-
-
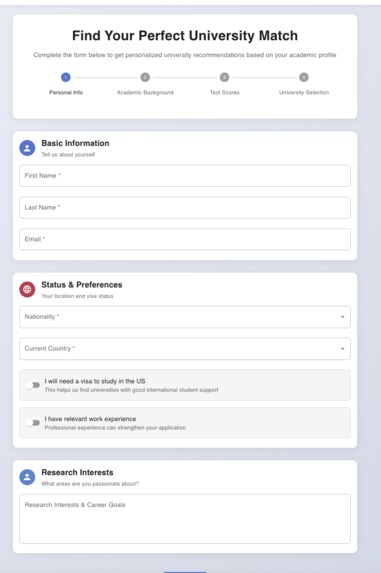
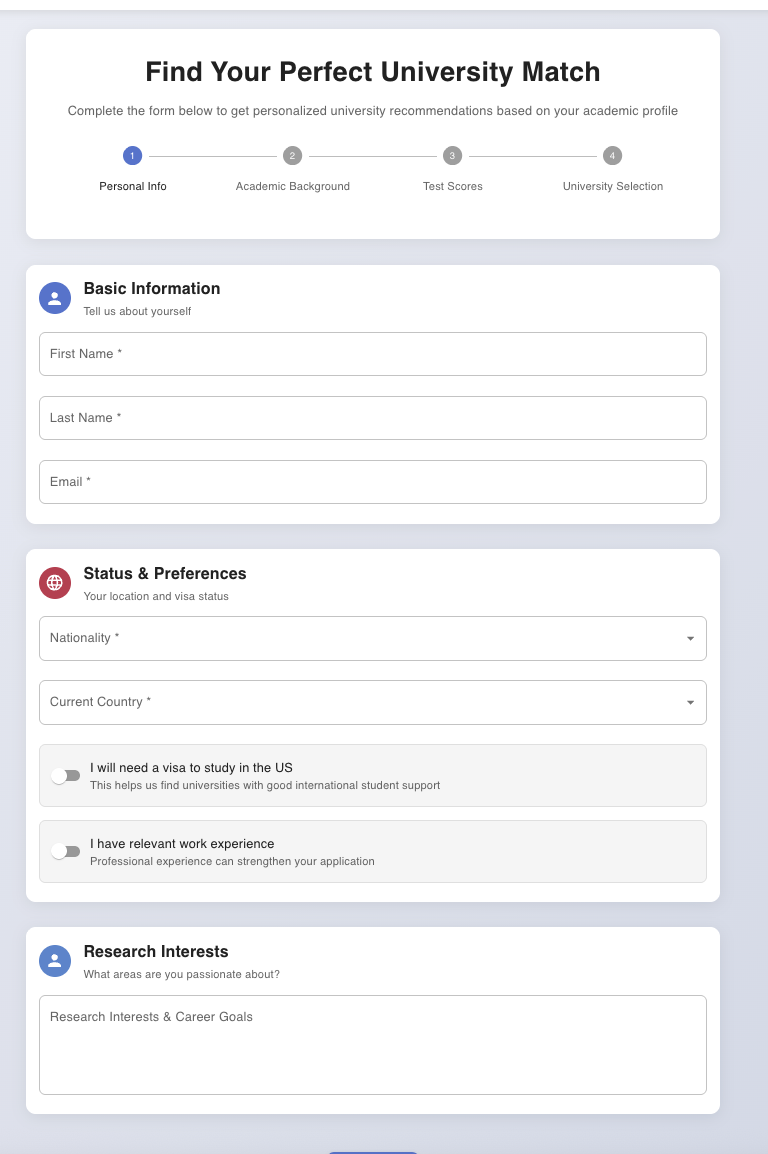
We are taking Basic information from Student
-
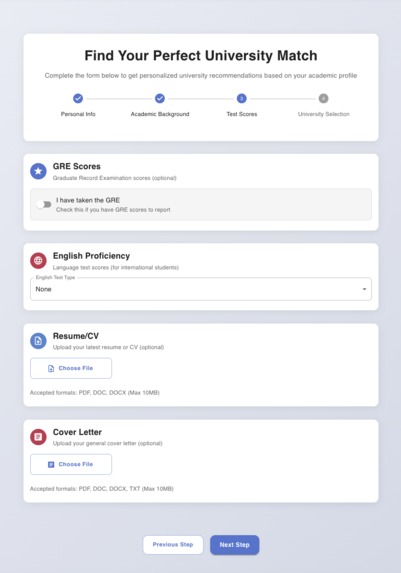
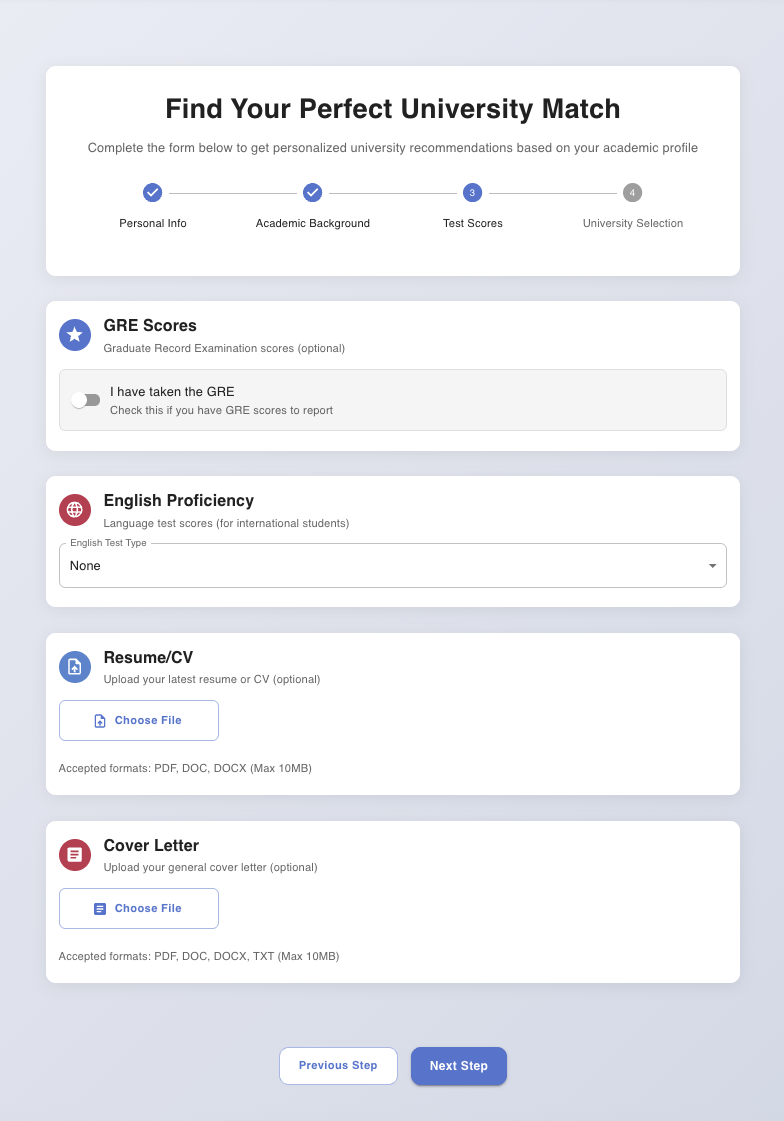
