-
-
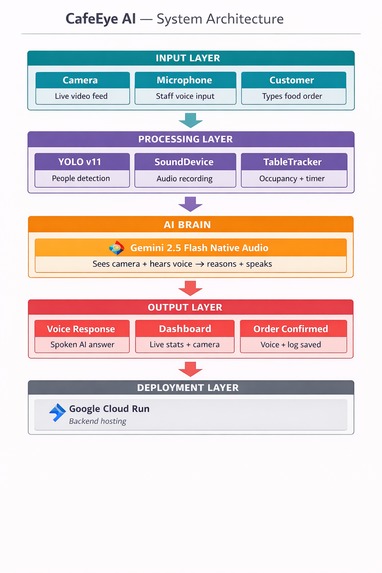
System Architecture
-
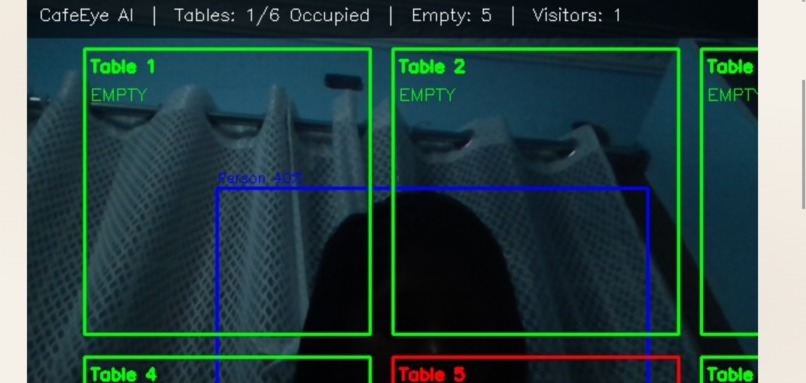
Live Camera
-
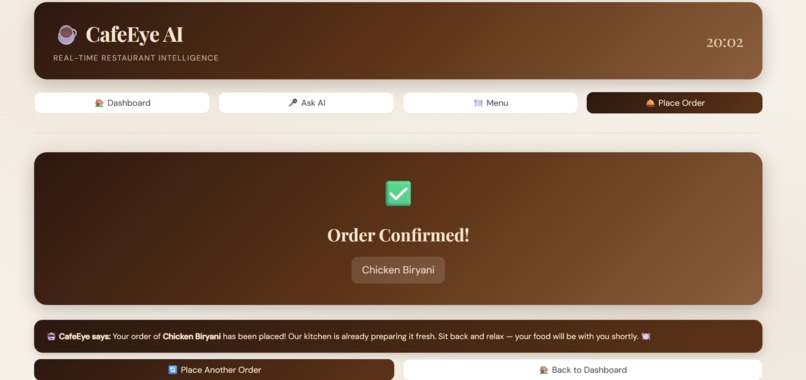
Order
-
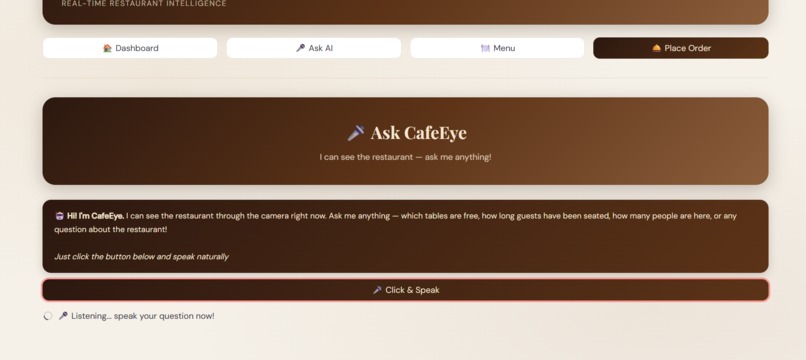
Ask CafeEye AI
☕ CafeEye AI — The Restaurant That Sees, Thinks & Speaks
💡 What Inspired Me
Walking into a busy restaurant and watching staff struggle to track empty tables manually sparked the idea. Cameras are already everywhere in restaurants — but they just record. They don't think. I asked myself: what if a camera could understand what it sees and talk to you about it in real time?
That question became CafeEye AI.
