-
-
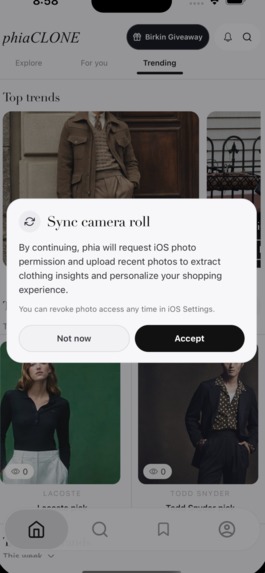
Sync camera roll (0 friction)
-
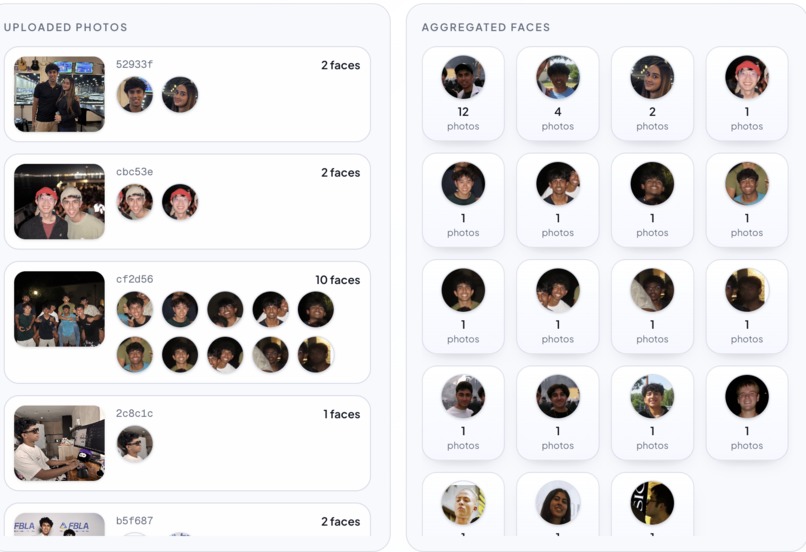
Facial Recognition
-
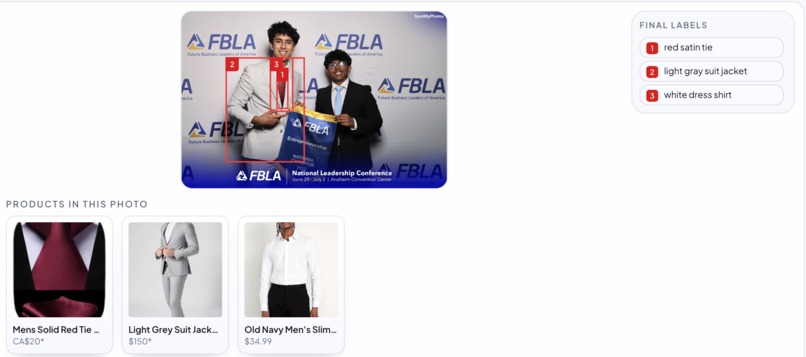
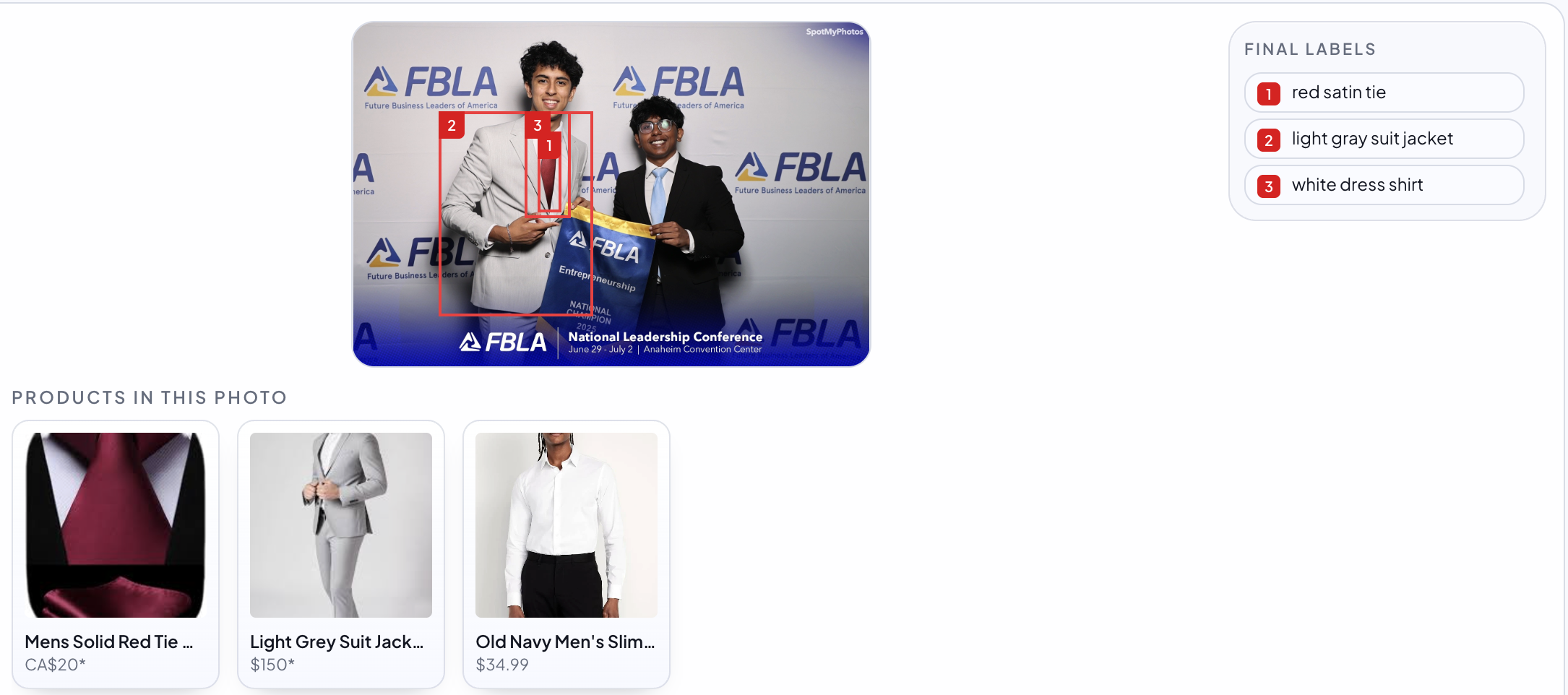
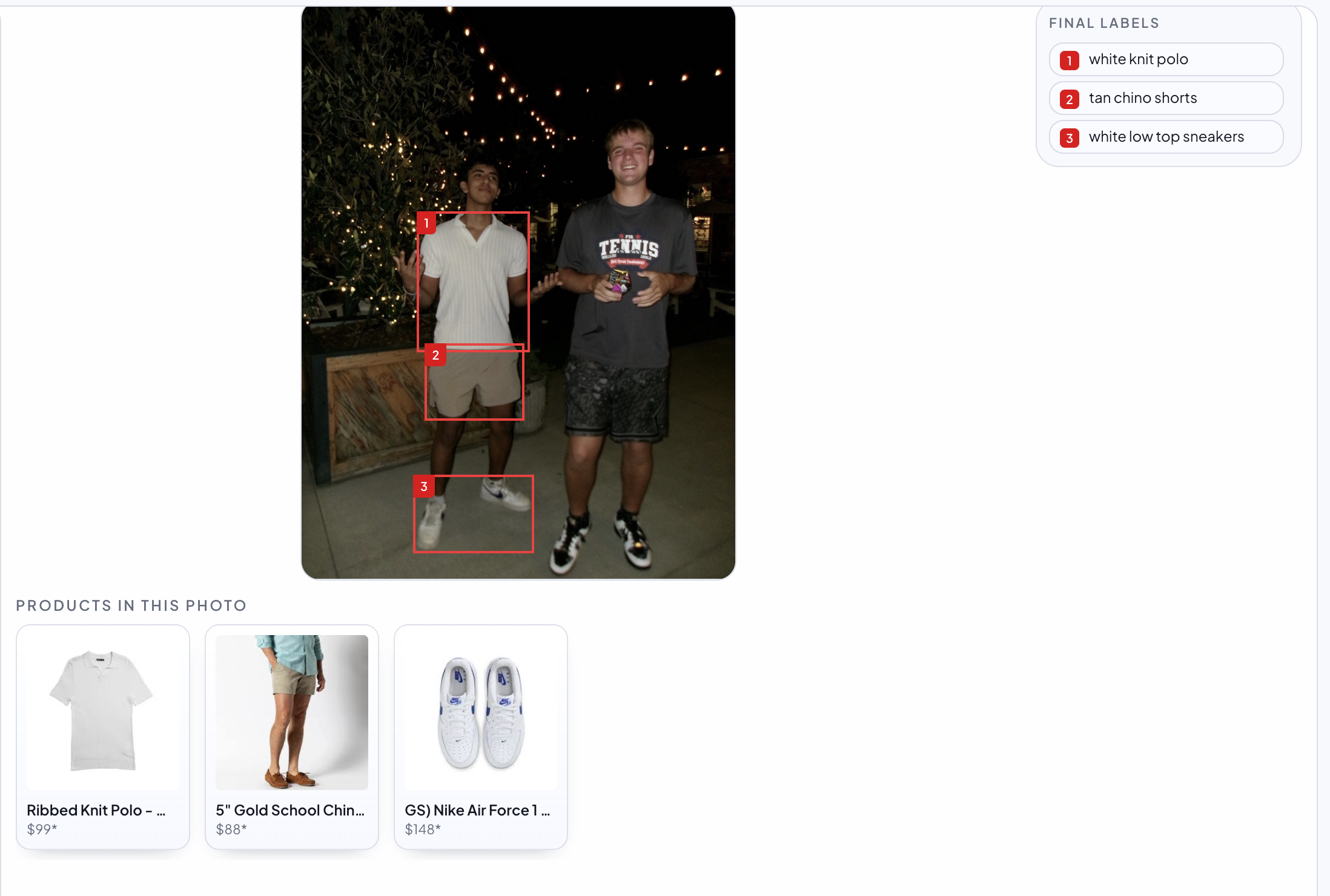
Item Segmentation and Lookup
-
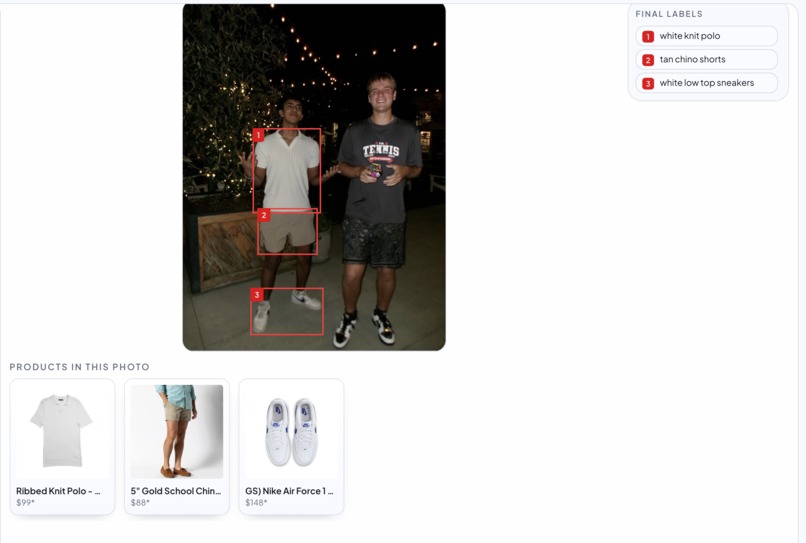