We are taking information like English Proficiency Score, GRE score, Resume, SOP and make a profile based on that
-
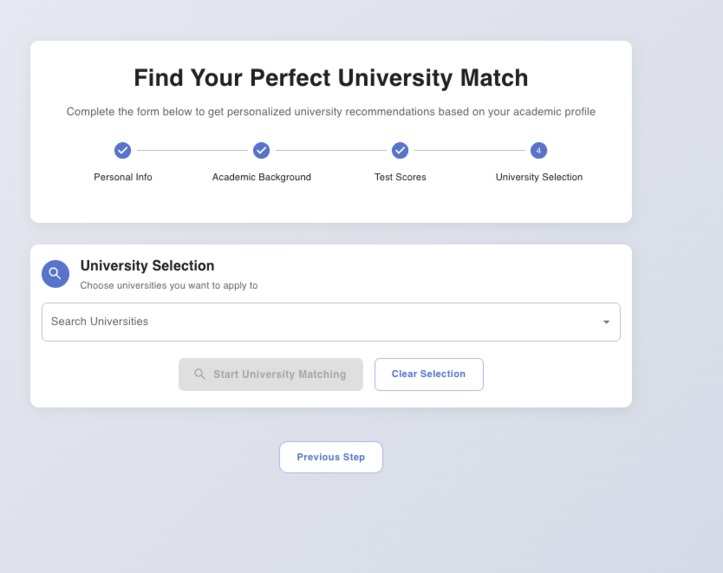
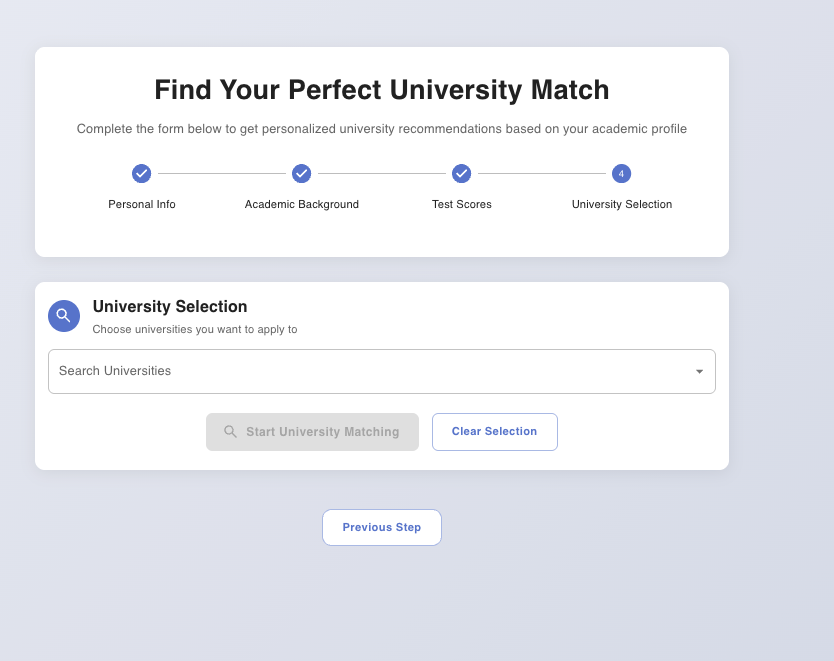
