Inspiration
As starry-eyed teenagers, when we dreamed of becoming computer scientists and engineers, we imagined creating models, building tools, and optimizing processes that solved important issues one by one, leading to a better world. As we now move closer than ever to formally entering the tech workforce, we know that reality is far from what we had hoped. We now see how algorithms can inherit the biases of its creators, models can disadvantage entire groups, and well-intentioned tech can be used to do more harm than good. As computer science students, we see it as our responsibility to always work towards the directions of greatest benefit to all members of society, and to always draw attention to injustices through tech whenever we see them.
With COVID as a new reality, we see that it puts the structural inequalities that have always been present in our society in the limelight. As vaccines rollout across the country and we receive our own vaccines, we wanted to create a product that models the fairness of how vaccine distributions affect different groups.
What it does
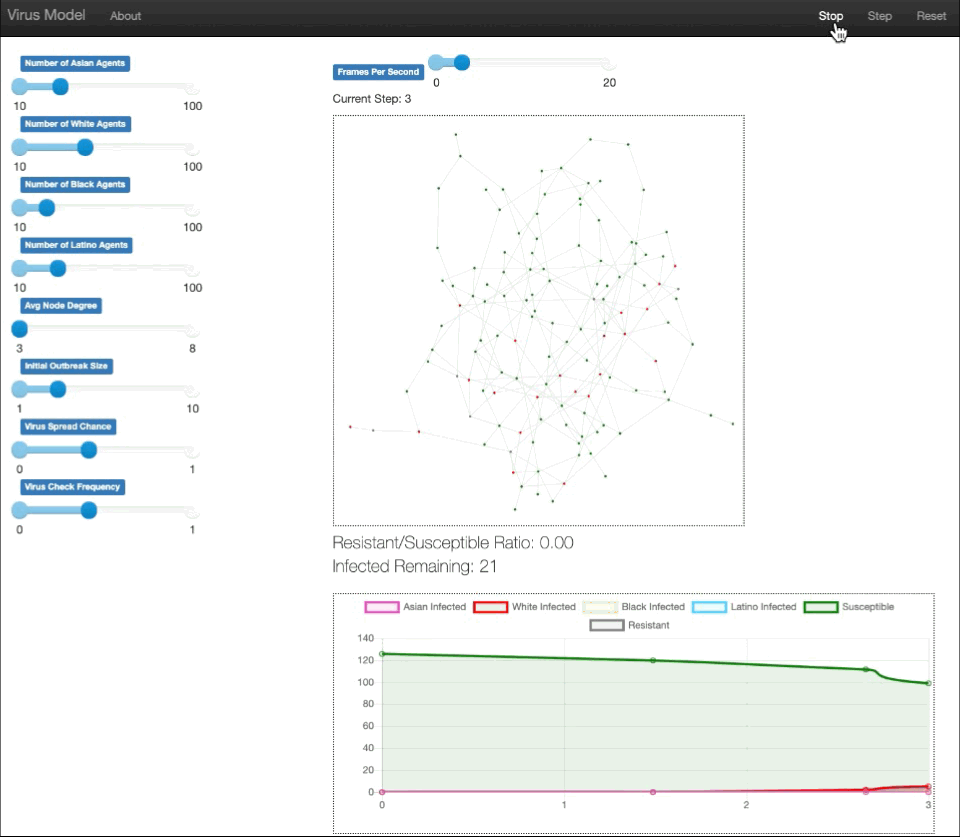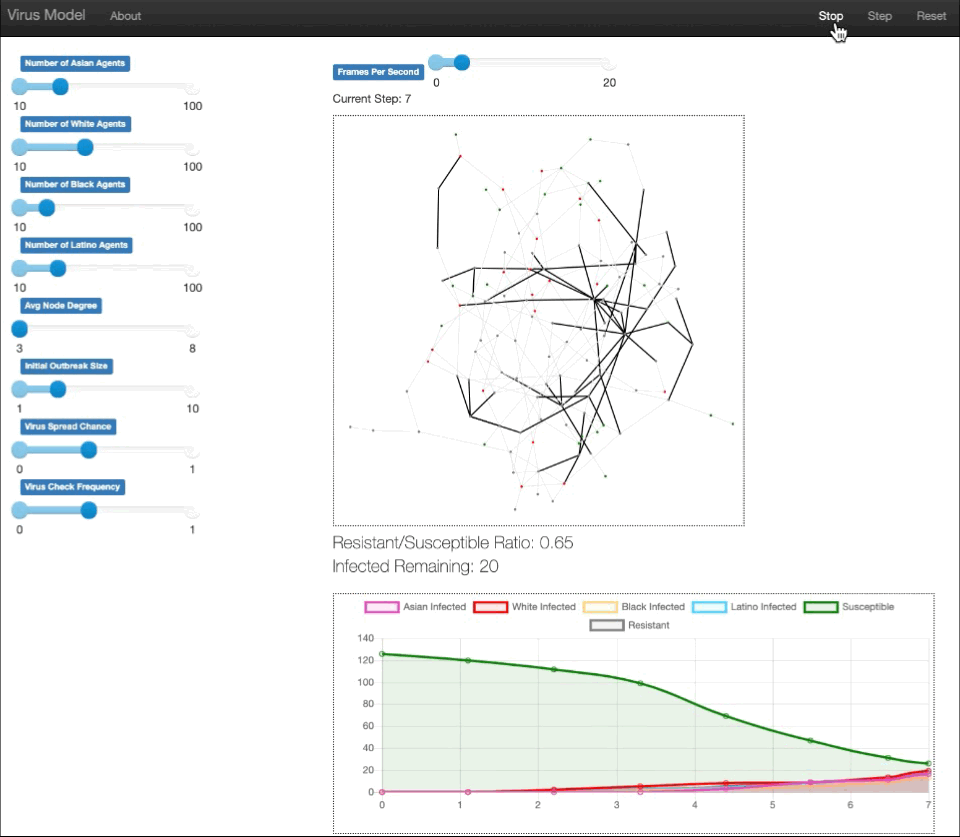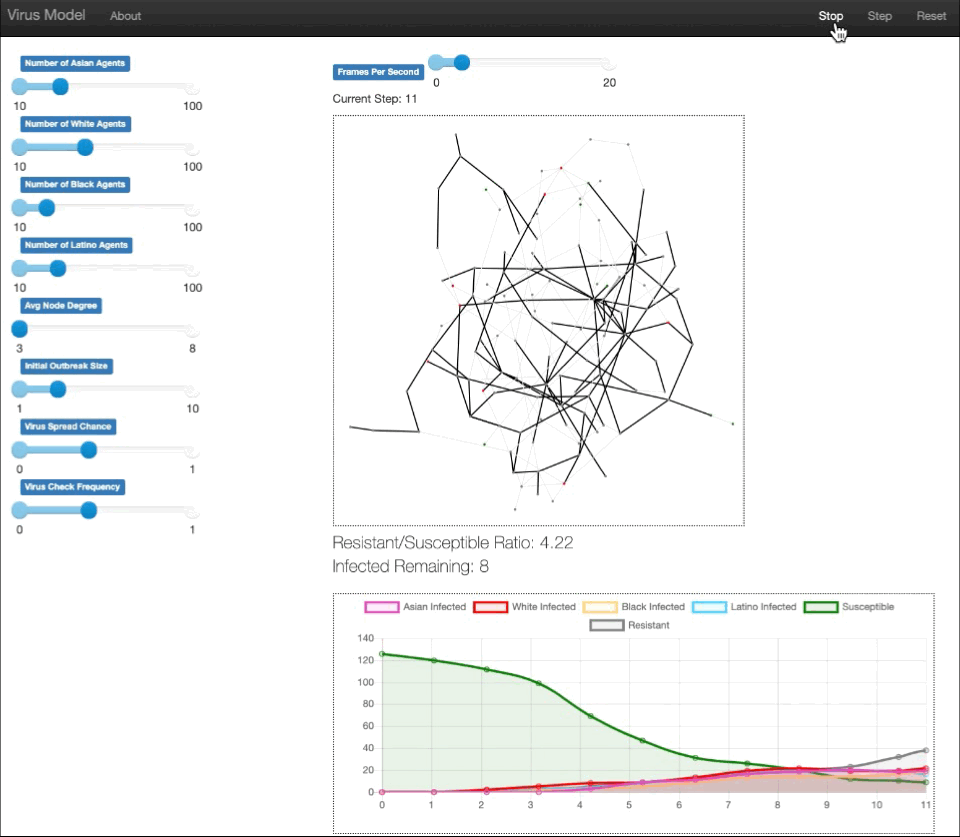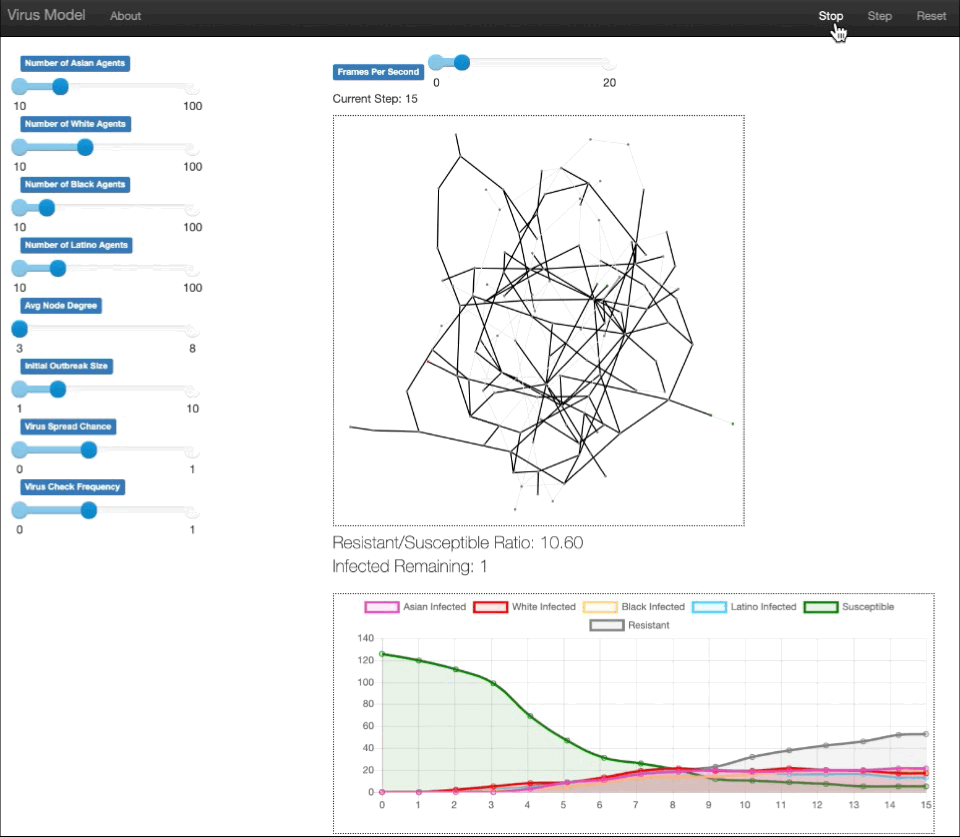
We built an agent based model that simulates how COVID spreads (with states of specific infected, susceptible, and resistant) through a diverse population with vaccine rollout as predicted for different races through our machine learning model. Thus, through the simulation and data collected, we can see the differences in the infected population of different races due to the vaccine distribution. The individuals, or agents, are represented as nodes in a Erdos-Renyi graph. The edges between the nodes represent paths of possible infection. The parameters of demographic populations, average node degree, virus infection chance, etc., can be controlled through sliders on the server, allowing for personalization of the model.