Built to handle every type of photo
-
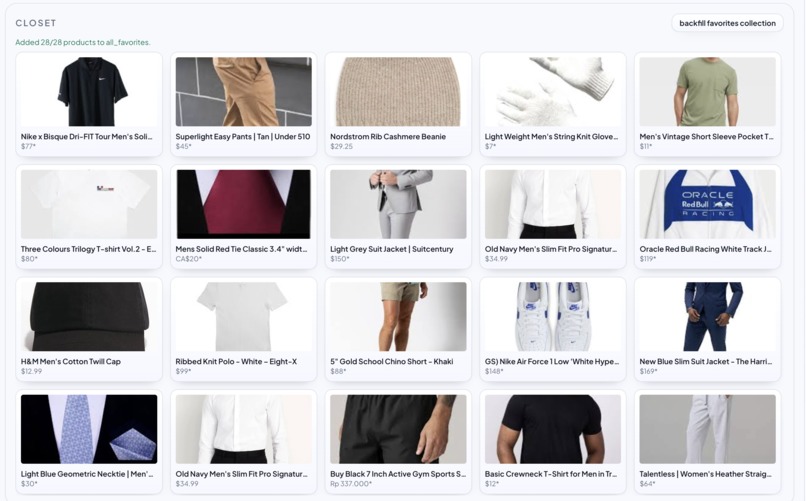
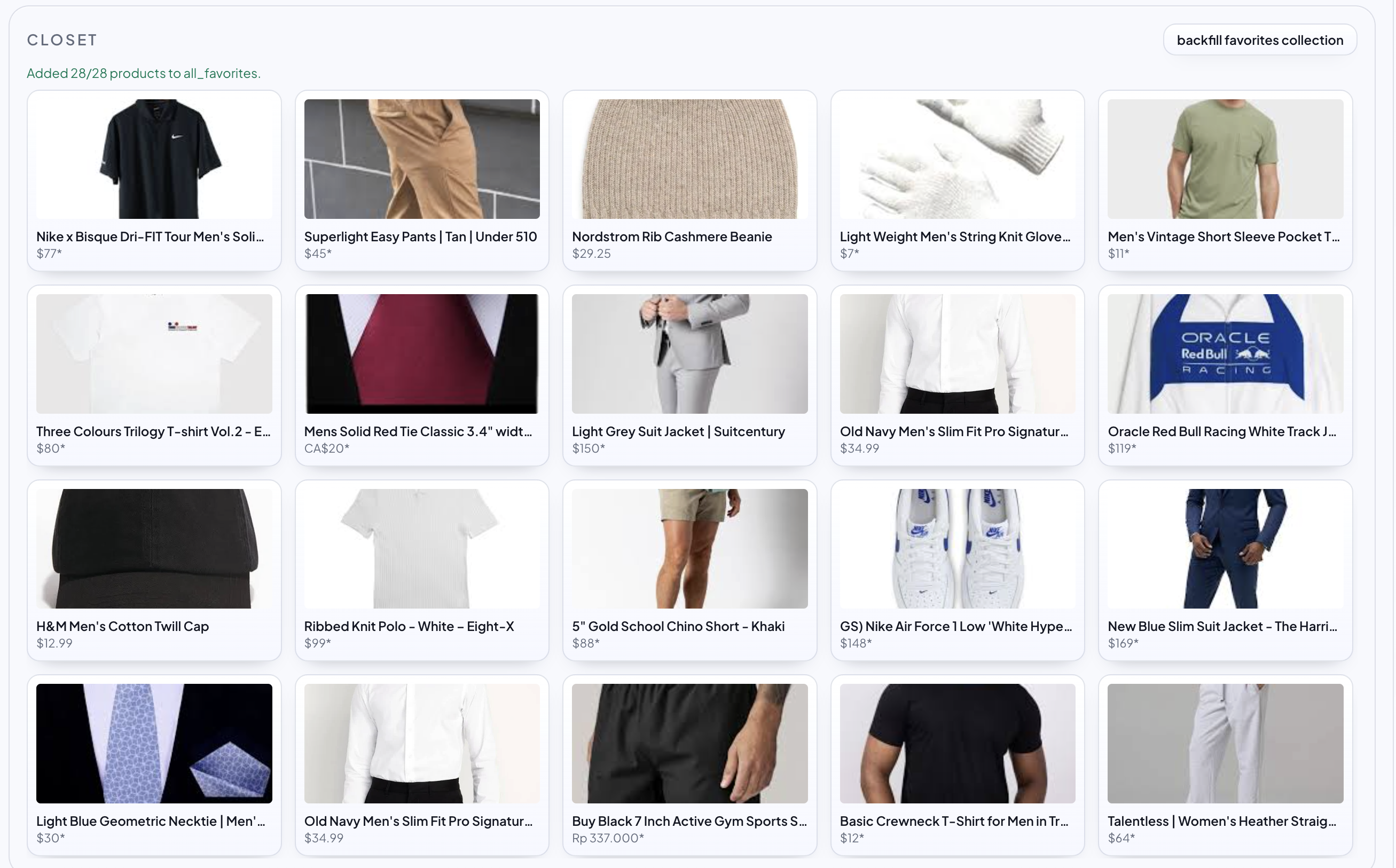
Full closet of items
-
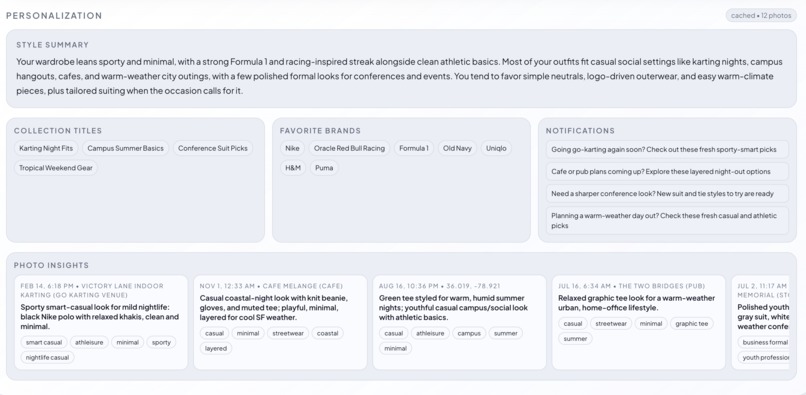
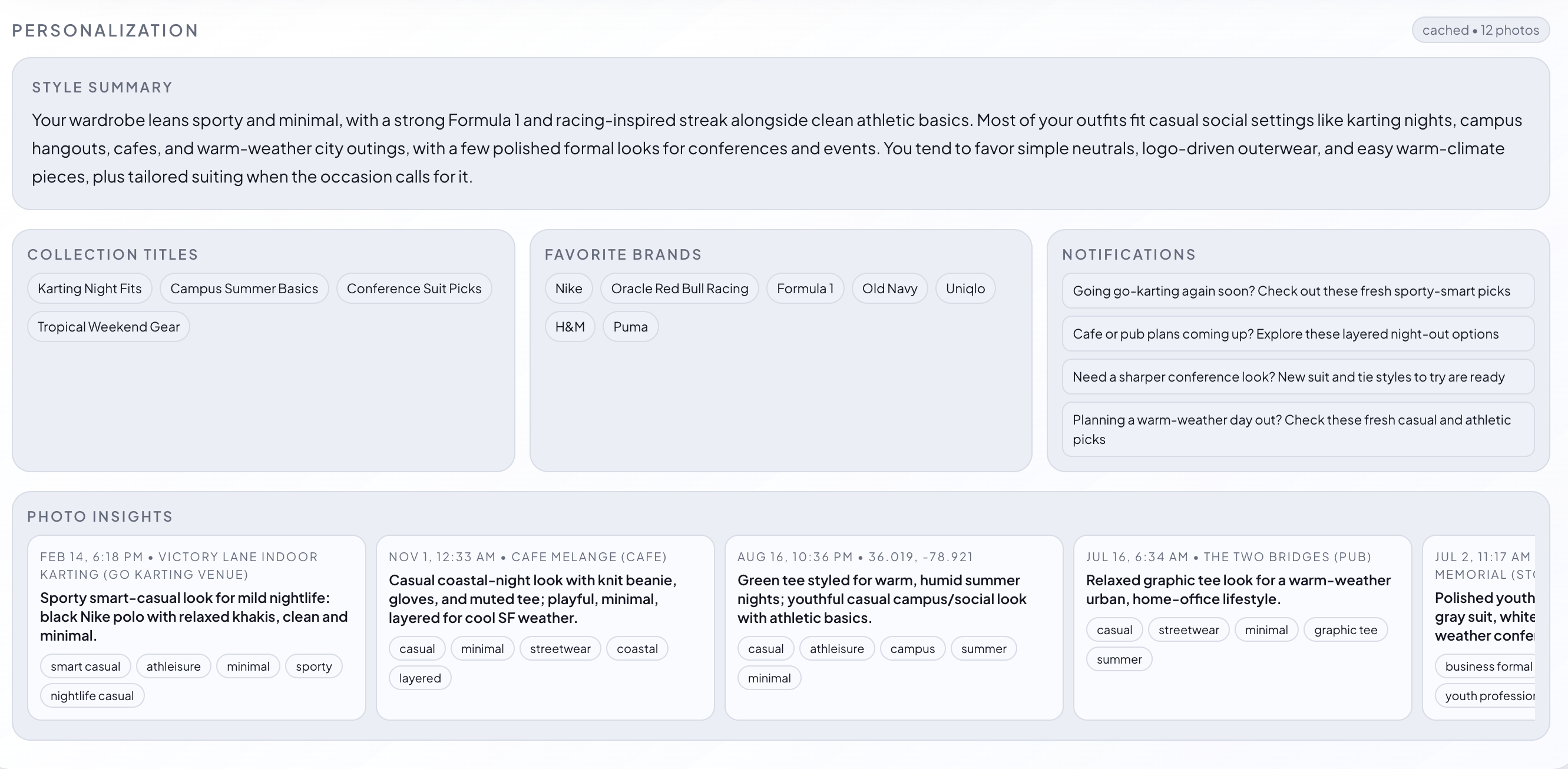
Personalization Output
-

AI generated product image
-

AI generated product image
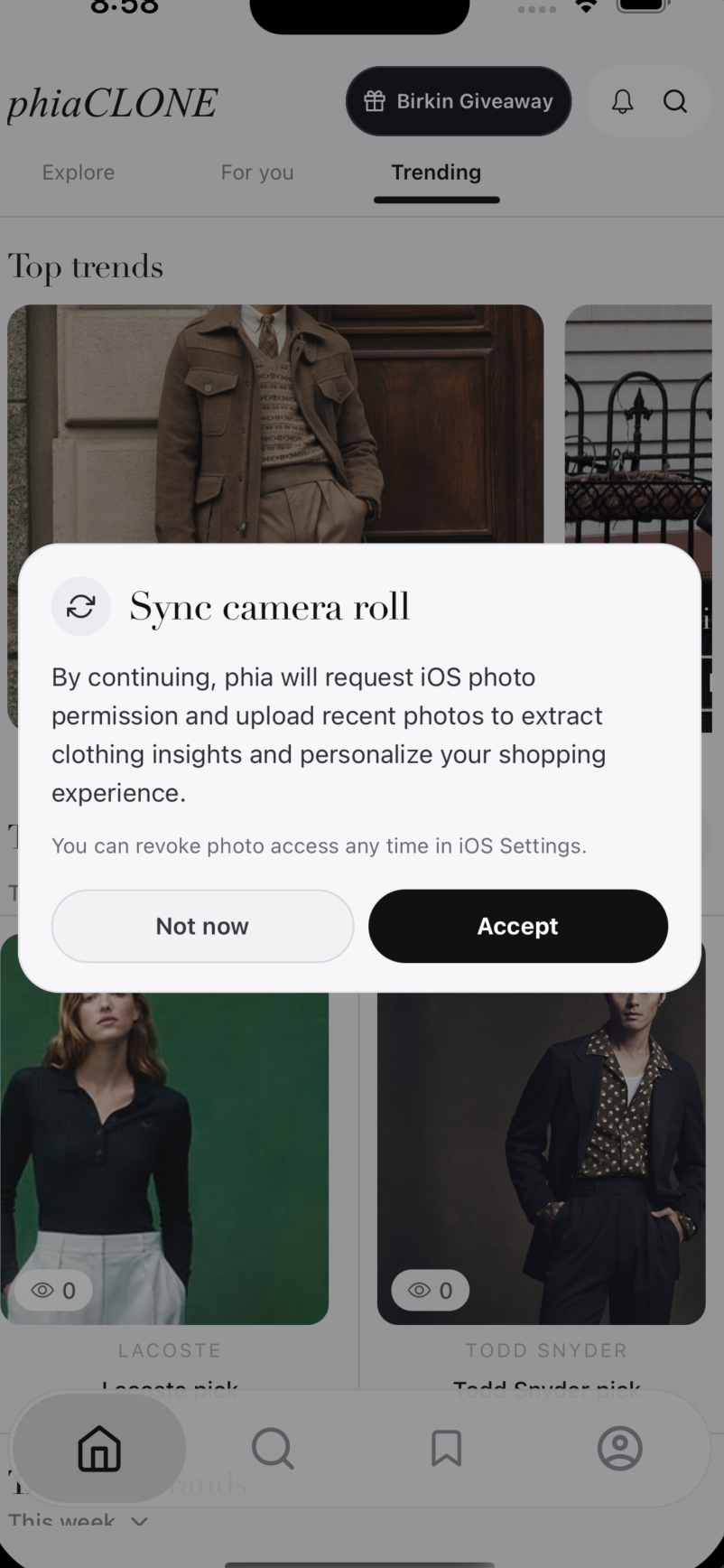