🏗️ How I Built It
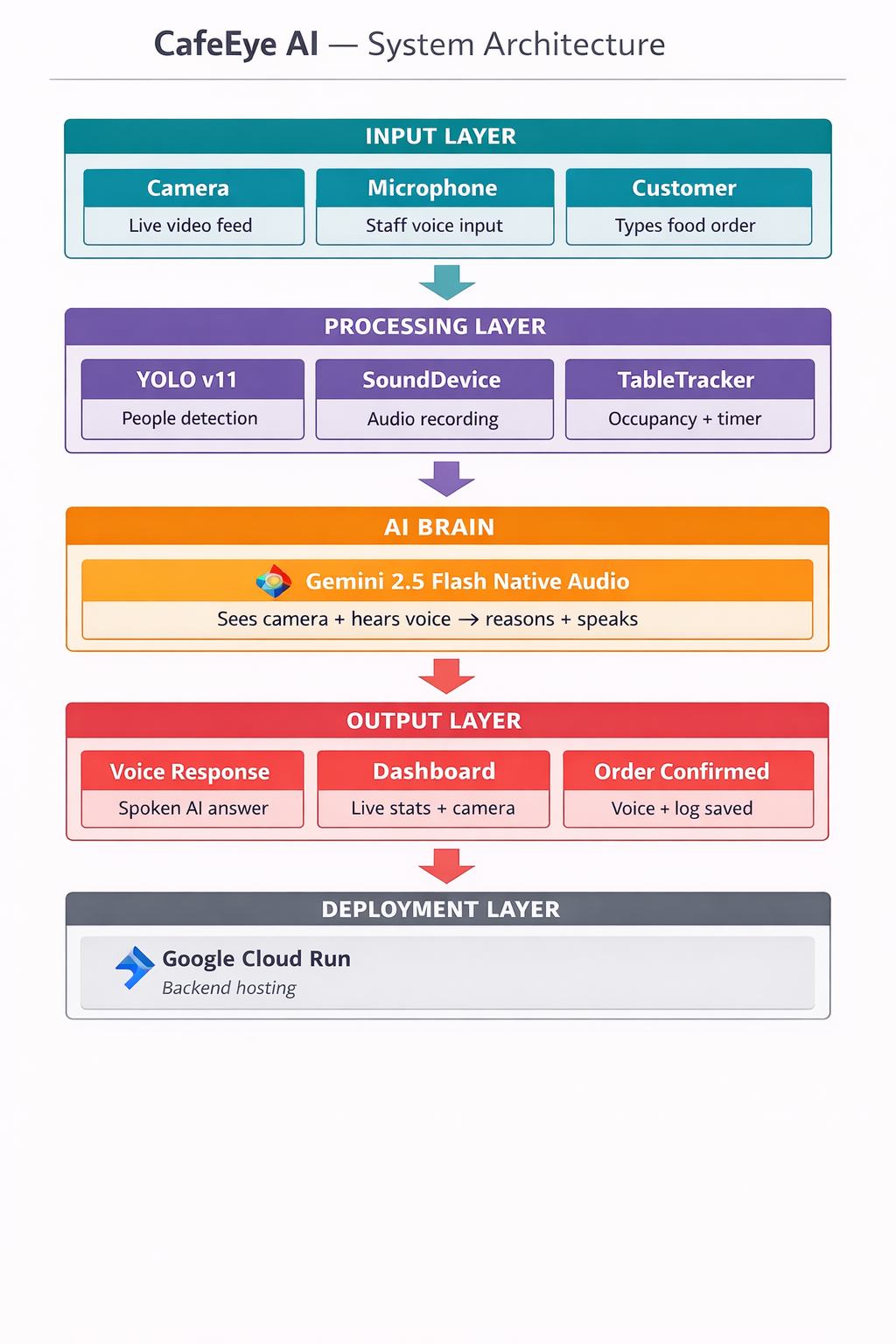
CafeEye is a full-stack multimodal AI system built in layers:
Layer 1 — Vision (Eyes)
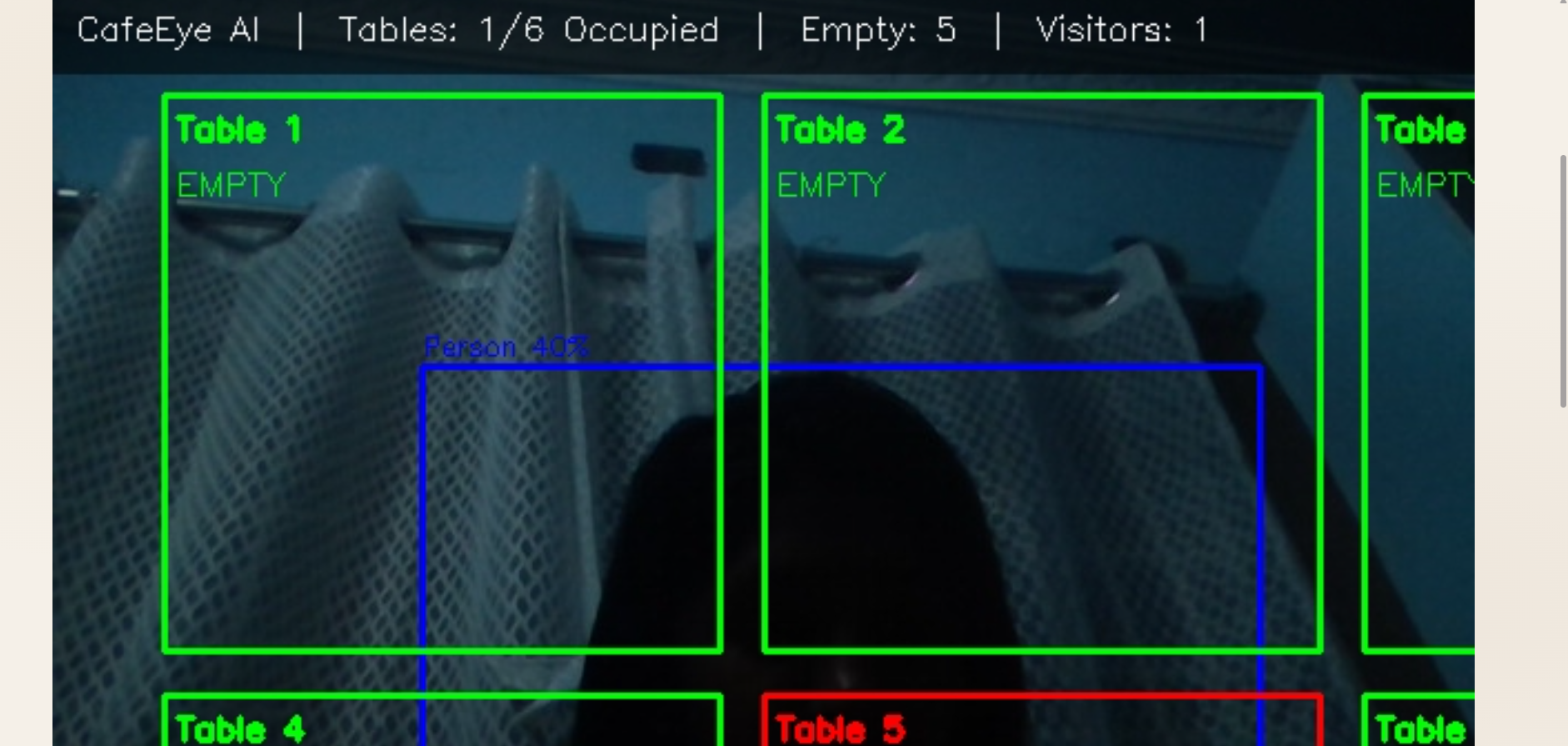
- Live camera feed processed in real time using YOLO (You Only Look Once) object detection
- Detects people at tables with bounding boxes and confidence scores
- 6 configurable table zones tracked simultaneously
Layer 2 — Intelligence (Brain)
- Gemini 2.5 Flash Native Audio as the core reasoning model
- Camera frames + sensor data sent together for multimodal understanding
- The model sees AND reasons — not just pattern matching
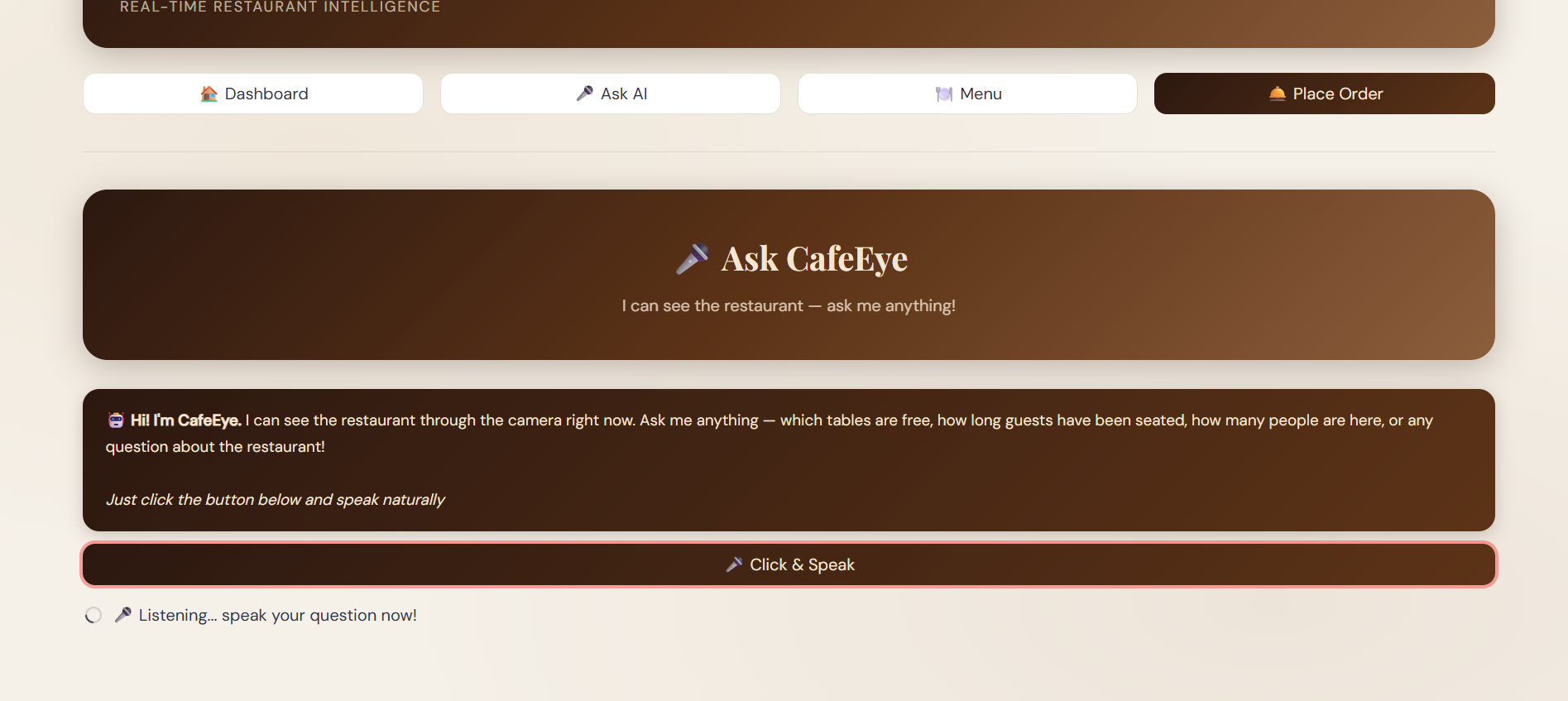
Layer 3 — Voice (Voice)
- Gemini Live API for real-time voice interactions
- Staff can ask questions like "Which table has been waiting longest?"
- AI responds with spoken natural language answers
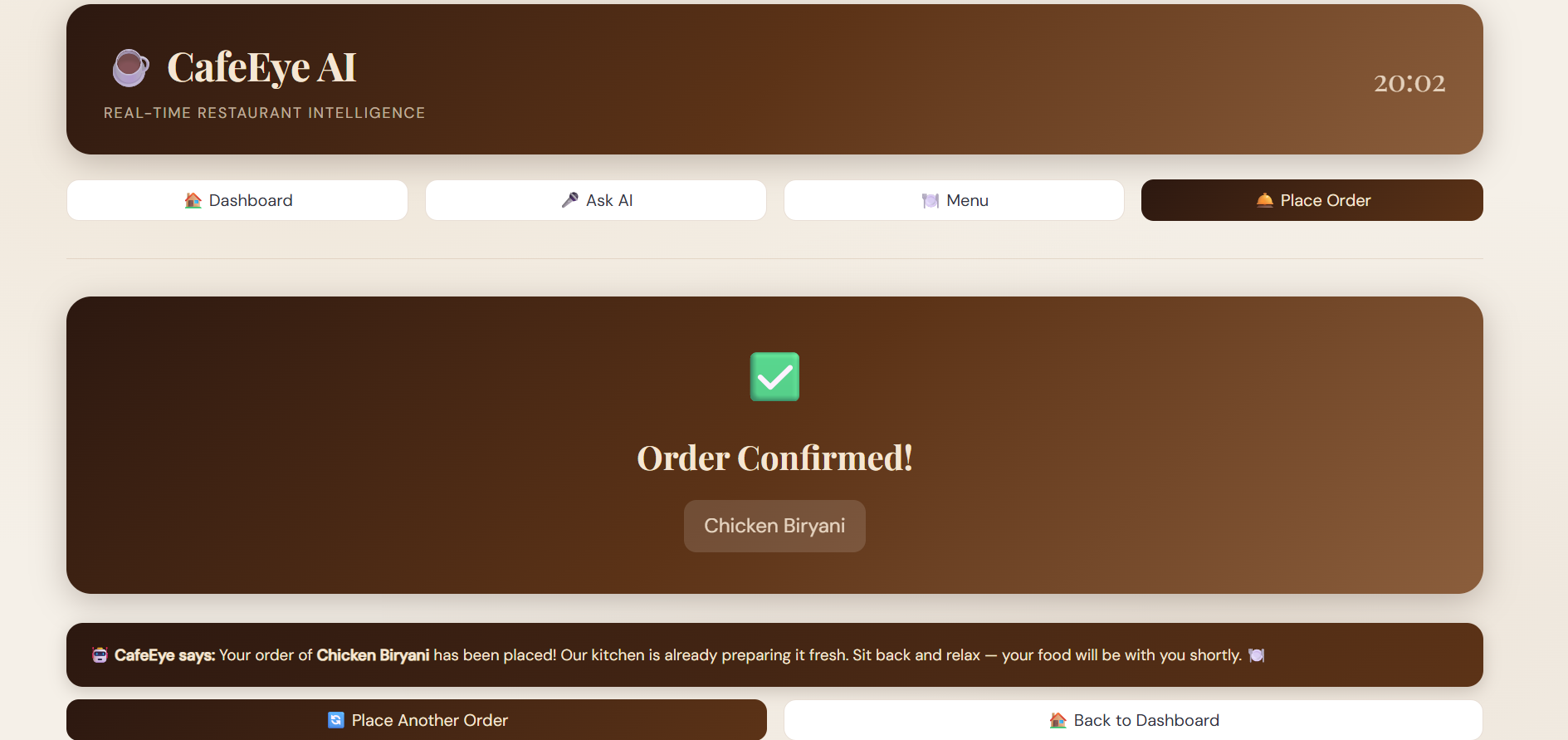
- Order confirmation spoken aloud to customers
