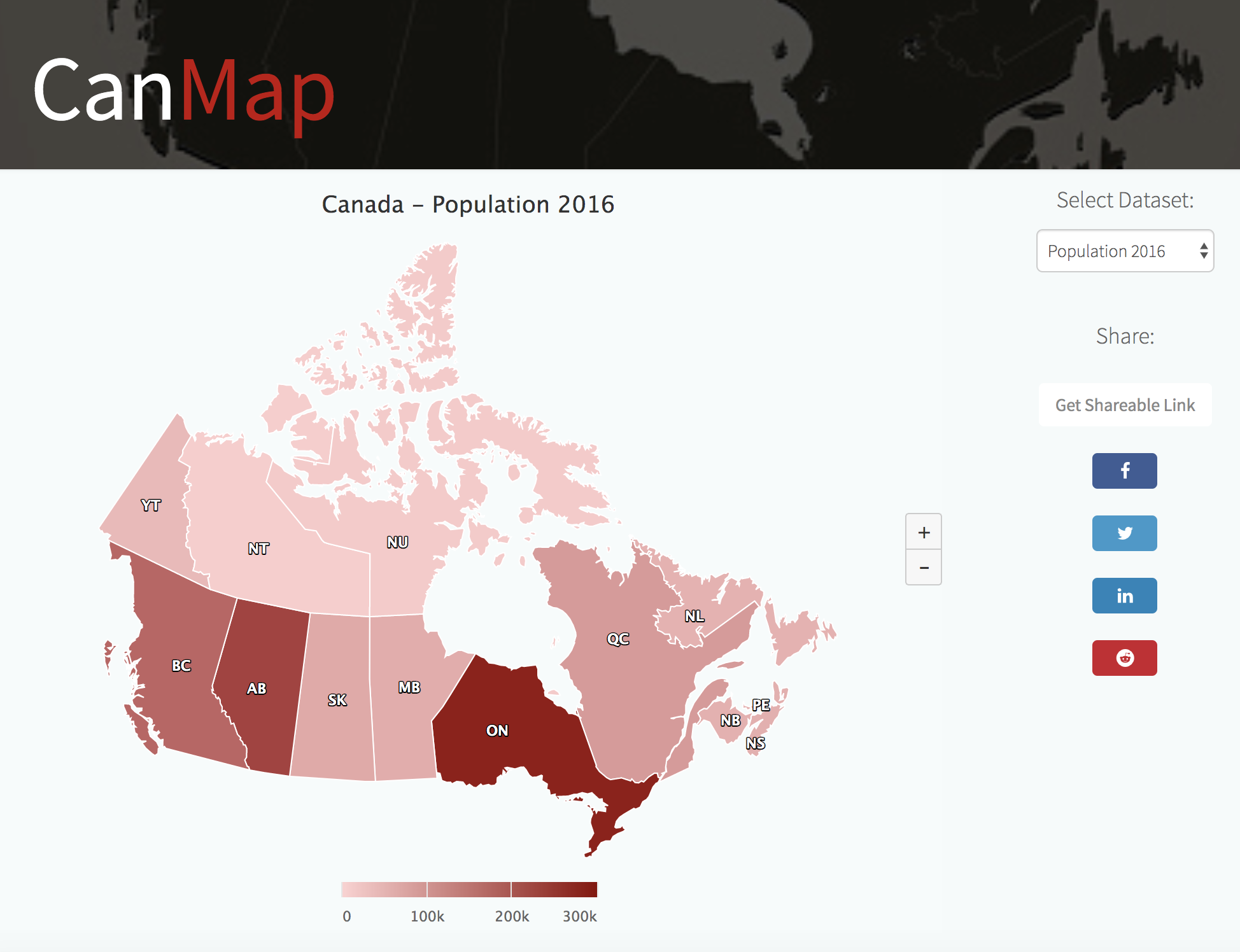
The goal is to develop a system that will provide statistical information about Canada in a better manner by allowing quick access to data without the need for browsing and manually parsing data sets.