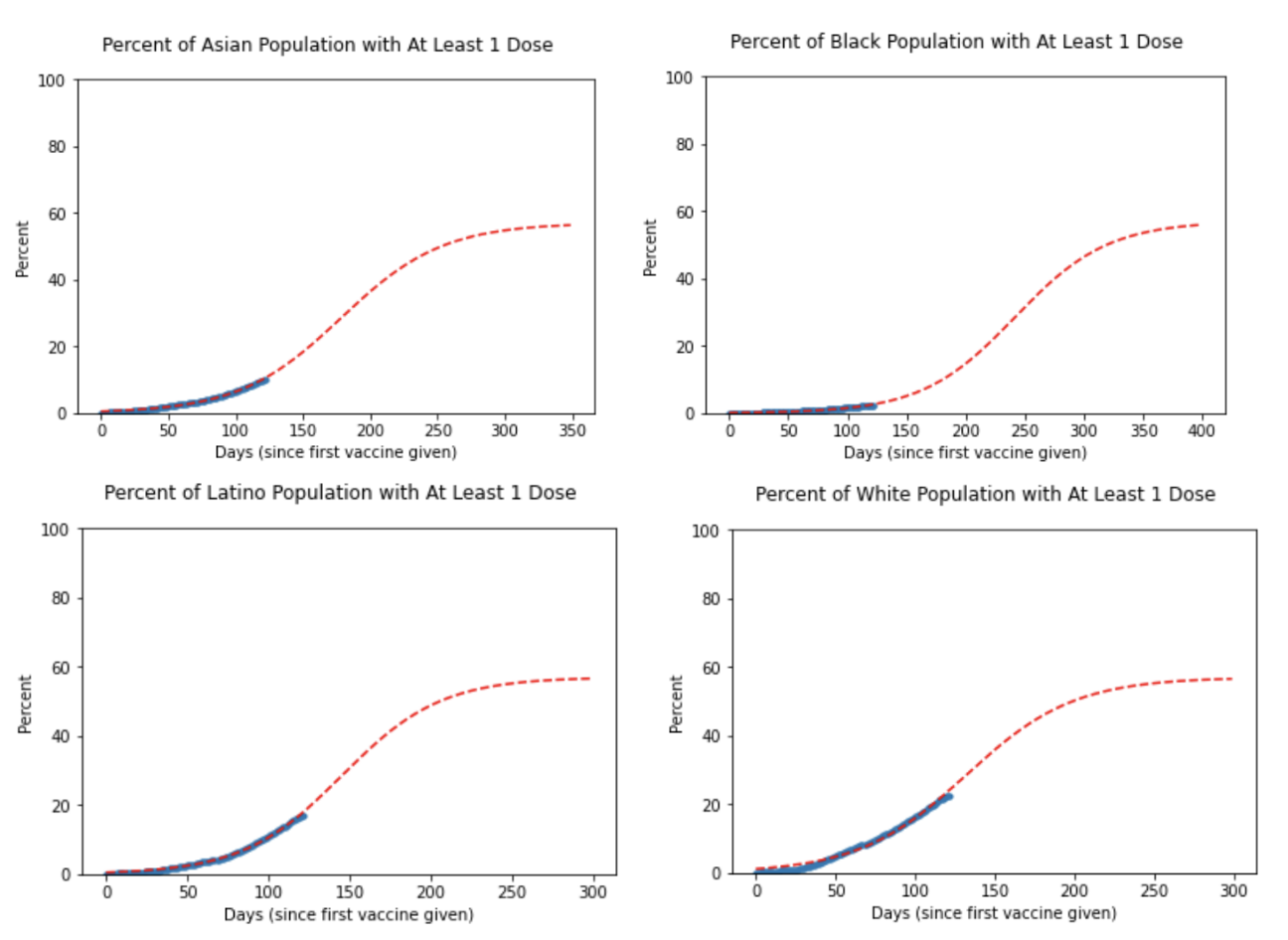
As follow-up, we built a machine learning model to predict how long it would take, given the current vaccination policy and based on demographic of the population, for everyone, who is eligible, in California to receive the vaccine.
How we built it
After reading the related literature, we knew we wanted to create an agent-based models, because we considered agent-based models to be the best for simulating new phenomenon on which there is limited data available, and is not well understood due to many confounding/hidden factors.
