-
-

User interaction with custom skill and how user requests are processed
-
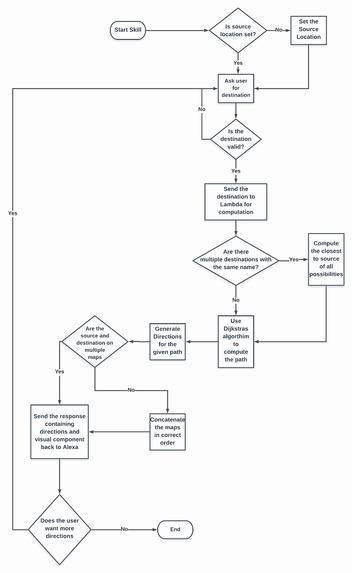
Workflow of the System
-

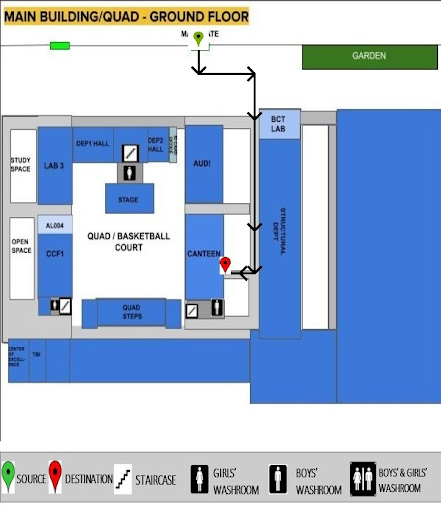
Sample Map Image
-
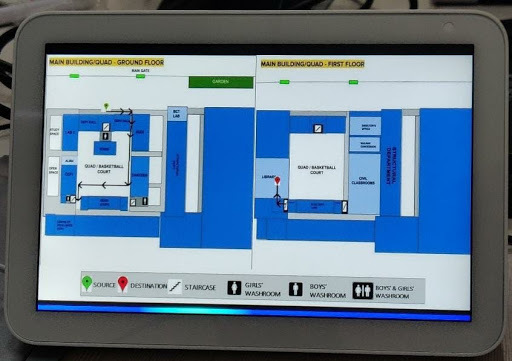
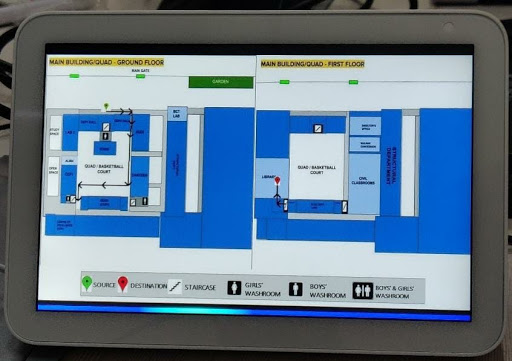
Output on Echo Show - A device placed in the campus


