
💔 Inspiration
Picture this.
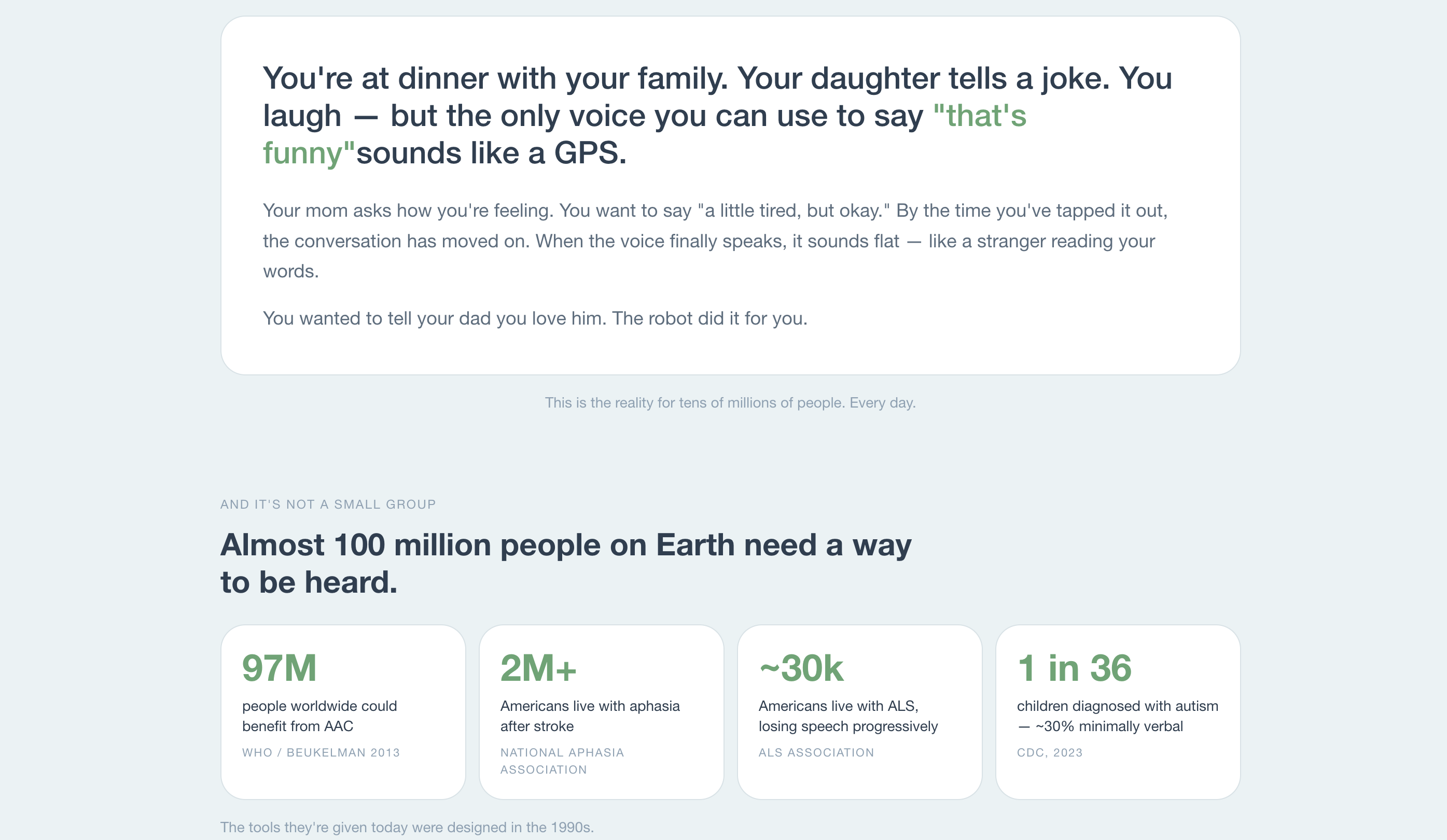
You're at dinner with your family. Your daughter tells a joke. You laugh — but the only voice you can use to say "that's funny" sounds like a GPS.
Your mom asks how you're feeling. You want to say "a little tired, but okay." By the time you've tapped it out on a stiff menu of pre-built phrases, the conversation has moved on. When the voice finally speaks, it sounds flat — like a stranger reading your words.