How it was built
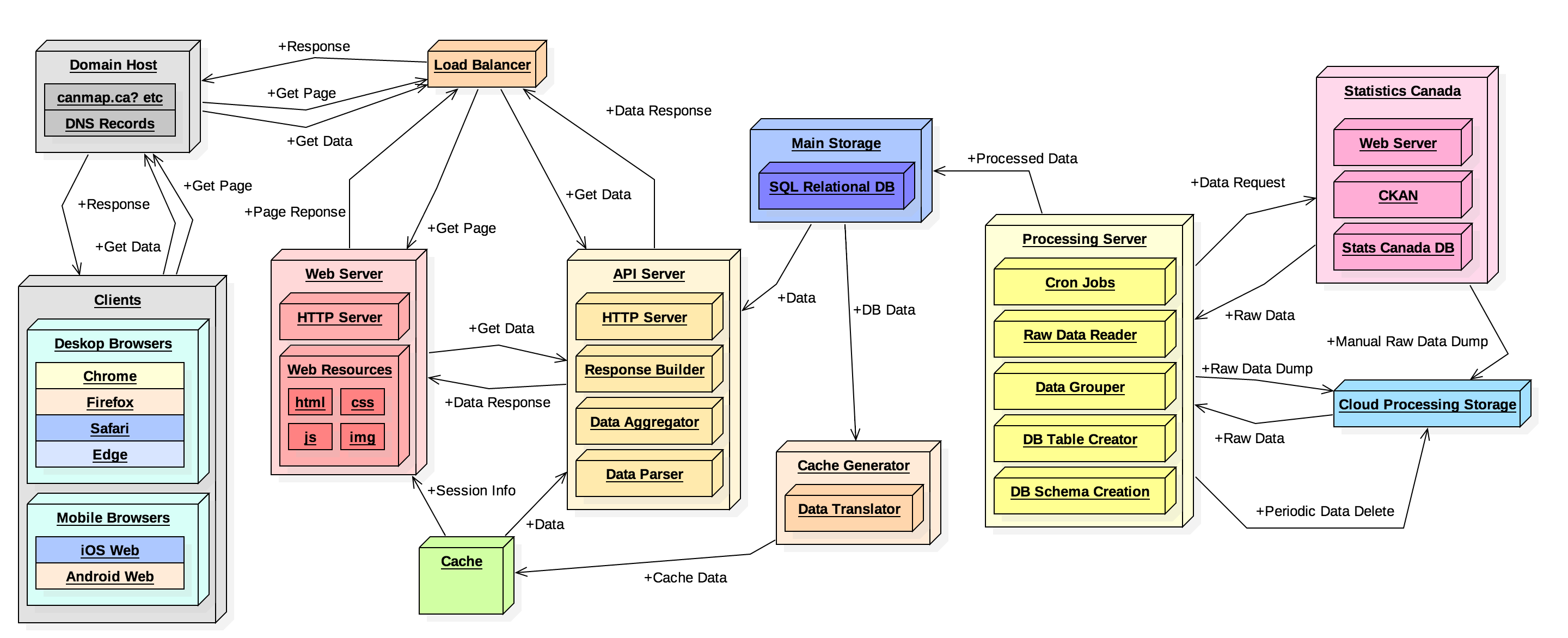
The system was split into four logical components:
- Collection: Responsible for getting the data from StatCan and transferring it to our datastore.
- Processing: Takes the CSV data from StatCan and transfer it into a SQL datastore, while simultaneously doing rudimentary statistical analysis. This subsystem also populates the cache with frequently requested datasets.
- Retrieval: Renders data from the cache and database into JSON and exposes it at various endpoints.