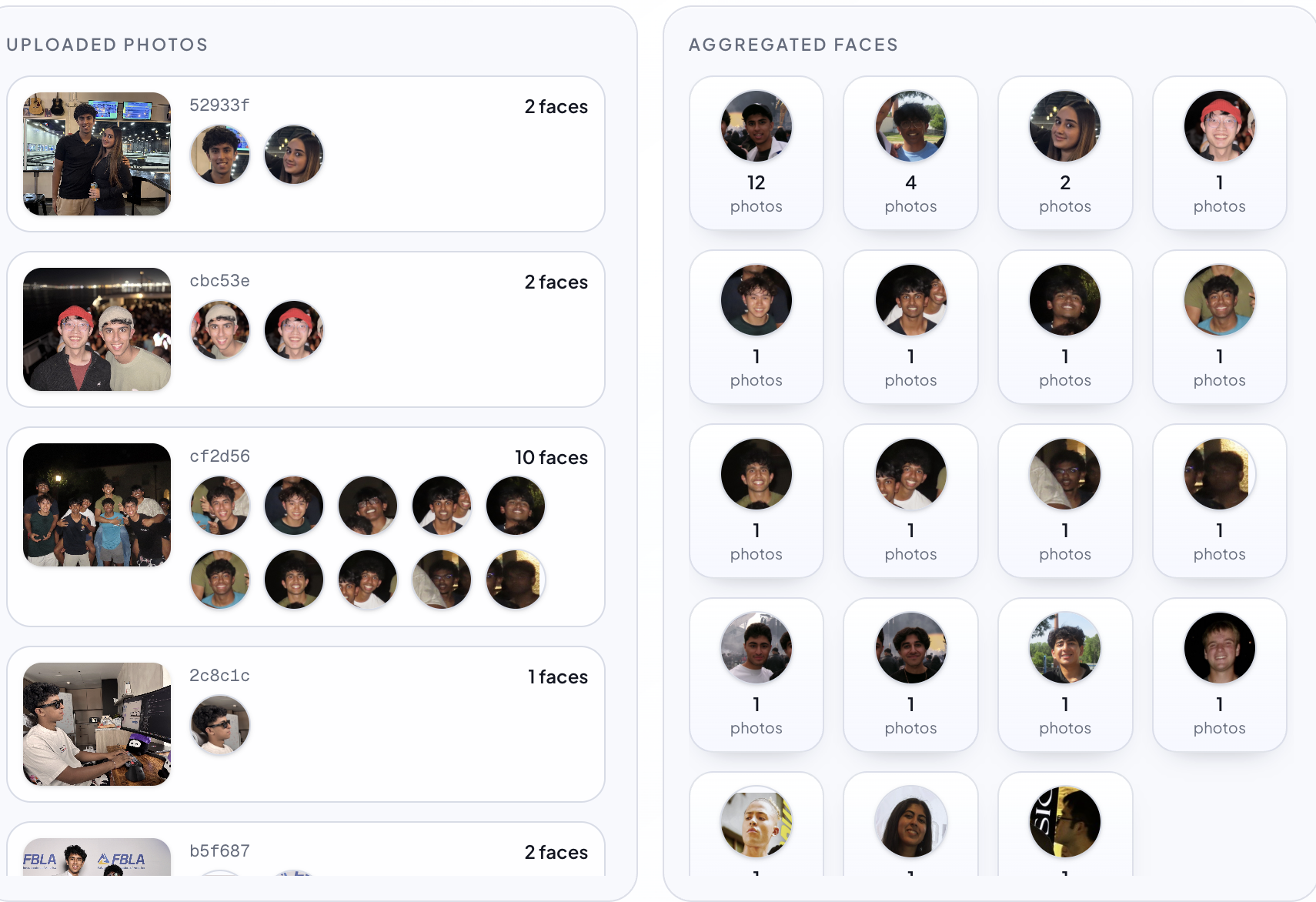


The Issue
There's a major cold-start issue with personalization. The first few times Phia is used (the most critical moments for retention), Phia almost knows nothing about the user. Conventional onboarding methods of making the user answer questions or swipe left/right on images only adds more friction, boosting dropoff.