We drew inspiration from NetLogo, a popular agent-based modeling and visualization environment that was used to produce many visualizations of famous models such as the Schelling’s model of segregation. We wanted to work in Python because it was the language that we had the most experience with collectively as a group, and with the amount of modules available we felt like we had the most flexibility there to include all the features we wanted.
We used Project Mesa, which is an agent-based modeling framework for Python. This allowed us access to useful modular components, browser-based visualization, and the example model libraries that we looked through to decide on the design for our model. Drawing from our knowledge of the SEIR model and the transition functions between states, we created states for our agents, and based on their features and placement on the graph, rules for the agents that would determine their actions in terms of infection, spreading infection, or receiving the virus.
Then, in building our machine learning model, we wanted our model to mimic the current vaccination policy as closely as possible. In California, only those above the age of 16 are allowed to receive the vaccine. Since approximately 19% of the population is 15 and younger, I removed 15% of the population. Studies have also shown that approximately 30% of adults will refuse vaccines, even when offered, so I further removed 30% of the remaining population.
Vaccinations are generally slower at the beginning, due to vaccine shortages and bottlenecks. Over time, the number of vaccinations that are distributed increase extremely rapidly as vaccines are mass-produced, and the public is educated on the benefits of receiving the vaccine. Furthermore, as we progress through the phases of vaccine distribution, a larger portion of the population is allowed to receive the vaccine. However, this rate slowly drops off, as the number of people who wish to receive the vaccine declines. A logistic model fits this description, and thus we chose to apply a logistic regression to our data in order to make our predictions.
Challenges we ran into
Before starting on this project, we hadn’t had any experience with agent-based models, so it was a challenge to learn how to correctly build these models, which assumptions you can make in which situations, and how to choose the best design for simulation in a short period of time.
We also had to understand the Mesa framework in order to make our own changes and expand the limits of the model and data visualization/analysis. We discovered that agent-based models are very prone to small errors that have a ripple effect throughout the model, so learning to find those and fine tune areas was a new challenge. Lastly, we had to constantly check to be sure that we weren’t putting our own biases and unfounded assumptions into the model.
Due to the ongoing and quickly updating situation of vaccine rollout, the most recent data often requires heavy cleaning and engineering to be able to be used for a machine learning model. A dataset that contained the data we needed was encoded incorrectly. After going through the conversions to bring it to UTF-8 format, we were unable to run our Generalized Additive Model in R, because the font family was not supported on our OS. Unfortunately, there was not a quick fix for this issue, and we had to pursue the model through other modules in python instead.
Accomplishments that we're proud of
We are proud that we managed to create an agent-based model tool, along with its visualization framework, that allows people to simulate how a certain vaccine distribution strategy will affect different populations of people differently, quantifying the inequalities these distribution strategies can cause.
We are additionally proud that we learned about a new class of model, explored its computational limits, and have many more initiatives that we would like to explore in this area.
What we learned
We learned about vaccine rollout distribution strategies, trends, and how these distribution strategies systemically disadvantage certain groups of people.
We also learned about agent-based models and statistical simulations.
From our model, we discovered that it takes approximately 200 days for the White population and Latino population to achieve 50% vaccination, 250 days for the Asian population to achieve 50% vaccination, and approximately 300 days for the Black population to achieve 50% vaccination. It is apparent that the current method for vaccine distribution is unfair. From this model, it can be inferred that geographical areas with a higher white population may achieve herd immunity much faster than areas with a higher Black population.
From both our agent-based model and logistic regression model, it is apparent that the current vaccination policy can be improved on in order to ensure equitable distribution.
What's next for Agent-based Model for Fair Distribution of COVID Vaccines
We want to expand our product to model more situations, and include more agent features besides race, such as age, gender, income, location, etc. We want to create a product that can be heavily customized because we understand that the optimal distribution strategy differs widely between states, counties, and even communities. Our product should be able to be used on a community level, so that each community can simulate for themselves the best way to distribute vaccines. Eventually, we want this product to be generalizable to distribution of all types of things, not just vaccines.


Log in or sign up for Devpost to join the conversation.