-
-
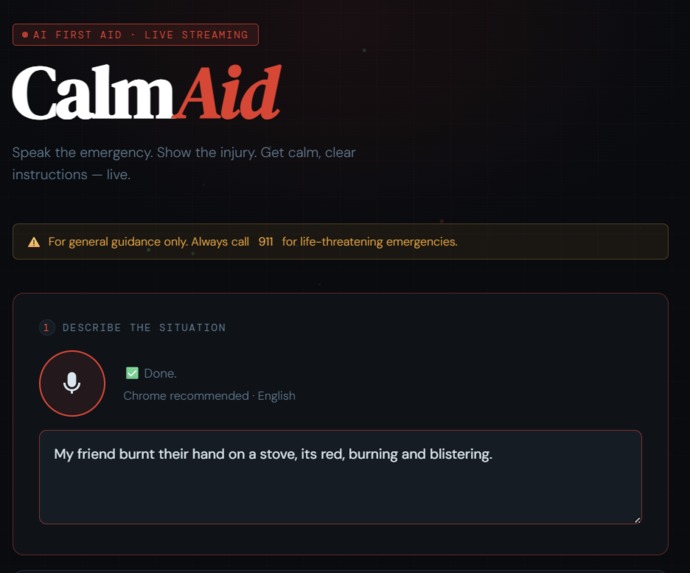
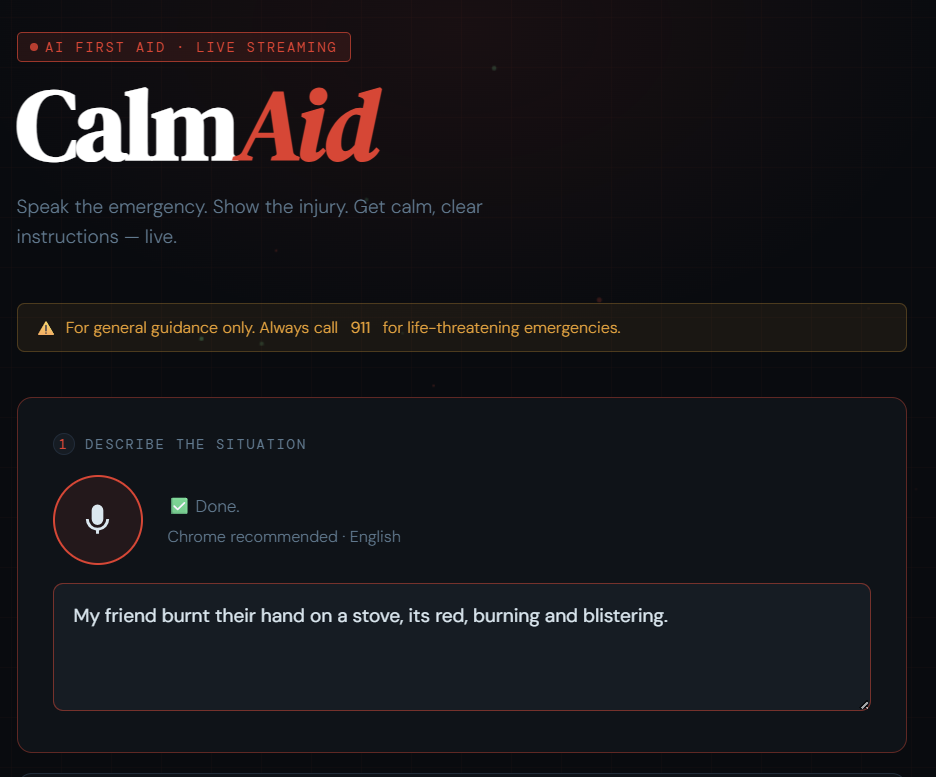
Input Stream
-
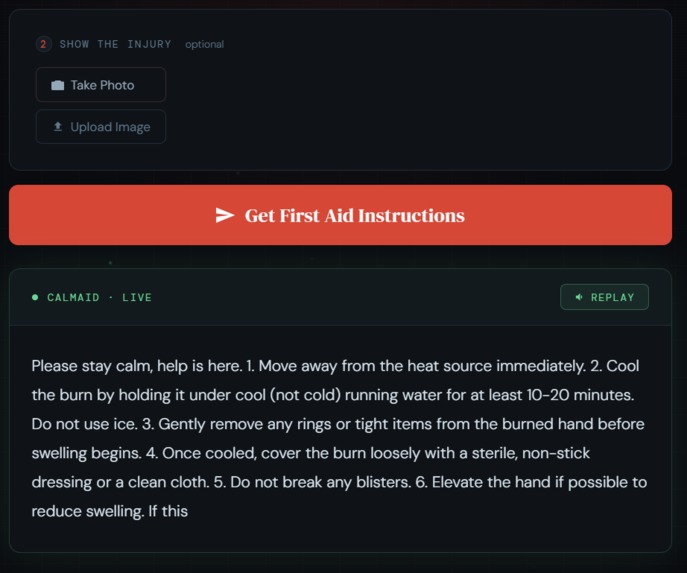
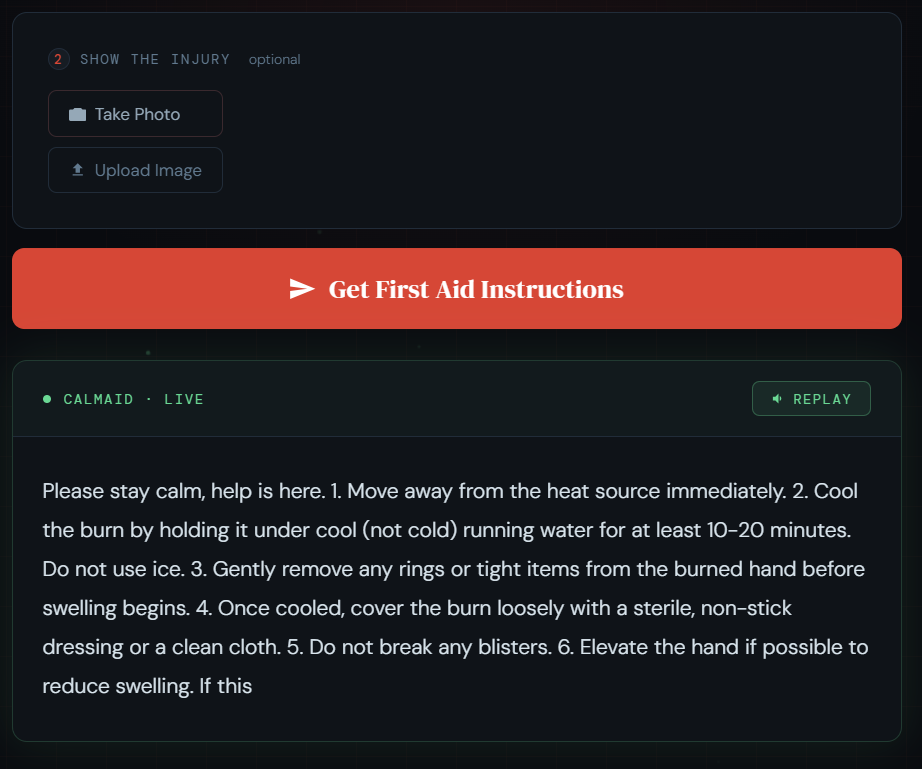
Output Stream
Inspiration
In an emergency, people panic. They fumble with Google, read walls of text, and waste critical seconds. We asked ourselves — what if your phone could just tell you what to do, calmly, the moment something goes wrong? First aid knowledge exists everywhere, but accessible, real-time guidance in a crisis does not. CalmAid was born from that gap.
What it does
CalmAid is a multimodal AI first aid agent that sees, hears, and speaks in real time. You describe your emergency by voice, optionally show the injury via camera, and CalmAid streams back calm, numbered first aid instructions — word by word — while simultaneously reading them aloud before the full response even finishes. No typing. No searching. No waiting.
How we built it
The frontend is a custom HTML/CSS/JS interface with GSAP animations — no frameworks, just fast and clean. The backend is a FastAPI app deployed on Google Cloud Run that calls Gemini 2.5 Flash via the Google GenAI SDK with streaming enabled. Responses flow back as Server-Sent Events, rendering word-by-word on screen while a TTS sentence queue speaks each sentence the moment it arrives. The API key is stored securely in Google Secret Manager and injected at runtime. The whole thing is containerized with Docker and built via Cloud Build.
Challenges we ran into
- SSE buffer management — incomplete JSON lines arrive mid-chunk and must be held across read cycles without dropping data
- Live TTS timing — speaking word-by-word sounds robotic, speaking the full response feels slow; sentence-boundary detection was the sweet spot
- Python 3.13 compatibility — several pinned packages (Pillow, pydantic) didn't have prebuilt wheels for 3.13 and required version bumps
- SDK migration — the
