-
-
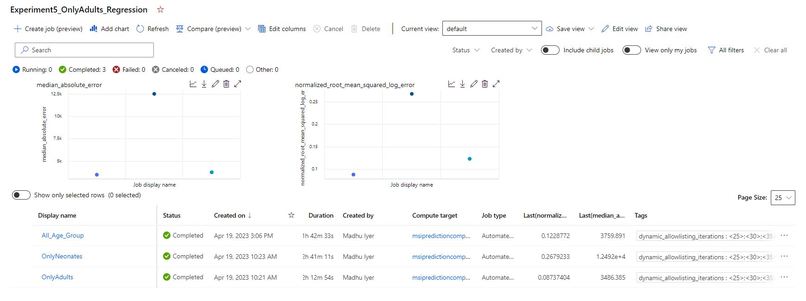
ML Jobs
-
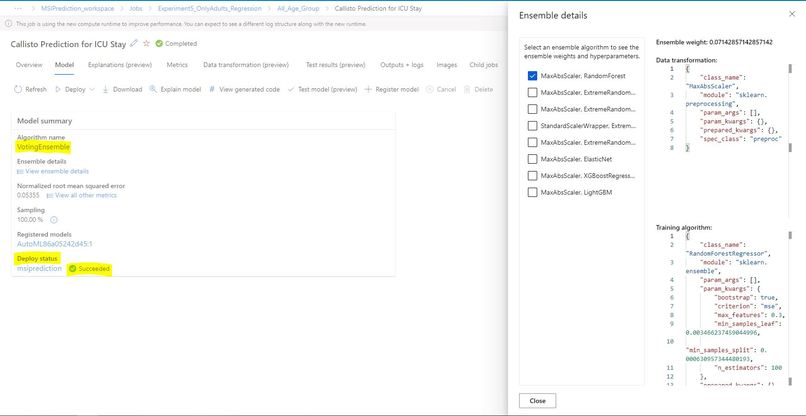
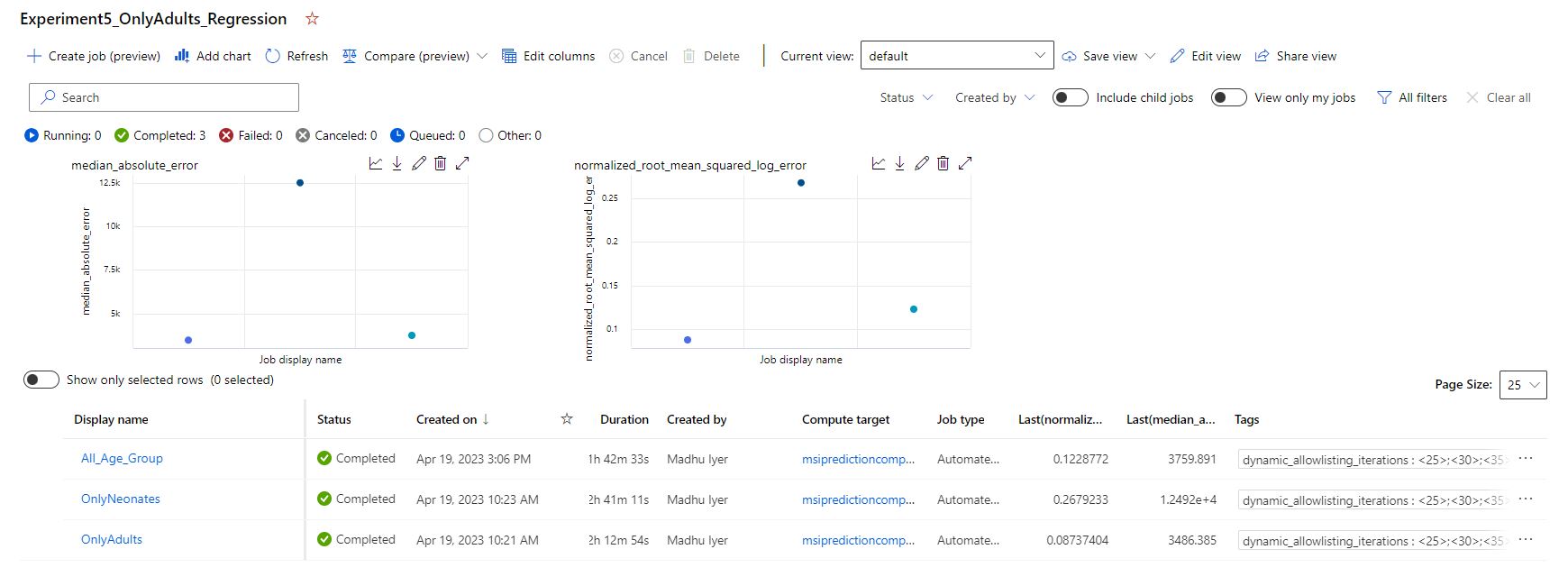
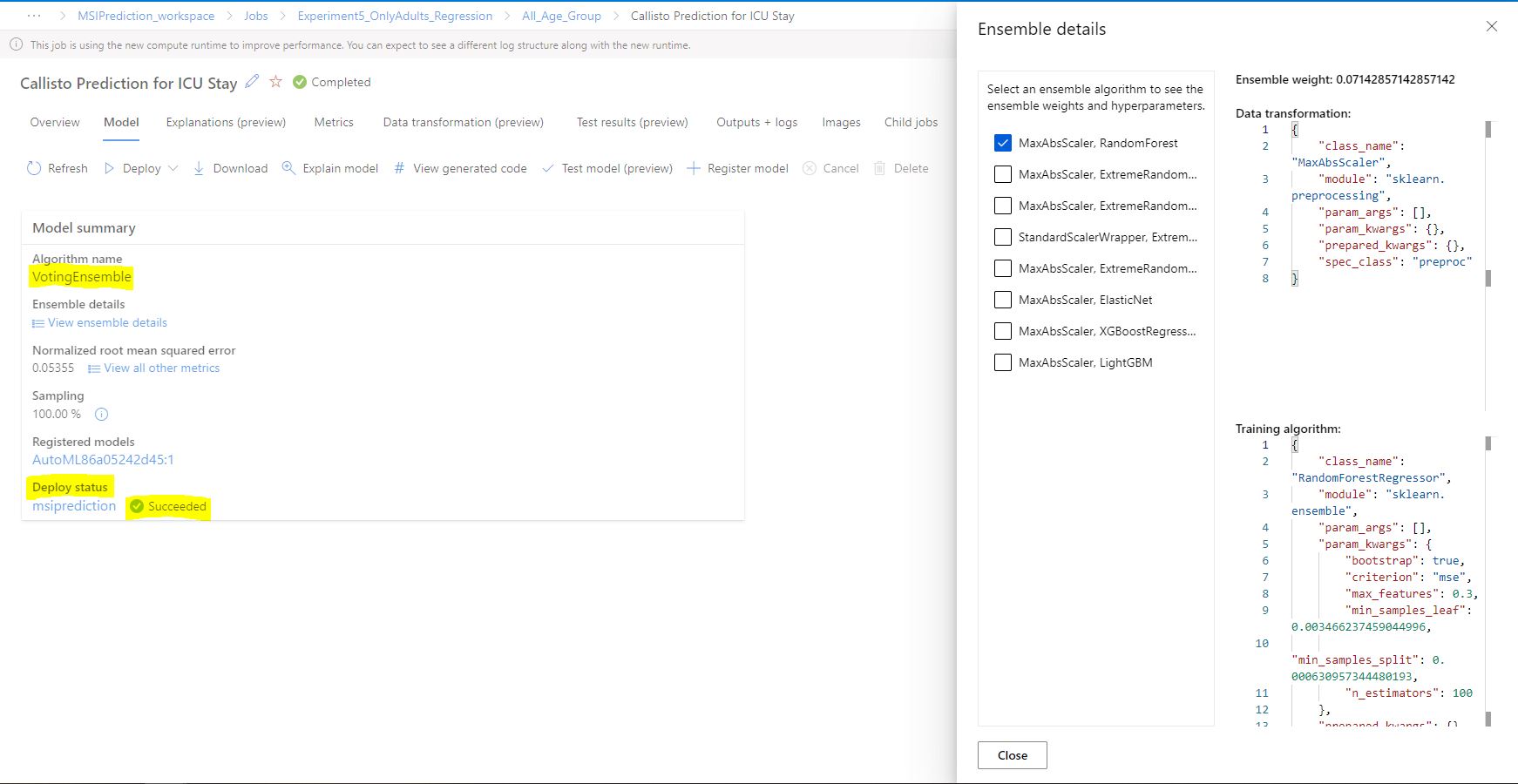
Models Evaluated in Voting Ensemble