You wanted to tell your dad you love him before bed. The robot did it for you.
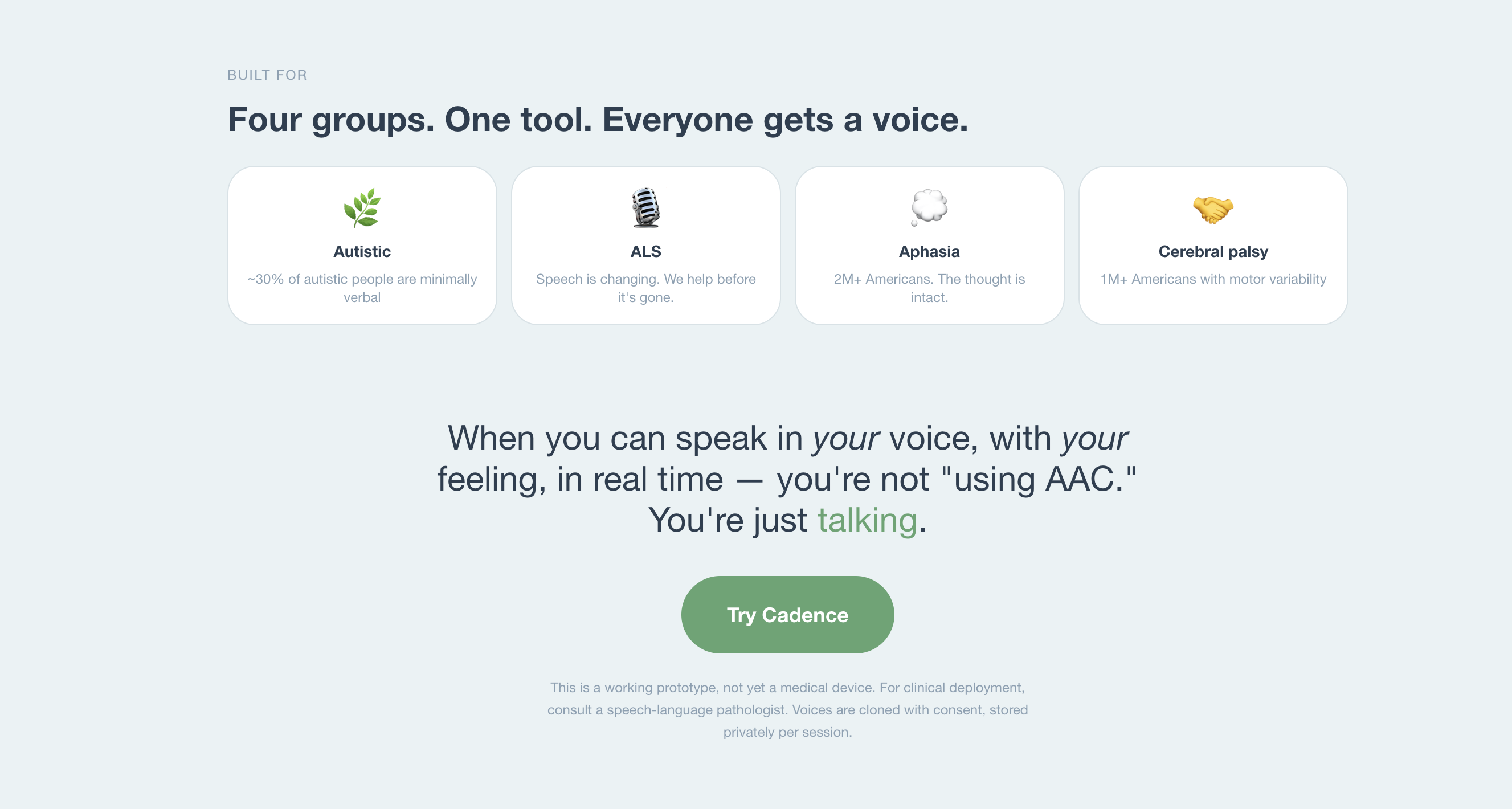
This is the daily reality for roughly \(97{,}000{,}000\) people worldwide who rely on augmentative and alternative communication (AAC):
- \(2\text{M}+\) Americans with aphasia after stroke — thought intact, retrieval broken
- \(\sim 30{,}000\) Americans with ALS — losing the voice they once had, progressively