Layer 4 — Ordering System
- Full restaurant menu with veg/non-veg categories
- AI recommends dishes by voice
- Customers type orders, AI confirms by speaking
The Math Behind Detection:
The confidence threshold for person detection is:
$$P(\text{person} | \text{box}) > \tau, \quad \tau = 0.4$$
Table occupancy duration tracked as:
$$D_{\text{table}} = t_{\text{current}} - t_{\text{arrival}}$$
Alert triggered when:
$$D_{\text{table}} > 1800 \text{ seconds} \quad (30 \text{ mins})$$
🛠️ Tech Stack
| Component | Technology |
|---|---|
| Vision Detection | YOLO v11 (Ultralytics) |
| AI Brain | Gemini 2.5 Flash Native Audio |
| Live Voice | Gemini Live API |
| Real-time Streaming | Google GenAI SDK |
| Frontend Dashboard | Streamlit |
| Camera Processing | OpenCV |
| Audio I/O | SoundDevice |
| Deployment | Google Cloud Run + Streamlit Cloud |
🧠 What I Learned
Building a truly live multimodal agent is fundamentally different from building a chatbot. The hardest challenges were:
Synchronizing vision and audio — camera frames and voice responses run at different speeds and need careful threading
Gemini Live API nuances — the response comes in multiple chunks (
model_turn,generation_complete,turn_complete) and must be collected carefully before playbackReal-time state management — tracking 6 tables simultaneously while handling voice input without freezing the UI required background threading
Cloud deployment of vision apps — cameras don't exist on cloud servers, requiring creative solutions for demo and deployment
🚧 Challenges Faced
Audio quality — Initial voice output was breaking and repeating. Fixed by collecting the entire audio buffer before playback instead of streaming chunks
Gemini quota limits — Free tier hit rate limits during testing. Solved by increasing analysis intervals and optimizing API calls
OpenCV on cloud —
libGL.so.1missing on cloud servers required switching toopencv-python-headlesswith system library dependenciesStreamlit + asyncio — Streamlit's event loop conflicts with Python's asyncio. Solved by running each voice session in a dedicated thread with its own fresh event loop
🎯 Real-World Impact
CafeEye addresses a genuine problem:
- Restaurants lose revenue when tables aren't turned over efficiently
- Staff waste time manually checking table availability
- Customers wait longer than necessary to be seated
CafeEye solves all three — automatically, intelligently, and in real time.
🚀 What's Next
- Multi-camera support for large restaurants
- Customer emotion detection (happy, waiting, frustrated)
- Integration with POS systems for automatic billing
- Mobile app for restaurant managers
- Analytics dashboard with weekly/monthly reports

Log in or sign up for Devpost to join the conversation.