-
-
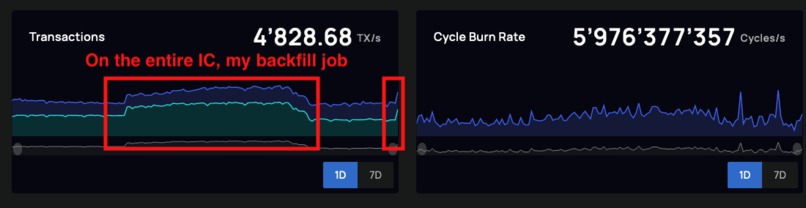
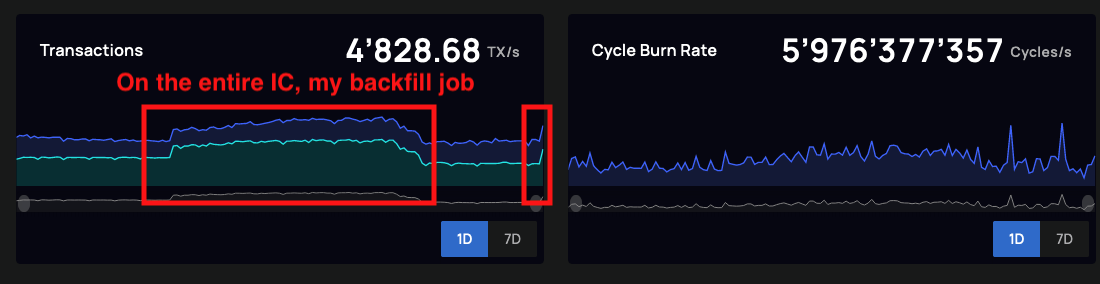
Overall IC transaction volume in relation to my CanDB backfill processes
-
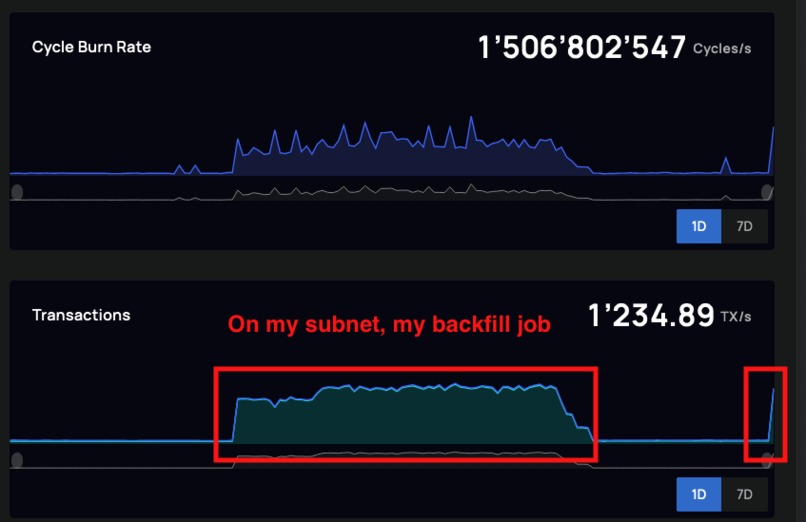
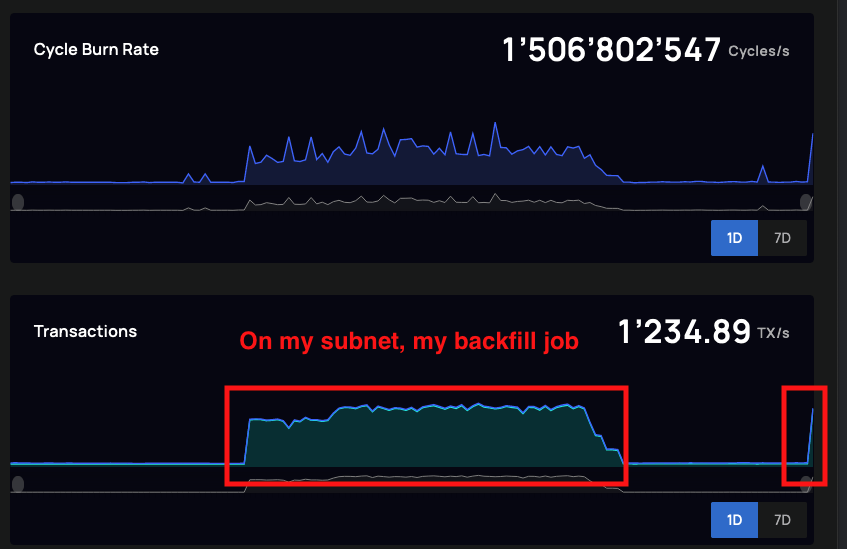
My subnet able to handle high transaction volume using CanDB to backfill GB of data
-

CanDB's always cheery mascot, "Canie"