Inspiration
Many colleges around the world have vast campuses, spread across acres of land, and so was the case with our college VJTI. Visitors have faced immense difficulty in finding their way through our huge campus. We realised that for outdoor navigation, there are excellent services like GoogleMaps, however there is no such one-stop solution for indoor navigation. Beacons, sensor networks, etc can be used, however, the cost of the system increases drastically. Thus, we realised that we need a cost-effective indoor navigation system for our campus. Since our campus is in India where Hindi is widely used, the system should be multilingual, supporting both English and Hindi.
Keeping these things in mind, we have developed a navigation system for our campus by leveraging the power of Amazon's Alexa Skills. A visitor just has to invoke our Alexa skill on any Echo Show device placed in the campus and give it a destination location. Alexa will not only provide detailed directions but also display a visually appealing map with the route marked on it.
What it does
The Alexa Skill developed as a part of this project helps visitors of VJTI college to navigate through the way easily. Users would simply go to Alexa and ask for directions to their desired destination. If the destination is a valid location on the college's campus, then our Alexa Skill provides the user with the most efficient route to reach that place. A visual map will be provided for the user’s convenience. The user can keep asking Alexa for directions or even change the source location to a place of his choice. The user can also ask for the nearest restroom. If the user is facing any difficulty, he/she can ask for help to which Alexa will respond aptly.
How we built it
The major steps that have been taken in developing the system are:
1. Modelling the Maps The campus has been divided into 3 regions. Each region has maps representing different floors. Each important location on the campus is stored as a node. The nodes are represented as pixel coordinates of each map image. A mapping of the node index to the node metadata is created, so that when we receive a location as input we can derive the pertinent information like the coordinates, map number and floor that the node is placed in. Connecting undirected edges represent which two locations on campus are connected. The nodes and edges are stored in a static file that contains the pixel coordinates of the image, where each image is of the resolution 600 x 600.
2. Routing This forms the crux of the system, and to provide the shortest and most efficient solution, we have used a modified version of Dijkstra Routing Algorithm. In the modified version, we are not only finding the minimum distance (as is the case with traditional Dijkstras) but also the path from the source to destination. For special cases like washroom, our algorithm returns the closest washroom to the user.
a. Extending routing to multiple maps
There are many use cases such that source and destination would be far apart (such as two ends of the college) and would thus not be in the same (distributed) map. For such use cases, the routing algorithm has been extended so that even if a user wants to go to a location that would not be on the same map the most efficient distance (and path) would still be found.
b. Floor Navigation
The algorithm supports navigation on different floors as well. This has been done by adding edges for every staircase present. In the event that there may be multiple staircases to reach a destination, the closest staircase will be chosen.
3. Directions Providing the correct directions from a source to the destination is one of the most important parts of the CampusMaps. It is important to note that directions would vary from situation to situation- for instance, someone entering from one end of the college would find some places to be on his/her right, but for another person exiting the college via a gate on the opposite end, the same place would be on his/her left. For this reason, it was essential to account for the direction the person was already walking in, and only then could the next direction be provided.
For the special case where there is no previous direction to reference, i.e when the user is at the source location, a special provision has been provided such that the user is first told to turn in the correct direction after which the rest of the directions are provided. It has been ensured that the directions are provided in a language that sounds natural and conversational to the user.
4. Alexa Skill Development
Amazon Developer Console has been used to develop our Alexa skill. This platform is used to configure, build, test and maintain a skill after deployment. The initial configuration consists of setting an appropriate skill name, selecting languages for the skill (English-India and Hindi in our case), and choosing a model to add to the skill (Custom). The next step involves setting up build configurations which include selecting an invocation name, defining intents along with their respective utterance sets ,slots, and defining an endpoint which will trigger actions every time the skill is invoked. Finally, the model is trained with the chosen configurations and built.
The endpoint for our skill is a lambda function. The core backend logic for the skill resides in this function. It is responsible for extracting intent, slot values and other metadata from the request object it receives every time the skill is invoked. A response object is constructed which has an appropriate speech output and a re-prompt message (if needed). If the device invoking our skill has a screen, a map image is sent using Alexa Presentation Language (APL).The images are pre-constructed to reduce response-time and are hosted on a separate server.
Users can interact with the system by giving voice commands. Amazon's Natural Language Understanding (NLU) module is responsible for identifying utterances and their corresponding intents from the input and sending its findings to the skill's backend (lambda function) in the form of a JSON Object. The intents and slot values(if any) are extracted from this response object and appropriate action is launched. For instance, if the intent identified is DirectionIntent with a slot value library, a function called direction() is called. This function will return text which gives directions to the library, which should be interpreted by the device as speech-output.
5. Use of Modular Programming
This system uses modular programming to ensure the functionalities of different components are separated from each other. Each sub-module focuses only one aspect of the desired functionality (for eg routing, visuals). This approach improves the maintainability and the readability of the code and is convenient to make any changes in future or to correct the errors. This is also advantageous because such a system can easily be applied to any other campus or establishment, by simply changing the underlying map, related nodes and slot values in the skill. The rest of the modules would require minimal changes to be applicable to the new campus.
Challenges we ran into and how they were resolved
Converting blueprints of our college to their digital equivalents was a major challenge. This had to been done as accurately as possible so that the underlying algorithms function desirably. This phase took a lot of time from our project schedule.
Another major challenge that we faced was the incorrect recognition of locations that were spoken by the user in both English as well as Hindi. This was resolved by taking the following steps:
Removing Utterance Conflicts This issue was resolved by making utterances in custom intents more descriptive to remove ambiguity. Redundant utterances were removed.
Testing intent resolution capability As our skill's interaction model was being built, we used the utterance profiler, a feature in Amazon's Developer Console to test our model's intent resolution accuracy. The utterance set was modified whenever the test utterances did not resolve to the right intent followed by re-building the model.
Batch Testing using NLU Tool Natural Language Understanding (NLU) evaluation score with the annotation set (test set) determines how well the skill's model performs against our expectations. The score was improved by removing ambiguities in the utterance set and adding synonyms for various slot values.
Testing sample audio files using ASR Tool With Automatic Speech Recognition (ASR) Evaluation tool, we have tested and compared expected transcriptions against generated transcriptions for sample utterances. The issues uncovered during this test have been resolved by spelling out the words in utterance sets considering how they will be actually pronounced.
Accomplishments that we are proud of
- Modelling our campus' map was one of the major modules of our system and had to be as accurate as possible. We collected blueprints of our college and mapped them to a digital representation consisting of nodes (representing locations) and edges(representing paths between locations)
- Making a user friendly visual component from scratch which has markers for source-destination, clearly highlighted path with arrows and a descriptive legend.
- Developing a custom Alexa Skill with APL to support displaying maps dynamically- based on user's request and deploying an AWS lambda function which has our entire backend logic.
- Providing Multi-Lingual Support by developing interaction models for both English and Hindi Skills, using translation APIs for generated responses.
- Making our system modular - it can be easily used for other campuses by simply changing the underlying map, related nodes and slot values in the skill.
And most importantly, giving visitors a chance to explore the 16-acre VJTI campus without struggling for directions!
What we learned
- Building a custom Alexa Skill using Amazon's Developer Console.
- Enabling APL and using it for multimodal responses - displaying relevant map images hosted on Google Drive.
- Integrating various modules in the skill's backend and deploying it on AWS Lambda.
- Using CloudWatch Monitoring Tool to debug our Skill's responses.
What's next for CampusMaps
Currently, we have assumed that the position of the Alexa-enabled device is static thus limiting the user to understand the directions in a single-go. As future work, this system can be further enhanced by the use of Beacons for positioning, which can provide higher accuracy and dynamic navigation. We intend to increase the degree of modularity of the system so as to enable other campuses to make use of this system.





Log in or sign up for Devpost to join the conversation.