We can select different university
-
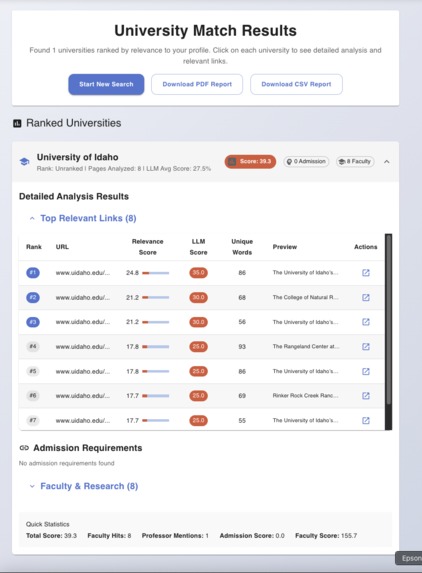
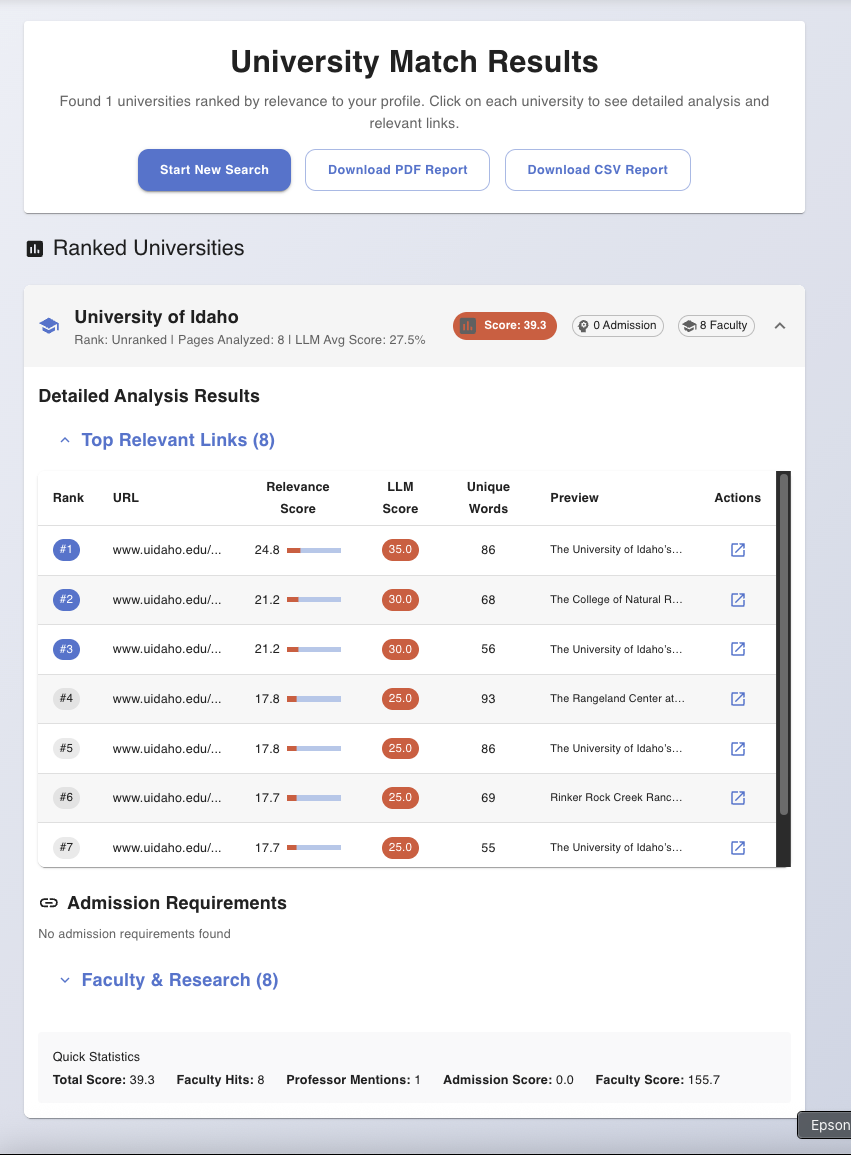
For selected university see the top faculty and professor links which