google-generativeaipackage is deprecated and streaming was broken; migrating togoogle-genaifixed it entirely - Quota limits — free tier rate limits required careful project management during testing
Accomplishments that we're proud of
- The agent genuinely feels live — text streams in and voice starts speaking within ~1 second of hitting submit, mid-generation
- A complete multimodal pipeline: voice in → vision + text → streaming text out → live TTS, all working end-to-end
- Production-grade deployment with Secret Manager, Cloud Build, and Cloud Run — not just a localhost demo
- A safety-first system prompt that handles real emergencies responsibly without over-engineering
What we learned
- Streaming LLM responses via SSE requires careful buffer management on both the server and client side
- Browser-native Web Speech API and Speech Synthesis are surprisingly capable for a hackathon — zero dependencies, zero latency
python:3.11-alpinedramatically reduces Docker image vulnerabilities compared toslim- Google Cloud Run's
--set-secretsflag with Secret Manager is the cleanest production pattern for API key handling - The new
google-genaiSDK is significantly more reliable for streaming than the deprecatedgoogle-generativeai
What's next for Calm Aid
- Interruption handling — let users speak mid-response to redirect or ask follow-up questions
- Multilingual support — switch voice input and output language based on user preference
- Offline mode — cache common first aid responses for emergencies with no connectivity
- Wearable integration — trigger CalmAid hands-free via smartwatch tap
- Professional escalation — one-tap 911 call with auto-generated situation summary sent to dispatch
Built With
- css3
- docker
- fastapi
- gemini-2.5-flash
- google-cloud-build
- google-cloud-run
- google-genai-sdk
- google-secret-manager
- gsap
- html5
- javascript
- pillow
- python
- server-sent-events
- uvicorn
- web-speech-api



Log in or sign up for Devpost to join the conversation.