-
-
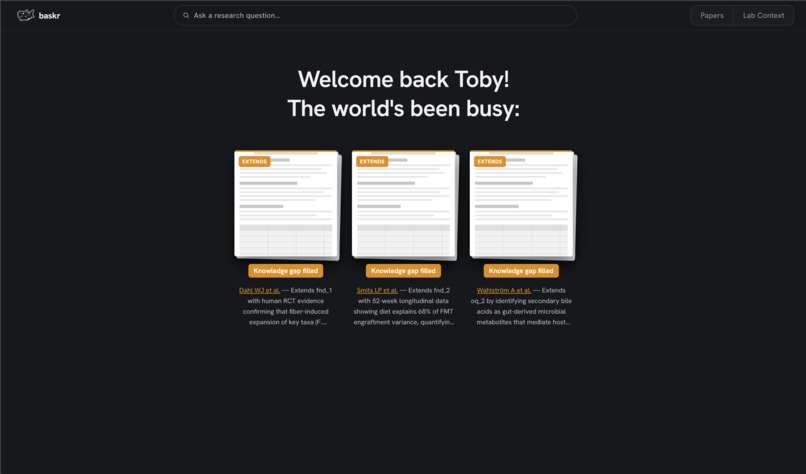
dashboard
-
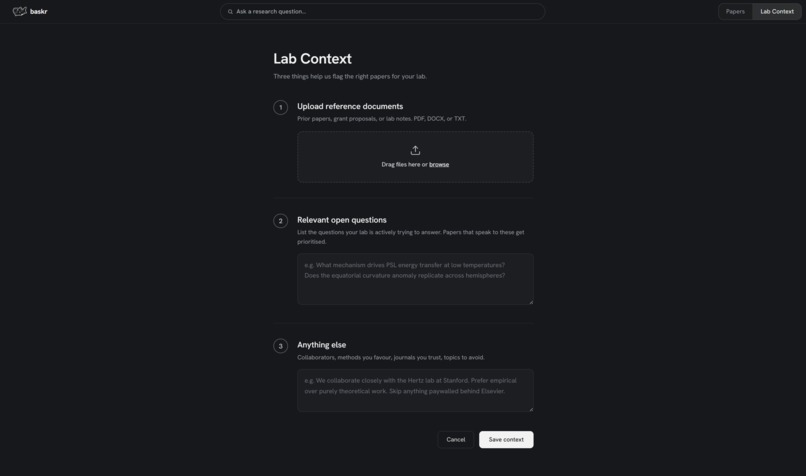
lab research context
-
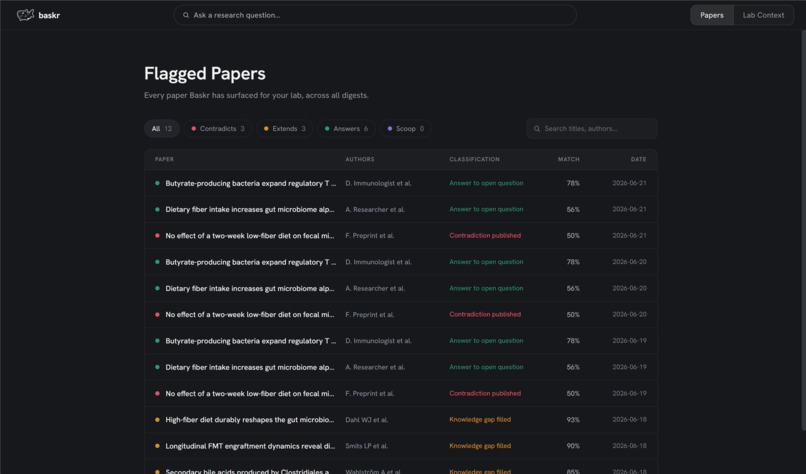
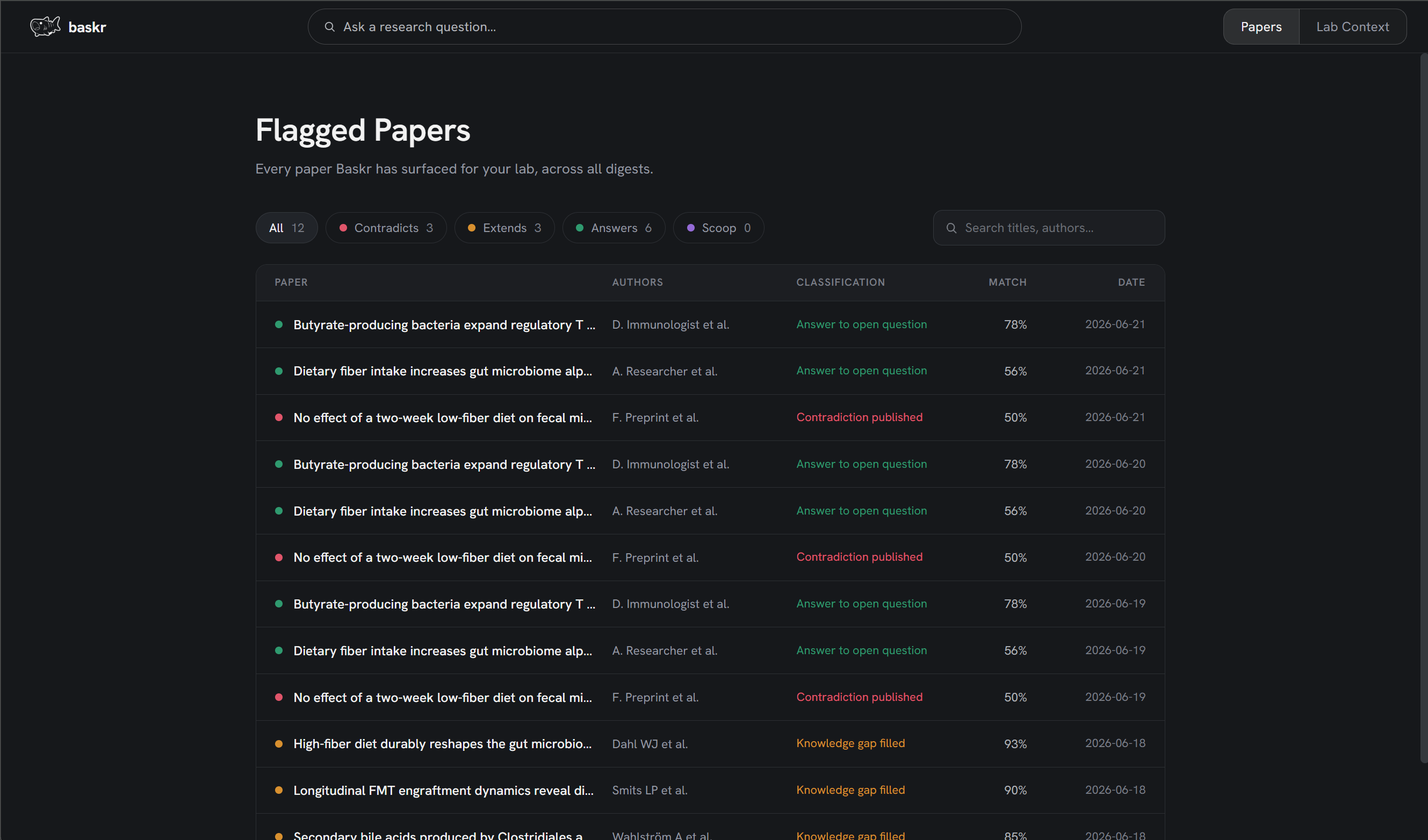
flagged papers
Inspiration
~4,000–5,000 new papers hit PubMed every day. No researcher reads them all — they rely on keyword alerts, citation tracking, and luck.
The critical failure mode isn't slow reading. It's missing the paper that matters. Labs spend quarters and $40k on experiments that were quietly answered last month. Working assumptions go unchallenged because nobody caught the contradicting paper.
Every tool in this space — Elicit, Consensus, Semantic Scholar, Research Rabbit, Google Scholar Alerts — is reactive. You ask, it searches, it answers, it forgets you. None of them maintain a persistent model of your lab's specific context. They're search boxes, not watchdogs.
What it does
Baskr is a proactive research-monitoring agent for labs. You describe your lab's open questions and working assumptions, and it reads the daily PubMed firehose — flagging the handful of new papers that actually matter to you, before you think to go looking.
The name comes from basking sharks: they float with their mouths open, filtering everything in their path and collecting only what matters. Same idea.
Baskr holds a structured memory of what your lab cares about, then monitors incoming papers against it — without being asked. When something relevant lands, it fires an alert with a plain-language reason: why this paper matters to your specific work.
The core object no competitor has is the lab profile: a structured, persistent record of your open questions, upcoming experiments, working assumptions, and findings. Every paper that enters the system is reasoned against it. The profile is the product — everything else is two views into it.
How we built it
Baskr uses Redis as its central data layer. All the memory, search, caching, and event routing runs through it — not as a cache bolted on top, but as the actual architecture.
Redis Iris is a set of managed AI-focused services on Redis Cloud. Baskr uses three of them live and one is planned for later.
RedisVL + Vector Search: Finds semantically similar papers from the corpus using an HNSW index over OpenAI text-embedding-3-small embeddings (1536 dimensions, cosine similarity). When a new paper arrives, the agent searches this index for the five most relevant prior works before reasoning about it.
Agent Memory: Stores the lab profile — assumptions, findings, open questions — as long-term memories that persist across restarts and grow as new papers arrive. The agent queries this before every classification, so Claude sees the new paper in the context of what your lab already knows.