-
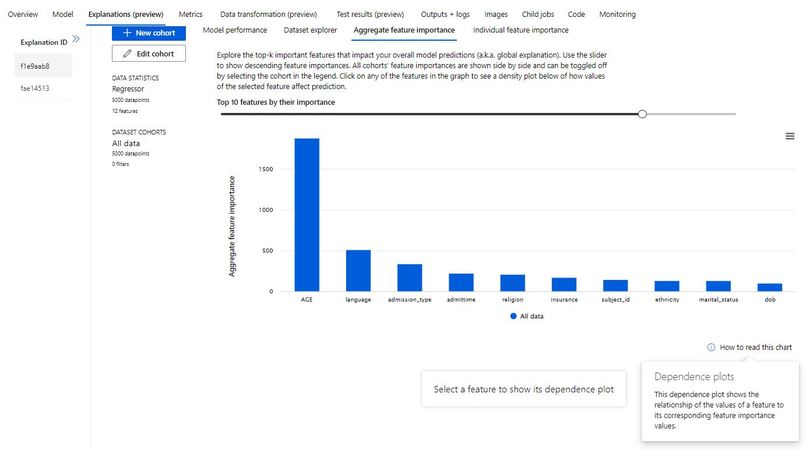
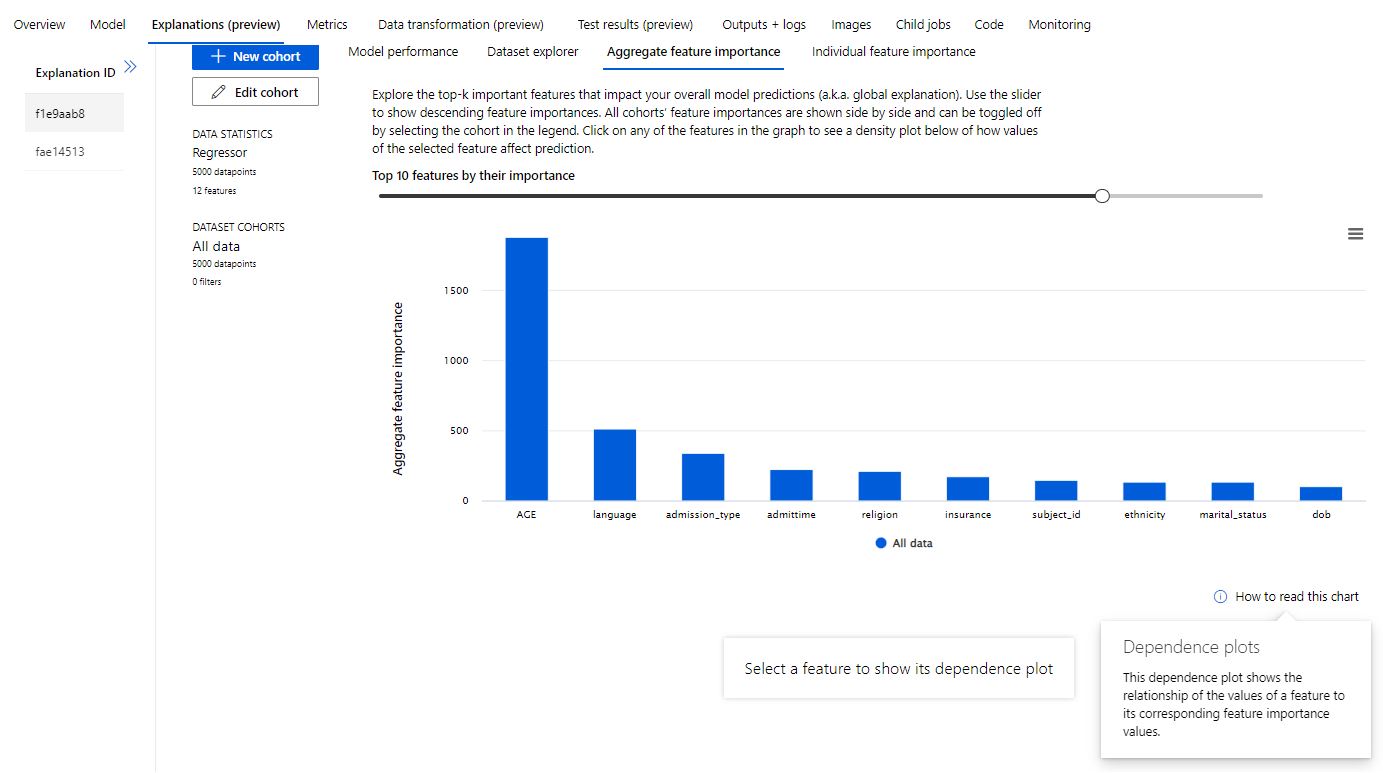
Feature Importance
-
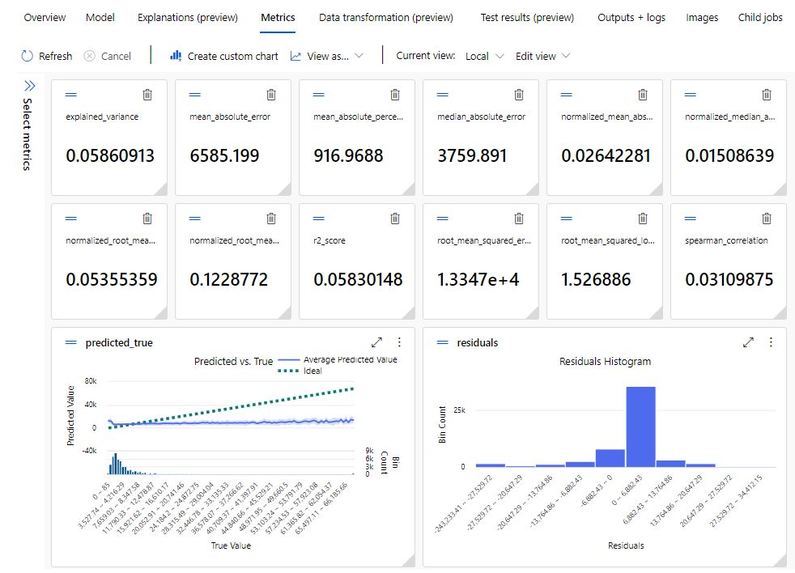
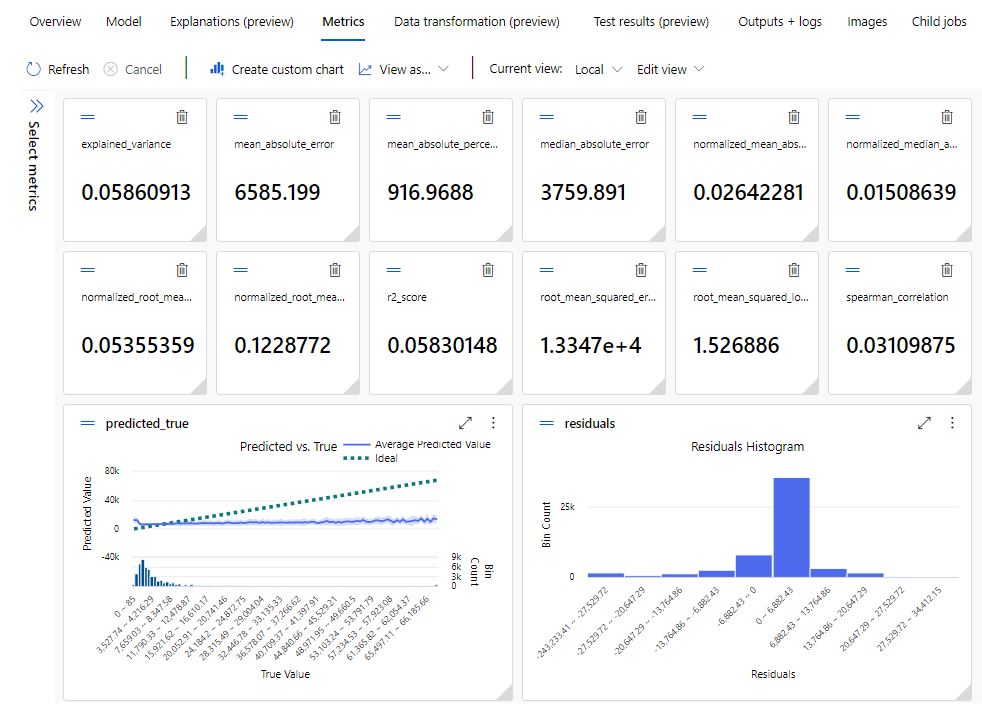
Metrics
-