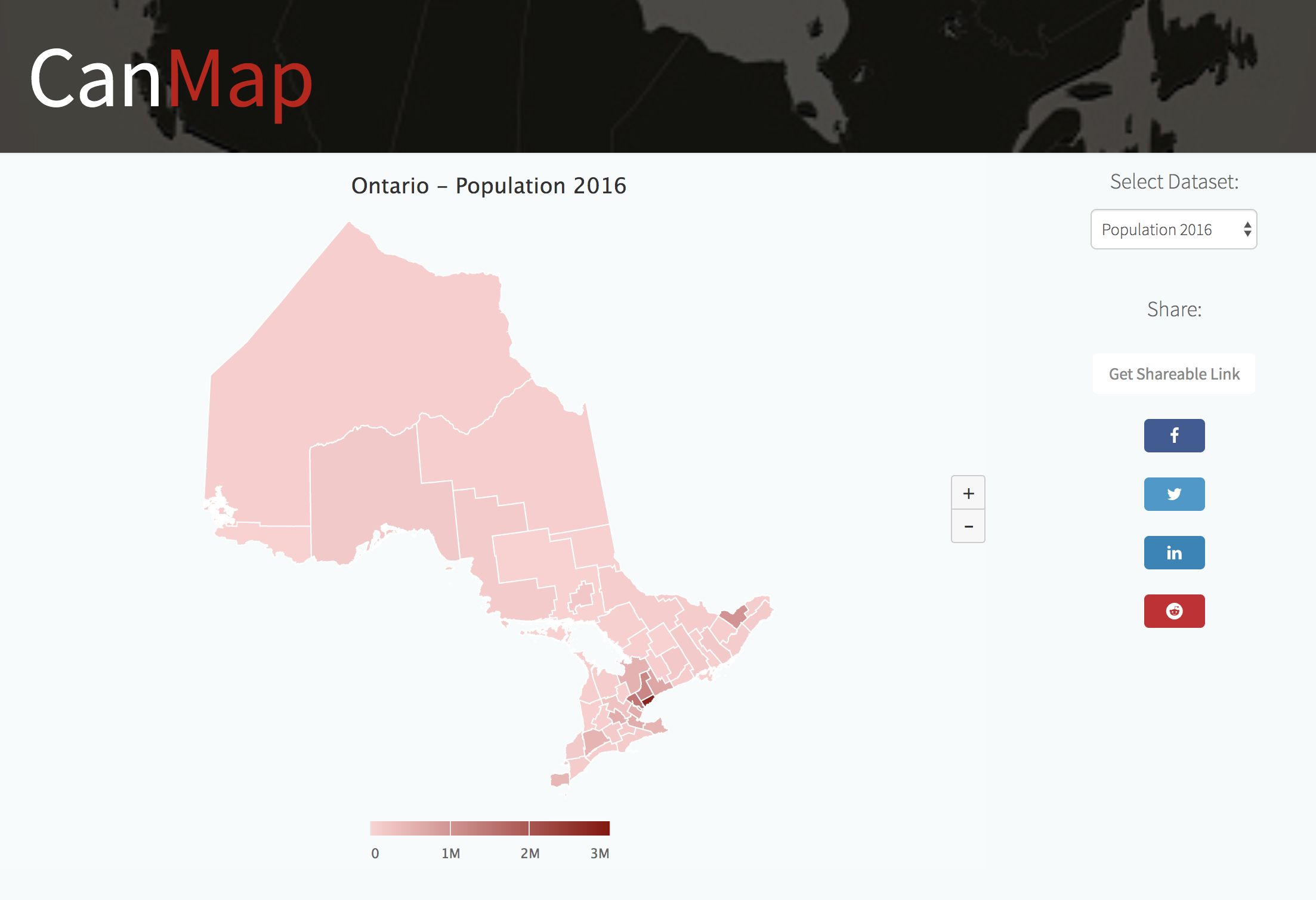
- Visualization: Renders the data from the dataset and into a map and displays it on a web page which the users can interact with.

Log in or sign up for Devpost to join the conversation.