Inspiration
CanScale is an initiative to build scalable distributed infrastructure for the Internet Computer (IC) blockchain. CanScale’s first project, CanDB, is non-relational, performant, and horizontally scalable multi-canister database. CanDB provides a familiar and flexible NoSQL API that abstracts and automates multi-canister spin up & auto-scaling, data partitioning, and data persistence and stability. This enables developers to focus more on application development and less on IC specific distributed data storage design.
At Genesis launch, the IC was not released with a pre-built data-storage solution allowing developers to seamlessly scale storage past a single 4GB canister. For most simple applications, 4GB of canister memory is sufficient. However, developers who later need to scale past that limit will soon find great difficulty refactoring and appropriately partitioning their initial data model and data structures while ensuring that partitioned data is persisted and stable across canister upgrades. Without a readily available scalable storage solution such as CanDB, data storage on the IC becomes a major roadblock for development and consequently slows IC adoption by developers and entrepreneurs. By building CanDB, the CanScale initiative aims to empower creators by removing these barriers, acting as a catalyst to increase the rate of development on the IC.
What is this demo
The demo video is almost 16 minutes, and covers the following topics:
- Why the IC needs a generic and scalable solution for data storage
- How CanDB Works ⚙️
- Reddit on the IC? A live demo hosted on the Internet Computer
- CanDB & Microservices 💜…a match made on the IC
- Currently supported features
- The CanDB Roadmap 📆
- A special announcement
The live on-chain demo application showcases a completely on-chain demo application backed by CanDB that can flexibly query 4 million comments from Reddit.
The backend application is holding roughly 8GB of comment data split amongst a cluster of 149 canisters.
How can I interact with the application?
Great question, the "Comments" and "Monitoring" tabs at the top point to different applications that demonstrate how a developer might both utilize CanDB to build an application for their users, as well as monitor that application.
End-User persona ("Comments" tab)
You can query the comments by:
- Top score overall
- Latest comments with a subreddit (lowercase)
- Latest comments overall
You can also change the date range to filter the comments received.
Use the "Next Page" button to query the next page of results (which under the hood uses the nextKey directly below this button as the Sort Key for the upper bound of the next query request).
Engineer persona ("Monitoring" tab)
Navigate to the "Monitoring" tab, and query your fleet of canisters. Use column ordering to see which canisters have scaled, as well as other metrics such as other canister metrics like entities (rows) inserted, heap size, and cycles remaining.
How it was built
The code for the demo is publicly available at https://github.com/canscale/supernova-candb-demo. The demo has a Motoko backend, and a TypeScript + React frontend. The backend utilizes the CanDB Motoko library, and the frontend utilizes the candb-client-typescript TypeScript library.
For those without repository access, you can view the publicly available documentation:
- CanDB - https://www.candb.canscale.dev
- candb-client-typescript -> https://www.candb.canscale.dev/client-typescript
Data for the demo comes from the publicly available Kaggle Reddit Covid Dataset, which contains 12.65GB of comment data mentioning Covid-19 up until October 25th, 2021 (10-25-21). This demo uses 2.85GB of that data, in comments ranging from 7-14-21 to 10-25-21. On the backend, CanDB's equivalent of local secondary indexes are used to replicate the data in order to support different data access patterns, resulting in roughly 8GB of data storage across > 100 canisters.
The data was preprocessed and chunked into 500 comment row csv file chunks all grouped by the comment date using Python.
A series NodeJS backfill scripts included with the submitted assets in supernova-candb-demo/backfill was assembled using the candb-client-typescript library to interact with the CanDB index canister and batch update calls to the appropriate backend CanDB storage partitions. Additional upgrade and delete scripts (using the candb-client-typescript and CanDB index canister backend) were used as well to perform rolling canister upgrades and targeted canister deletion in case it was needed during the backfill process.
Challenges faced
The IC has a 2MB upload limit, so data needed to be pre-processed into small update chunks, which greatly slowed down the backfill process. Luckily, by parallelizing the backfill process job, I was able to speed up the data backfill significantly. In fact, I was impressed by the IC and my subnet's ability to handle the sustained load ~1300 transactions per second I was giving it (see attached screenshots).
Several errors and performance issues cropped up when testing on the main network that I was unable to reproduce locally. Debugging production errors on the IC can be difficult, and while I was able to work around these issues one of the top priorities for the CanDB project going forward will be to stress test the IC and CanDB, in order to further improve performance and provide developers with predictable cost and performance metrics.
Is there more to CanDB than what was shown in the Demo Video?
Yes! What was shown in the demo video is just a brief snippet of the features that CanDB currently provides. For example:
- Performant and Rich CRUD + scan APIs (not just scans like shown in the demo). Here is the endpoint that was used to backfill millions of comments into the demo application via a CanDB data structure on the Comment Actor
Canister cluster management features:
a. Support for rolling upgrades Code from the demo application deployed to the main net
b. Support for targeted canister deletion by partition key Code from the demo application deployed to the main net
Abstracted and easy to set-up auto-scaling
a. Set user-defined auto-scaling limits for your canisters, but don't fear the responsibility, as CanDB will eventually auto-scale for you if your limits are too high.
b. Use the [createAdditionalCanisterForPK hook] in your canister responsible for auto-scaling to scale out your canisters when they fill up.
Stable and persistent data through upgrades - CanDB keeps you safe by providing a flexible range of stable data types to store as attributes
An easy-to-use typescript client sdk - Set up client interactions with your Index Canister, your Actor Canisters, and then performing query and targeted update calls to the specific canister where the update should take place.
Accomplishments that we're proud of
Just during the time period of the hackathon, entire multi-canister CanDB backend, the frontend client, and the demo were built - turning what was previously Single Canister POC and a design into a full-fledged working multi-canister solution with a working demo.
As of this demo, CanDB is the first scalable NoSQL database on the IC.
What we learned
Too many things...if you want to follow my herd of questions on the developer forums, you can find me @icme on forum.dfinity.org. You can also reach out to me with any questions @can_scale on Twitter or @CanScale#1607 on the DFINITY developer discord.
What's next for CanDB
Q2-Q3 2022 (Closed Alpha)
- Start alpha testing with 10-20 dedicated teams (reach out to the handles listed above if interested)
- Stress/Chaos Testing
- Performance & Metrics iteration and publish developer expectations report
- CanDB Migration Guide (for existing applications)
Q3-Q4 2022 (Open Beta)
- End alpha-testing phase
- Secondary indexes
- Role based access control
- CanDB Logger (using CanDB)
- Start open beta
Built With
- motoko
- react
- typescript










Log in or sign up for Devpost to join the conversation.