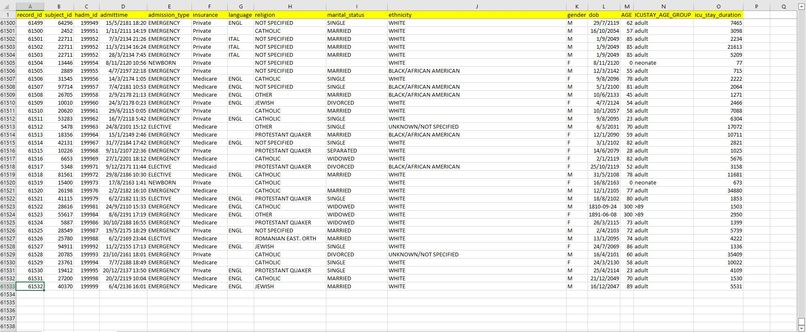
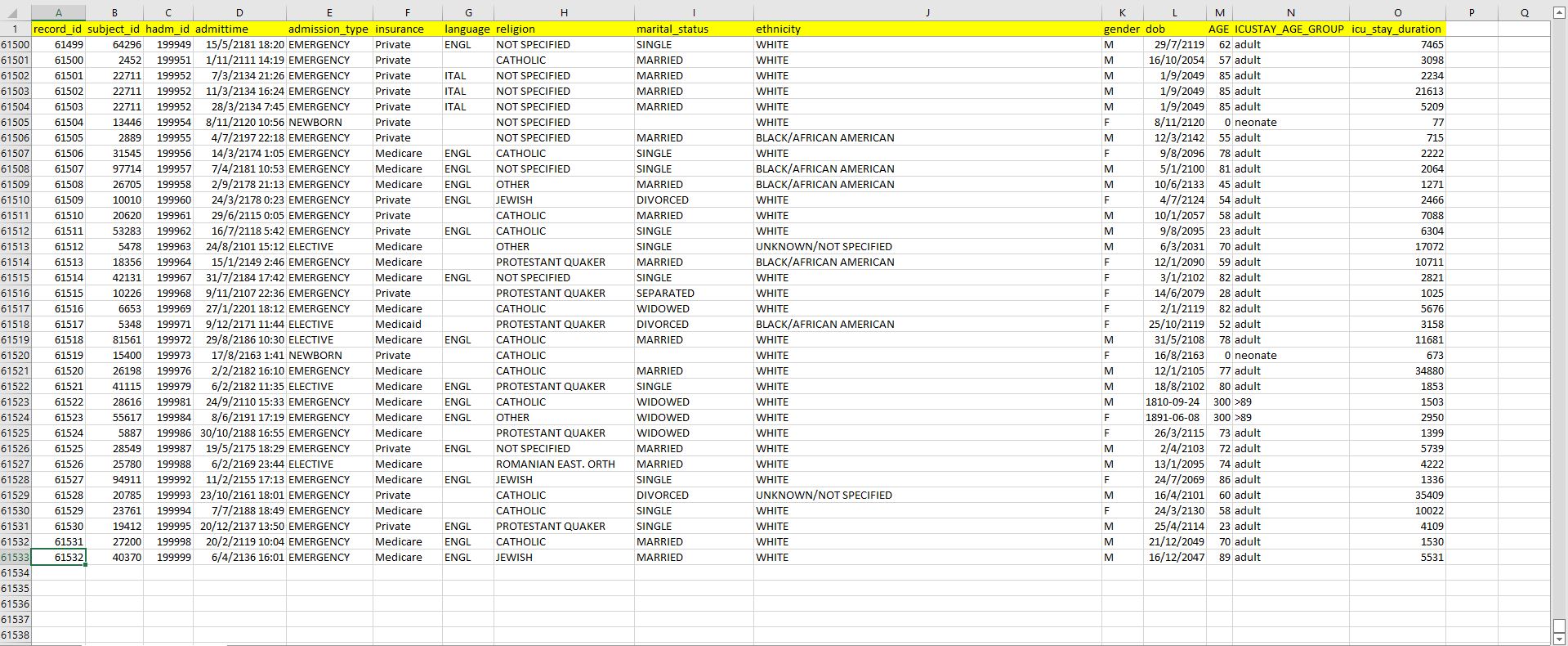
Dataset Sample
Problem Statement
Johnson & Johnson - Problem Statement 1
Predicting Length of Stay in ICU using MIMIC-III Dataset
Inspiration
The inspiration for designing a prediction model on ICU length of stay (LOS) comes from the need to improve patient care and clinical outcomes while also optimizing the utilization of limited healthcare resources. In particular, this prediction models can be used to help clinicians make informed decisions about patient care, such as deciding when to transfer a patient out of the ICU or when to discharge them from the hospital.