is match the profile of the student most
-
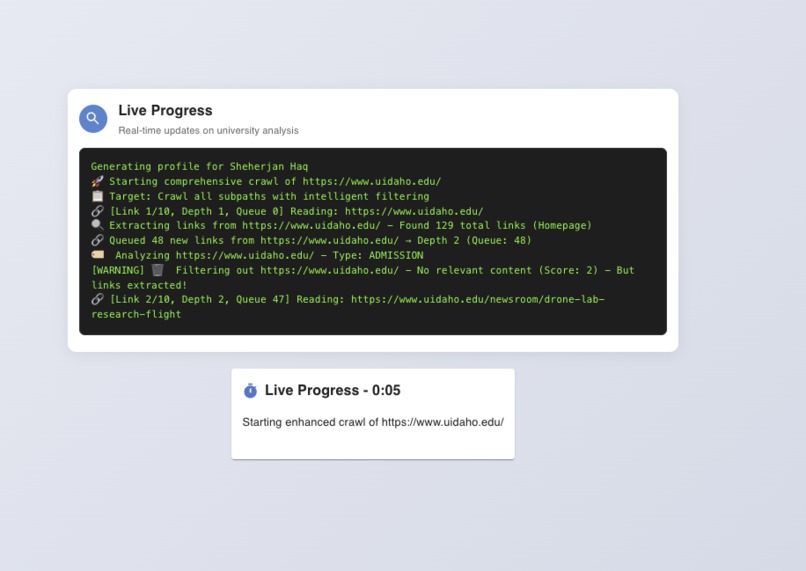
With each university subpath we match with that with profile and try to score which is top links for this profile.
