-
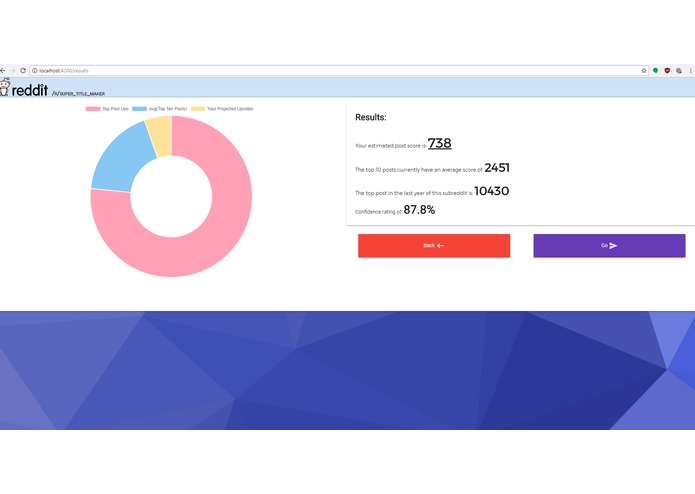
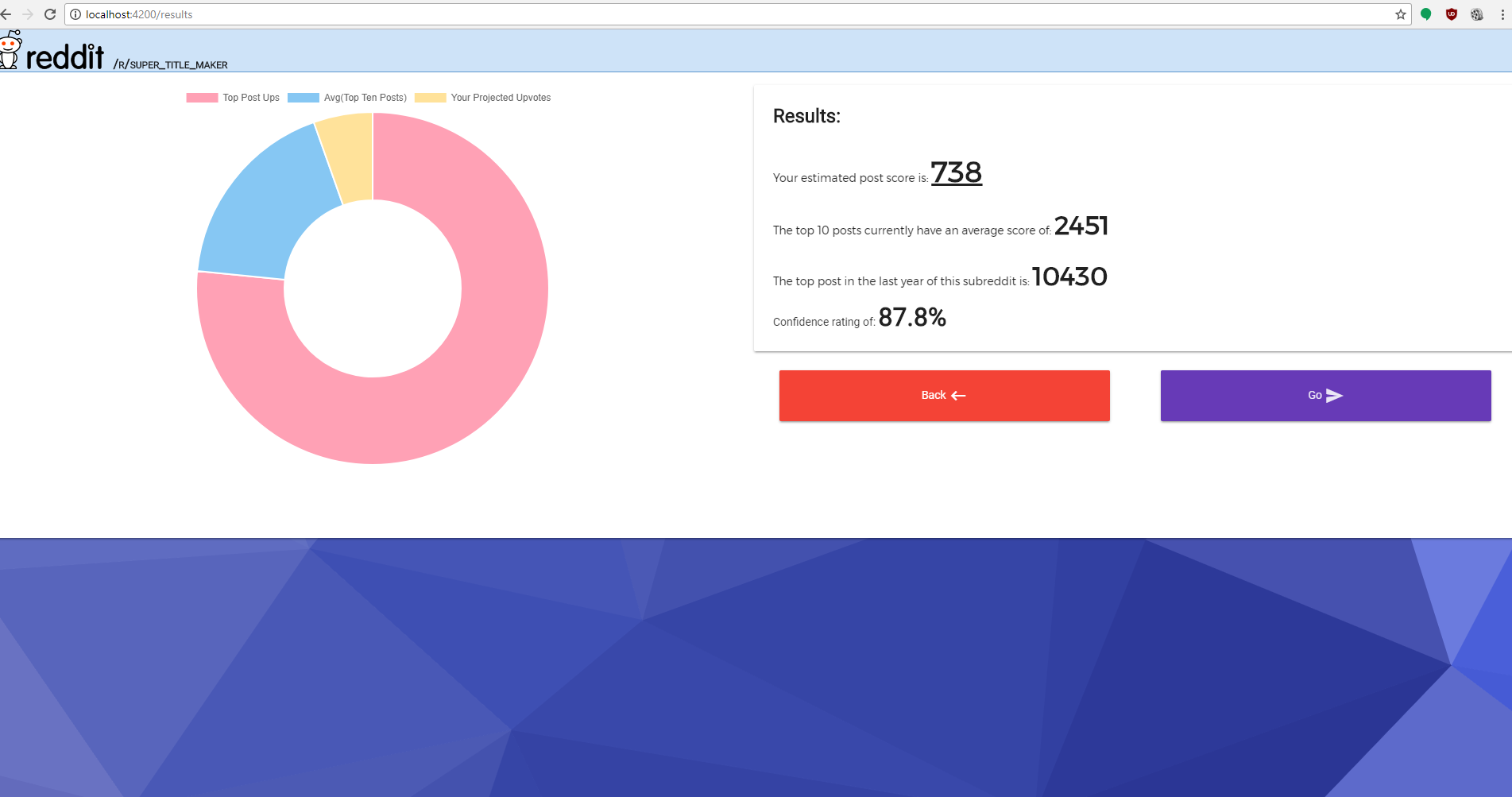
Data dashboard in action.
Inspiration
Larry was the leading-idea guy behind the vision of Calzone. Little did the team members know what a fateful meeting they would have as they randomly met in the team-formation session in the ITE building.
As a passionate writer, Larry was seeking the mystery of gaining visibility and engagement on some of his blog posts. After months of seeing mediocre articles routinely make it to the top of the subreddits he frequented, Larry realized there must be a secret formula to taking over the world of Reddit.
In that moment, the vision behind Calzone was conceived.
What it does
The proprietary software behind Calzone parses through hundreds of thousands of data points, detects subtle patterns in the language formation, and assigns an informed projection to the user. From this data, the user can then gain an educated expectation of how well the post will perform.
How we built it
We built our data set by sending thousands of API requests to the official Reddit server. After collecting sufficient data, our Machine Learning experts developed a powerful data model for training our software.
As our Machine Learning algorithm was developed by the back-end team, we had our front-end team build a prototype with the @Angular/CLI package for the front-end of our web app.
As both sides of the stack were developed, the teams gradually integrated their work with one another.
Ultimately, the dream was realized, and the product was born.
Challenges we ran into
As always, during the development process, requirements evolved, and tasks that were initially thought of as trivial quickly ballooned into challenges that took several hours longer than anticipated.
The linear regression model originally planned for the data model did not produce results standard for a high quality project. It took several attempts and multiple revisions to settle the data model in a satisfactory model.
Scraping the data from the Reddit API was also a unique challenge. With the sheer amount of data needed for an accurate data model, collection efficiency quickly became an issue. Eventually, we found that the balance between managing buffer memory and dynamically building the dataset was best done through direct python calls to a database server.
Accomplishments that we're proud of
- Accomplishing meaningful data analysis through machine learning techniques.
- Aggregating a massive data set in a relatively short period of time.
- Building a presentable web interface that is both user-friendly and informative.
- Cohesive teamwork and project responsibility management.
- Quickly adapting team synergy with development of roles across the workload.
What we learned
We all have unique abilities, and are most productive when we do what we're best at and communicate amongst ourselves.
What's next for Calzone
We're planning on our IPO launching at a valuation of $400 billion dollars by the next fiscal quarter.
Built With
- adobe-experience-design
- amazon-web-services
- angular.js
- charts.js
- css3
- flask
- git
- google-material
- html5
- javascript
- machine-learning
- natural-language-processing
- nginx
- node.js
- python
- slack
- sqlite
- typescript


Log in or sign up for Devpost to join the conversation.