With accurate predictions of patient length of stay, hospitals can optimize the use of limited resources (such as ICU bed availability and staffing), reduce costs, and improve the overall quality of care. It can be used to improve patient outcomes by facilitating timely interventions and reducing the risk of complications associated with prolonged ICU stays.
Overall, the goal of designing an ICU LOS prediction model is to improve patient outcomes and resource utilization, leading to more efficient and effective healthcare delivery.
What it does
The prediction model uses the MIMIC-III dataset to identify patterns and relationships between various patient features and the outcome of interest, such as ICU length of stay by using machine learning algorithms. The model can be used to predict the ICU length of stay for new patients based on their features. This can be useful for clinical decision-making, resource allocation, and patient management. It is important to note that the accuracy of the prediction model is dependent on the quality and quantity of the data used for training and testing. Furthermore, the model is limited by the quality and completeness of the data in the MIMIC-III dataset, as well as any biases or confounding factors that may be present in the data. Therefore, careful consideration and validation of the model's results are necessary before it can be used in clinical practice.
How it is built
I have used Azure Machine Learning Studio to build this prediction model. The selected model for my prediction is voting ensemble. Voting ensemble is a type of machine learning (ML) model that combines the predictions of multiple base models to make a final prediction. The idea behind this approach is that by combining the predictions of several models, the resulting prediction is likely to be more accurate and robust than any single model. It can improve the stability of the model by reducing the impact of any single base model's weaknesses or biases.
Challenges
Apart from finding time to work on this project while working a full-time job and being a mother of a pre-schooler, the other challenges that I faced are:
1.Data quality and completeness: The MIMIC-III dataset is a large and complex dataset that contains both structured and unstructured data, which can be incomplete or inconsistent. This made it challenging to pre-process and extract relevant features from the data, as well as to ensure the quality and accuracy of the data used for training the model.
2.Limited Domain Knowledge: The selection and engineering of relevant features from the dataset is a critical step in building an accurate prediction model. I lacked the required domain expertise for careful consideration of the relationships between various features and the outcome of interest being a naïve user.
3.Importing the dataset: As the MIMIC-III dataset is more than 40,000 patient records, I had to import the dataset from CSV to SQL Database for pre-processing which was then needed for ML Model Processing. The required data was again exported to CSV as my model was unable to connect directly to SQL Server. This consumed lot of effort and time.
4.Azure Subscription: The time limitation of free Azure account was one of the biggest challenges as my deployed model can no longer be used after subscription expiry.
5.Technical skills: Developing a prediction model requires technical skills in machine learning, statistical analysis, and programming. As I am not proficient in these skills, I found it challenging to develop an accurate and reliable model.
What I learned
1.Independence: Participating solo in a hackathon means that you are solely responsible for your project from ideation to completion. This taught me how to be independent, take initiative, and rely on my own skills and knowledge.
2.Self-motivation: Without the support of a team, it was challenging to stay motivated throughout the hackathon. I learnt how to motivate myself, set goals, and stay focused on the task at hand.
3.Time management: As a solo participant, time management becomes even more crucial. I learnt how to manage my time effectively, break down tasks into manageable pieces, and prioritize tasks to ensure that they meet the deadline.
4.Learning new skills: I learnt new skills to complete a project in a new field. This was a great opportunity to expand my knowledge and gain experience in new areas.
5.Networking: I interacted with other participants, attended workshops and townhalls and connected with mentors and sponsors to expand my knowledge and build my professional network.
What's next for Callisto Prediction for ICU Stay
Overall, the scalability of this prediction model for ICU stay depends on several factors, including the quality and size of the dataset, the complexity of the model, its ability to generalize to new data , refining and validating the model's performance, improving its interpretability, and integrating it into clinical workflows to improve patient outcomes. By carefully considering these factors and designing the model to be scalable and efficient, it can be used to predict ICU stay for a wide range of patients and clinical settings.
Log in or sign up for Devpost to join the conversation.