Redis Hashes + Strings: Stores individual papers as metadata hashes (baskr:paper:{pmid}) and frozen daily digests as strings. The digest feed makes Baskr feel like a product that's been running all week, not a demo that just started.
LangCache: Caches Claude responses keyed on a normalized query hash to avoid redundant API calls on semantically similar searches. Hit/miss counters surface in the UI.
The agent loop itself is seven steps: receive a paper from the Redis Stream → embed the abstract → vector search prior work → query Agent Memory for relevant lab context → send all three to Claude → broadcast an SSE alert if relevant → write a new long-term memory if the paper updates lab knowledge. Steps 3 and 4 are what make the reasoning good. Claude doesn't just see the new paper — it sees it against what the lab already knows.
The AI reasoning layer uses Claude (claude-sonnet-4-6) with forced tool use to enforce a strict JSON output contract: { label, reason, matched_item_id, confidence }. No freeform prose, no parsing fragility.
Challenges we ran into
The local Redis server didn't ship with RediSearch. The standard redis-server (7.0.15) doesn't include the RediSearch module, and Docker image pulls were 403-blocked in our build environment. We couldn't run RedisVL's HNSW index against the local server at all. Our solution was a transparent degradation layer: ensure_papers_index probes FT._LIST at startup and falls back to a pure-Python brute-force cosine scan over all baskr:paper:* hashes when no search module is present. Same function signatures, same result ordering. The RedisVL/HNSW path auto-engages the moment a redis-stack server is reachable — no code change required. The demo runs against redis/redis-stack-server to exercise real HNSW.
No API keys in the build environment. We had no OPENAI_API_KEY, ANTHROPIC_API_KEY, or NCBI_API_KEY during most of the build. Rather than hard-requiring keys and blocking all progress, we built a degraded-mode layer: embeddings fall back to deterministic hashed vectors, the LLM falls back to a rule-based canned classifier, and the data pipeline falls back to staged sample papers. Live mode engages automatically when keys appear. /status reports these connections as unknown rather than down in degraded mode, so the health endpoint is honest without being alarming.
The critical demo data separation problem. If "new" papers get loaded into the vector index alongside the historical corpus, the agent finds itself when searching for prior work and the alert moment dies. We enforced a strict split: corpus papers go through the full chunk → embed → index pipeline; demo papers go to the Redis Stream only, with no vector index entry. This required careful orchestration of two separate data paths and a dedup check on Stream consumption.
Import path drift. Mid-build, a branch merge renamed the data pipeline module from implementations/data_pipeline to system_pieces/data_pipeline. Several files were importing the old path. We resolved it with a path shim in app/__init__.py that inserts the repo root onto sys.path, keeping DataPipeline imports local-in-function and resolving regardless of launch directory.
Accomplishments that we're proud of
Redis is the architecture, not the cache. Every piece of meaningful state in Baskr lives in Redis: the lab profile in Agent Memory, the paper corpus in the vector index, the event feed in Streams, the digest snapshots in Hashes/Strings, and the response cache in LangCache. We didn't reach for Postgres or SQLite for anything. The data model is Redis-native from the start.
The degradation story actually works end-to-end. Eighteen tests pass green — including nearest-neighbor search and live /status checks — against a real Redis server, with no external API keys. The same code that runs in degraded mode is identical to what runs in production; there's no test-specific branch. This is the correct way to build for environments you don't control.
Forced tool use for JSON enforcement. Getting structured output from Claude reliably is harder than it looks. We use a single-tool forcing pattern — Claude is given exactly one tool (record_classification) with a strict input schema — which means the JSON contract is enforced at the API level, not via regex parsing of free text. Classification results are never malformed.
The lab profile as a persistent, compounding object. This is the thing no competitor has. Lab context grows over time as new papers are classified and written back as long-term memories. A lab that's been using Baskr for six months has a richer context than one that started yesterday, and a new competitor can't cold-start that for your customers.
What we learned
Proactive versus reactive is an architecture problem, not a feature. Building a system that monitors on your behalf — rather than answering when asked — requires a completely different data model. You need persistent context, an event loop that runs without user input, and a way to separate "what the system already knows" from "what just arrived." None of that is a UI decision; it's a data design decision.
Redis Iris is genuinely shaped for this problem. Agent Memory for persistent lab context, Vector Search for similarity retrieval, Streams for the event bus, LangCache for response deduplication — these aren't forced fits. The architecture fell out naturally from the problem, and Redis Iris happened to have a managed service for each piece. That's either good product design from the Redis team or a well-chosen problem on our part. Probably both.
Built With
- arxiv
- claude
- openai
- pubmed
- python
- redis
- typescript




Log in or sign up for Devpost to join the conversation.