CampusCompass: A Deep Research For Personalized University and Professor Search
I’m an international student. When I started searching for graduate programs, it felt like navigating a maze with moving walls: different grading scales, shifting admission requirements, outdated pages, inconsistent program names, and the hardest part—finding professors whose work truly aligned with my interests. I watched friends struggle too: days lost to manual Googling, confusion over prerequisites, and uncertainty about whether they were competitive for a program. Everyone’s interests and profile are different; a generic list of “top schools” is not helpful. CampusCompass grew from that frustration: a tool to turn scattered university sites into an explainable, personalized shortlist.
Motivation
- Personal pain: Hours of research to answer basic questions—Do I qualify? Is this professor a fit? Is funding realistic?
- Diversity of profiles: Different GPAs, research areas, test scores, budgets, and constraints (location, visa timelines) demand personalized results.
- Web reality: Requirements live across multiple pages, PDFs, and faculty profiles; they change often and are rarely standardized.
- Fairness and confidence: I wanted something that didn’t just rank, but explained why—so students can apply smarter, not just “more.”
What I Built
CampusCompass is an AI-assisted university matcher:
- Crawls official program pages and faculty profiles to gather current requirements and research themes.
- Scores universities against a student profile (interests, background, constraints) and explains the “why” behind each match.
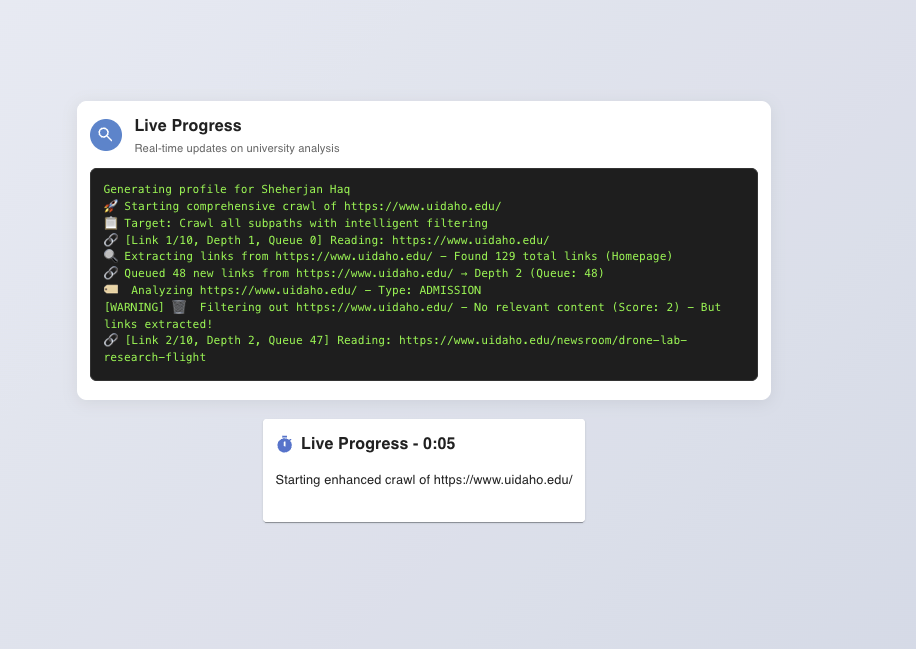
- Streams progress so you can see what’s being crawled and analyzed in real time.
- Produces a CSV and a readable report summarizing matches, fit reasons, and next steps.
