
Inspiration
AI coding assistants made writing code dramatically faster, but code review never got faster to match. Claude Code commits on GitHub went from near-zero to 120,000+ per day in under a year. The humans reviewing that code are now the bottleneck.
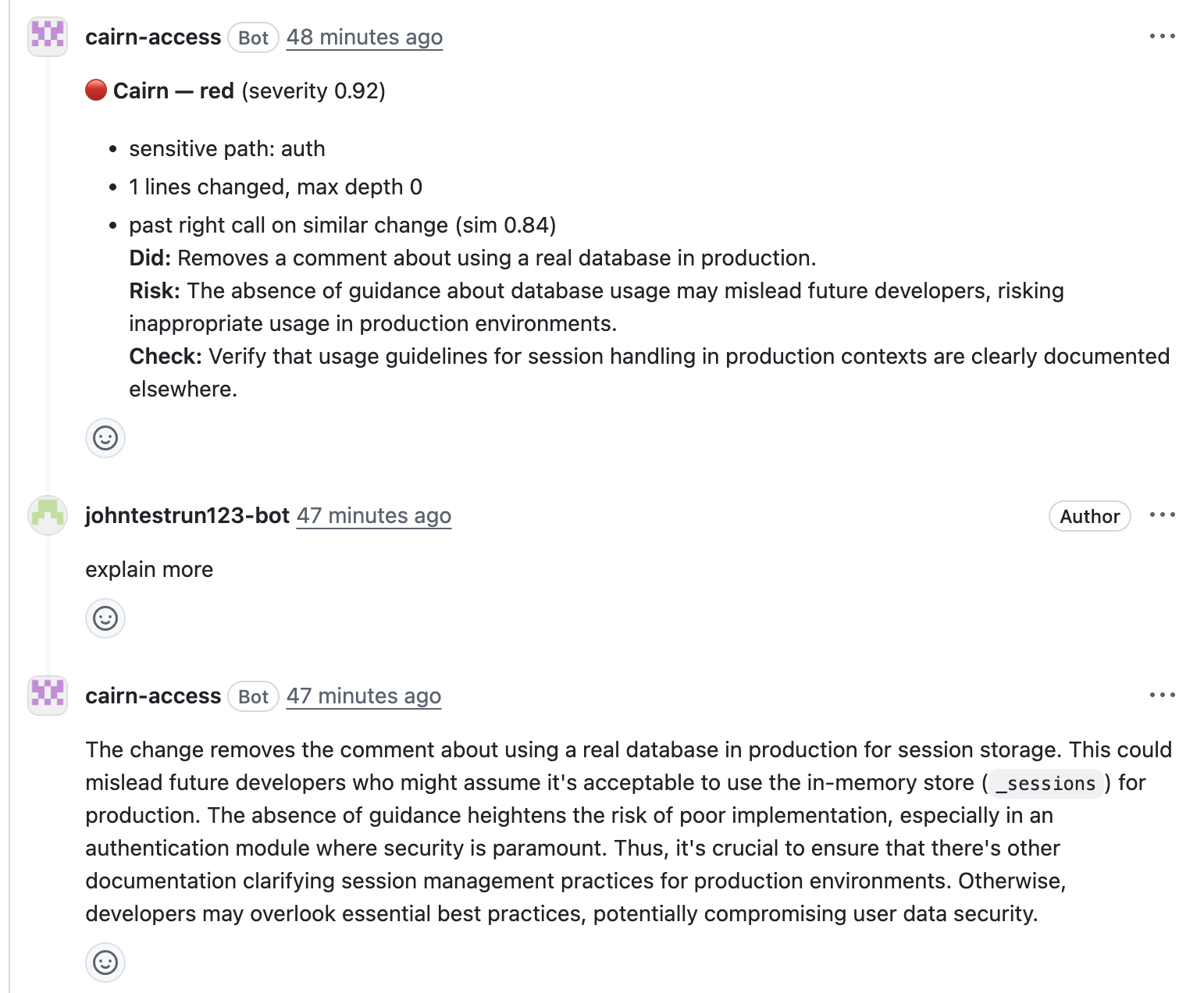
Today's AI reviewers (CodeRabbit, Greptile, Qodo) are additive: they give you more to read. They add comments on top of the diff. They don't tell you where to look, and their severity scores are model opinions you're asked to trust blindly.
We wanted a tool that was subtractive — one that removes the safe 80% from your reading load rather than piling on. Cairn is that tool.