Solution: Camera Roll Ingestion
The user simply has to accept one permission to give us access to their entire wardrobe. Every photo is rich with not only clothing items, but location and contextual data that helps our systems understand the user.
How we built it
The ingestion system is built on a FastAPI backend, utilizing several technologies:
- AWS Rekognition for face extraction and indexing
- GPT-5.4 for contextual analysis, labeling, and evaluation
- YOLO-world for item localization
- SerpApi for Google Lens
- Google Places API for location analysis
LLM generation of item classes from target --> YOLO-world item localization --> LLM post-process and cleanup --> each crop with description fed into SerpApi
Image generation has 2 implementations:
- FLUX.1-dev with Low-rank adaption(LoRA) finetuning
- Gemini Nano-Banana
The web app was built using Next.js and the Phia mobile clone was built with react native and Expo.
Challenges we ran into
- GPT-5 and other LLMs are extremely innacurate with item localization tasks
- Google Lens struggles to return accurate products when multiple items are in the same segment
- LoRA finetuning is time-intensive, but feasible with more resources
What's next
- Integration within Phia systems for a full personalization engine with experiments
- Scalable deployment of LoRA finetuning on user photos for product image generation
- Evaluation framework for camera roll ingestion
- Analysis of data privacy requirements
Built With
- amazon-web-services
- expo.io
- next.js
- react
- react-native
- replicate
- serp


Log in or sign up for Devpost to join the conversation.