Tech stack:
- Frontend: React + Material UI for fast iteration and a clean, responsive UI.
- Backend: Django + DRF to orchestrate crawling, analysis, and reporting.
- Intelligence: A lightweight crawler plus an LLM (via Ollama) to interpret messy web content when possible, with a fallback to robust keyword heuristics.
How It Works (High Level)
- Crawl strategy: A layered BFS across each university domain with depth and page caps, filtering out noisy or irrelevant pages.
- Content prep: HTML is normalized; links and headings are retained as clues. PDFs (when supported) are parsed with structural cues.
- Relevance extraction: The system extracts segments about requirements (GPA, tests, prerequisites), research areas, and faculty matches.
- Dual scoring: Combines requirement fit with content relevance and professor alignment.
A simplified scoring sketch:
$$ \text{score}(u \mid p) \;=\; \sum_{\text{page} \in u} \Big( \alpha C_{\text{relevance}} \;+\; \beta N_{\text{novelty}} \;+\; \gamma M_{\text{prof}} \Big) \;+\; \delta R_{\text{requirements}} \;-\; \lambda P_{\text{noise}} $$
Where:
- \(C_{\mathrm{relevance}}\): how well content matches interests/keywords
- \(N_{\mathrm{novelty}}\): penalizes duplicates, rewards unique info
- \(M_{\mathrm{prof}}\): alignment with faculty research themes
- \(R_{\mathrm{requirements}}\): fit to GPA/tests/prereqs
- \(P_{\mathrm{noise}}\): penalties for low-quality or irrelevant pages
Example normalization for GPA (different scales):
$$ g_{\mathrm{norm}} \;=\; \frac{g_{\mathrm{current}}}{g_{\mathrm{max}}} $$
This feeds into \(R_{\mathrm{requirements}}\) alongside test scores, prerequisites, and language requirements. Finally, universities are ranked by \(\mathrm{score}(u \mid p)\) and presented with explanations referencing the exact pages/segments used.
What I Learned
- Web reality beats theory: Real university websites are inconsistent; robust parsing and smart fallbacks matter more than perfect NLP.
- Explainability earns trust: Users don’t want a black-box “rank”—they want highlighted evidence and clear reasons.
- Constraint design: Depth limits, politeness (rate limiting), and deduplication dramatically improve signal-to-noise.
- Model pragmatism: Local LLMs help, but deterministic heuristics are essential for speed, stability, and cost control.
- International nuances: GPA scales, name variations for programs, and language requirements need explicit handling to avoid excluding good fits.
Challenges
- Dynamic content and PDFs: Many requirements hide in PDFs or JS-rendered pages; extraction must be resilient.
- Evolving pages: Requirements change; the system needs to re-crawl selectively and cache with freshness checks.
- Anti-bot measures: Respectful crawling policies and backoff logic are critical.
- Ambiguous synonyms: “Data Science,” “Analytics,” and “Informatics” can mean different things—disambiguation is context-heavy.
- Professor alignment: Research interests span multiple labs; mapping profiles to current publications is non-trivial.
Impact
- Saves time: Converts weeks of scattered searching into an afternoon of focused review.
- Boosts confidence: Transparent reasons and links let students verify before applying.
- Supports diversity: Personalized matches respect unique constraints—budget, geography, prerequisites, and interests.
Future Directions
- Faculty graph: Map labs, co-authorships, and recent publications for richer professor matching.
- Budget and funding layer: Scholarships, assistantships, and cost-of-living filters integrated into ranking.
- Outcome calibration: Incorporate acceptance data where ethically available and compliant, to improve guidance.
- Profile-aware synonyms: Learn a user’s vocabulary and map it to program-specific terminology.
- Application readiness: Auto-generate checklists, email templates, and prerequisite gap analysis.
Closing
CampusCompass was born from my experience—and my friends’—as international students struggling with opaque, inconsistent information. The goal isn’t to replace judgment; it’s to empower it with evidence. If it helps even one student find a program and professor who truly fit their profile, it’s worth it.


Log in or sign up for Devpost to join the conversation.