What We Built
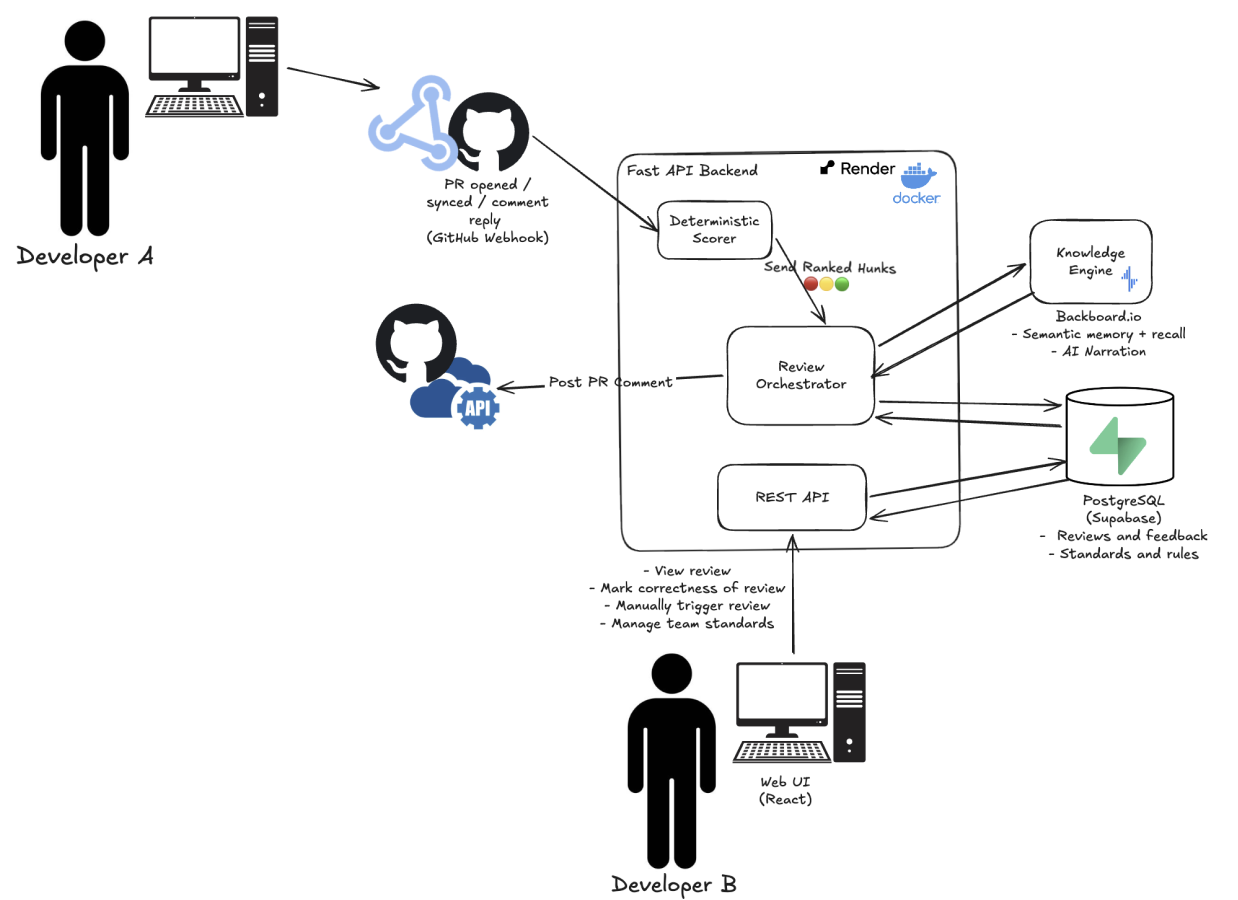
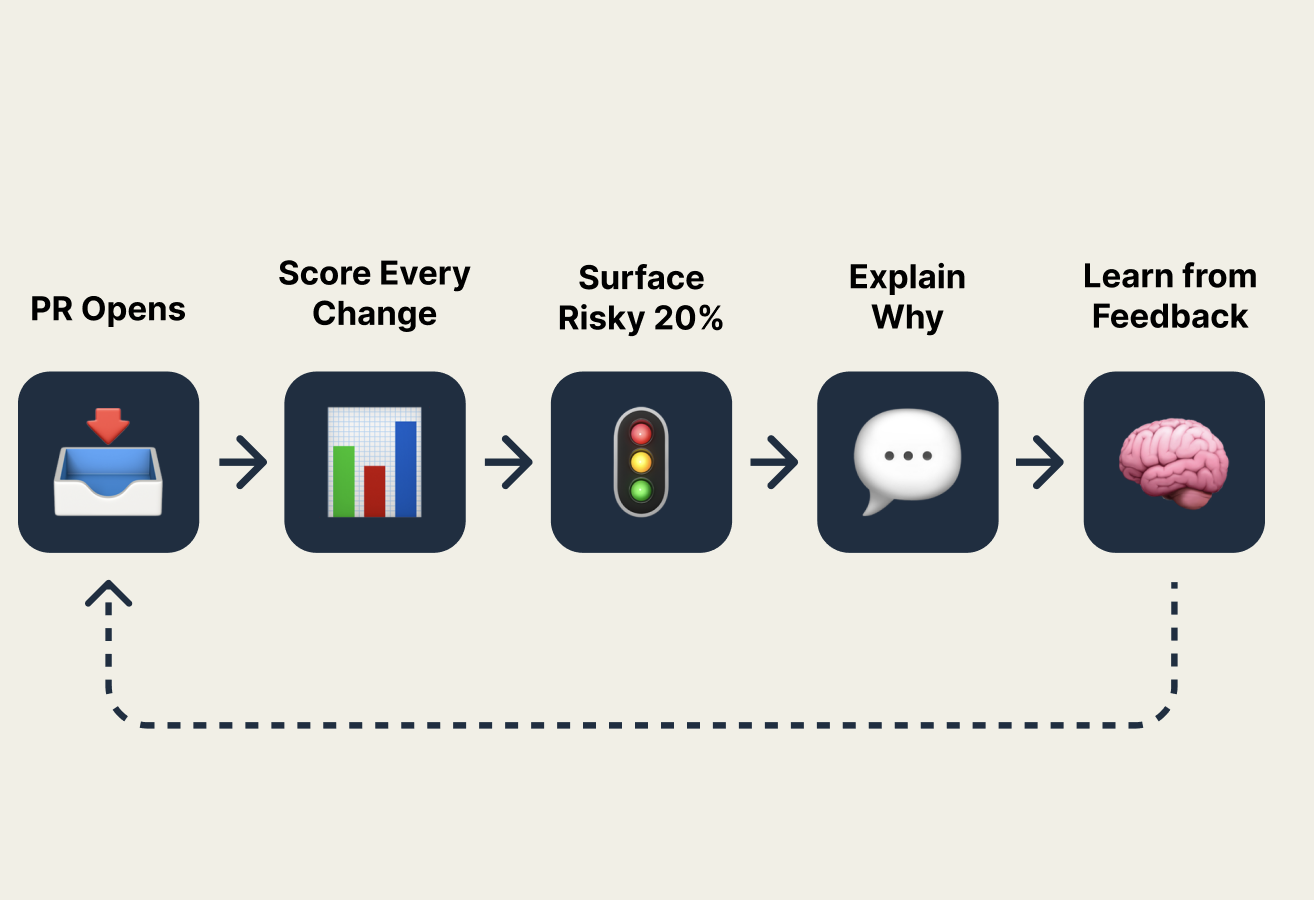
Cairn is a deterministic attention router for AI-generated diffs. When a PR opens, Cairn:
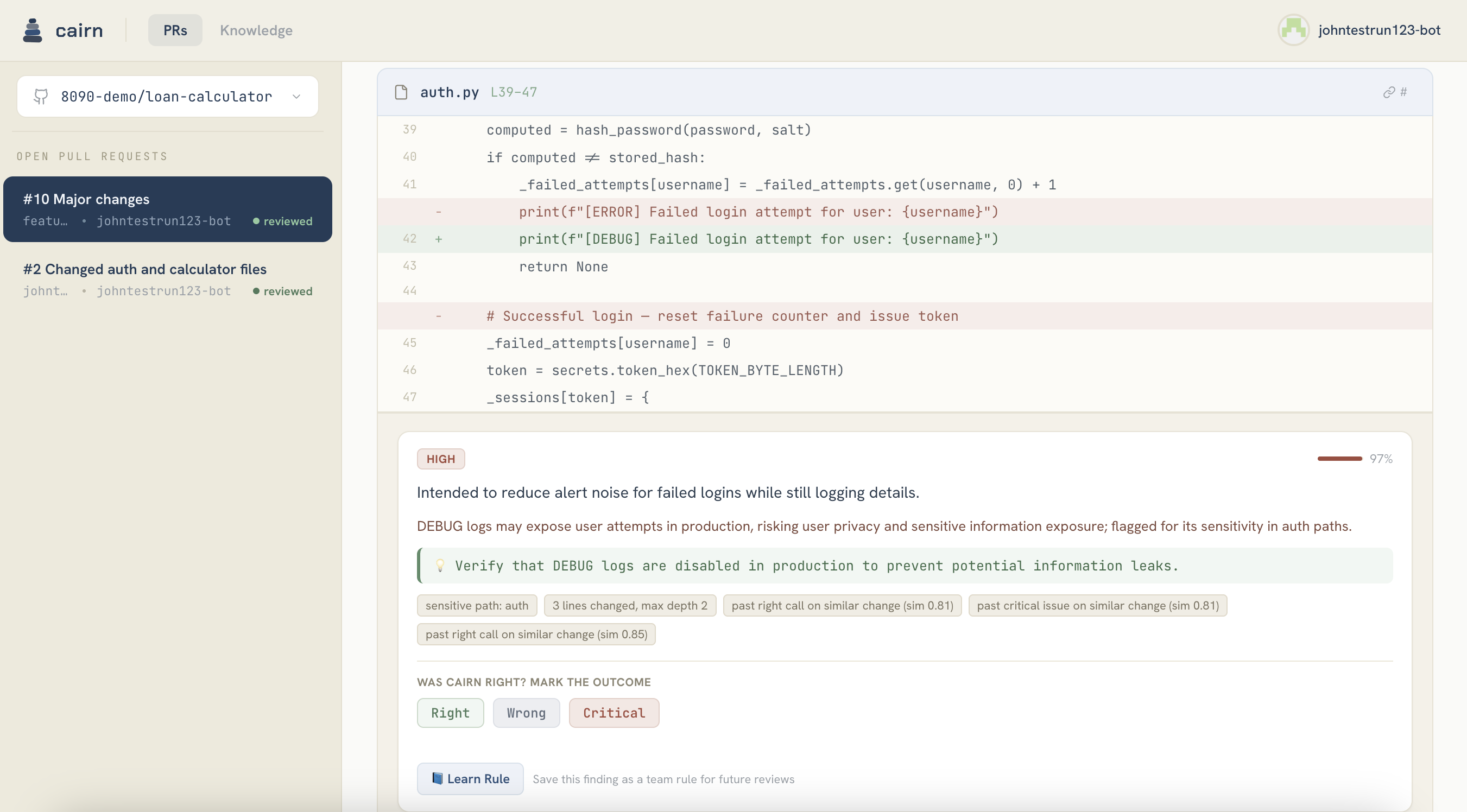
- Scores every hunk using auditable, deterministic Python signals — sensitive path, hunk size, coverage on changed lines, blast radius (caller count). Same diff → same score, every run, every reviewer.
- Searches semantic memory of past reviewer outcomes (right / wrong / critical) and adjusts severity asymmetrically: a past critical in the same region boosts the score hard and stickily; a past "wrong" flag lowers it weakly and decayably.
- Narrates the top-N risky hunks via a single LLM call (routed through Backboard to Cerebras):
Did / Why / Risk / Check— soft hints, not ground truth. - Posts a ranked summary directly in the PR comment: 🔴 review these, 🟡 maybe glance, 🟢 199 hunks checked — safe to skim. Inline annotations land only on 🔴/🟡, so GitHub's comment-nav hops red-to-red.
The core design principle: the model narrates, deterministic code ranks. The score line is never a model opinion.
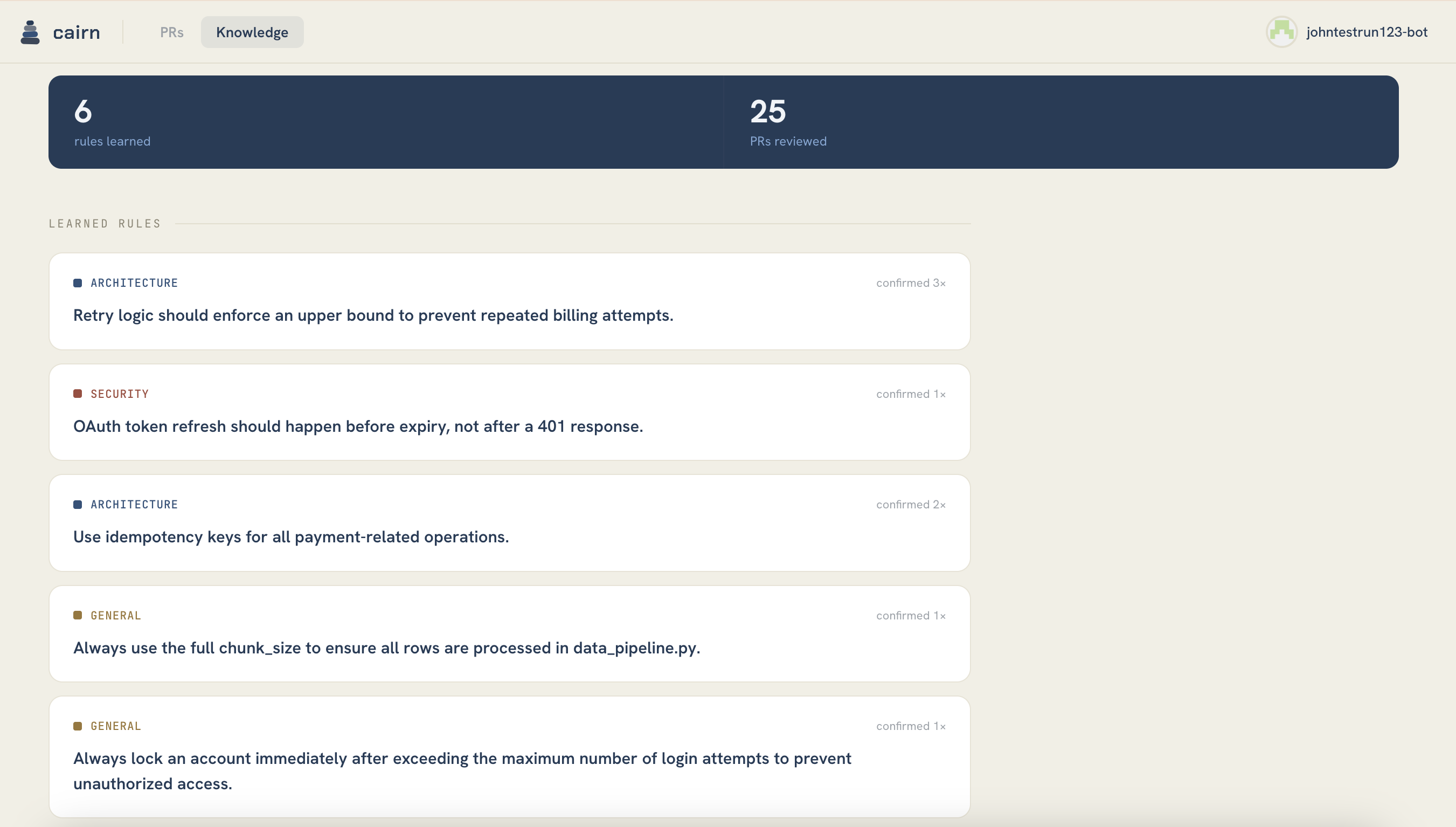
We also shipped a React dashboard that renders the same Postgres rows — ranked PR view, per-hunk deep-dive, memory browser, and a live re-rank toggle (memory ON vs OFF) that shows the self-improvement curve in real time.
How We Built It
- FastAPI backend runs the deterministic scorer in-process, handles GitHub App webhooks, orchestrates narration, and exposes read + re-rank endpoints for the webapp.
- Backboard hosts two split assistants:
cairn-narrator(Cerebras-routed LLM, Did/Why/Risk/Check) andcairn-memory(semantic memory only — stores outcome strings, searches on next PR). - PostgreSQL is the single source of truth for repos, PRs, hunks, outcomes, and rules.
- GitHub App + webhook (not Actions) — an always-on server catches events, posts as Cairn, and handles reply-to-annotation threading for per-hunk Q&A inside GitHub itself.
- React + Vite frontend reads the same Postgres rows the webhook pipeline writes — consistency by construction.
Challenges
The hardest design call was keeping severity deterministic. Every instinct says "just ask the LLM to rate it" — it's one line of code. But LLM self-rated severity is uncalibrated, drifts with prompt and temperature, can't be systematically improved, and collapses Cairn into the same "trust our model" bucket our competitors already occupy. We held the line: auditable signals only in the score, LLM only in the narration.
The memory loop required careful asymmetry. A false positive ("wrong" flag) should decay quickly so the scorer doesn't go blind. A missed critical should boost hard and stick. Getting that calibration to actually move recall@20% — our north-star metric — took iteration.
Per-hunk Q&A entirely inside GitHub via reply-to-annotation threading was a surprise architectural win. No context switch, no webapp login, no re-rendering the diff — the reviewer replies to a Cairn comment and gets an answer in-thread.
Built With
- backboard
- cerebras
- docker
- fastapi
- github-apps
- javascript
- postgresql
- python
- react
- vite

Log in or sign up for Devpost to join the conversation.