- \(\frac{1}{36}\) children diagnosed with autism (CDC, 2023) — roughly \(30\%\) minimally verbal
- \(1\text{M}+\) with cerebral palsy whose motor variability makes typing painful
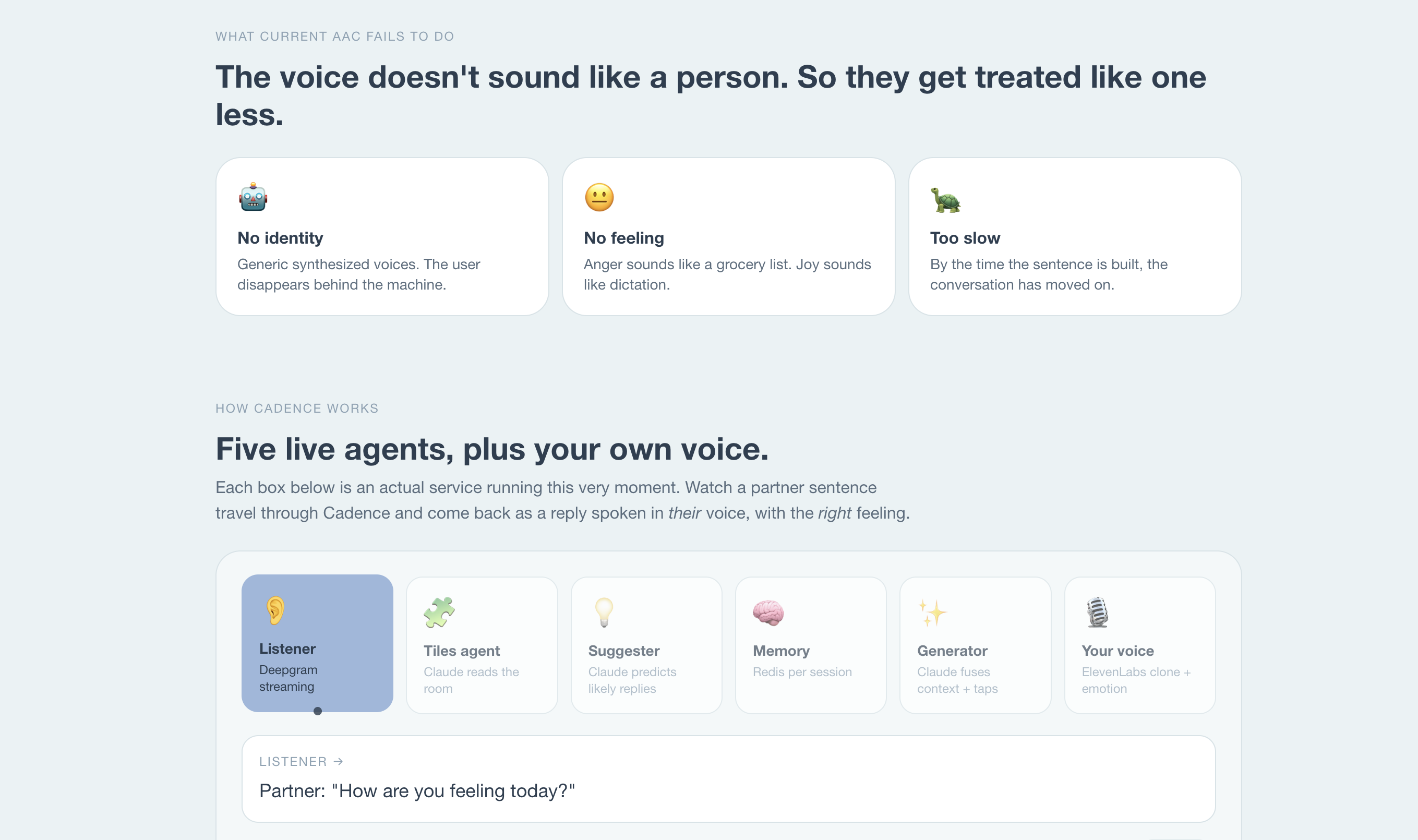
The tools they're given today were designed in the 1990s. The voices sound robotic. The menus take minutes to navigate. The emotion is completely missing.
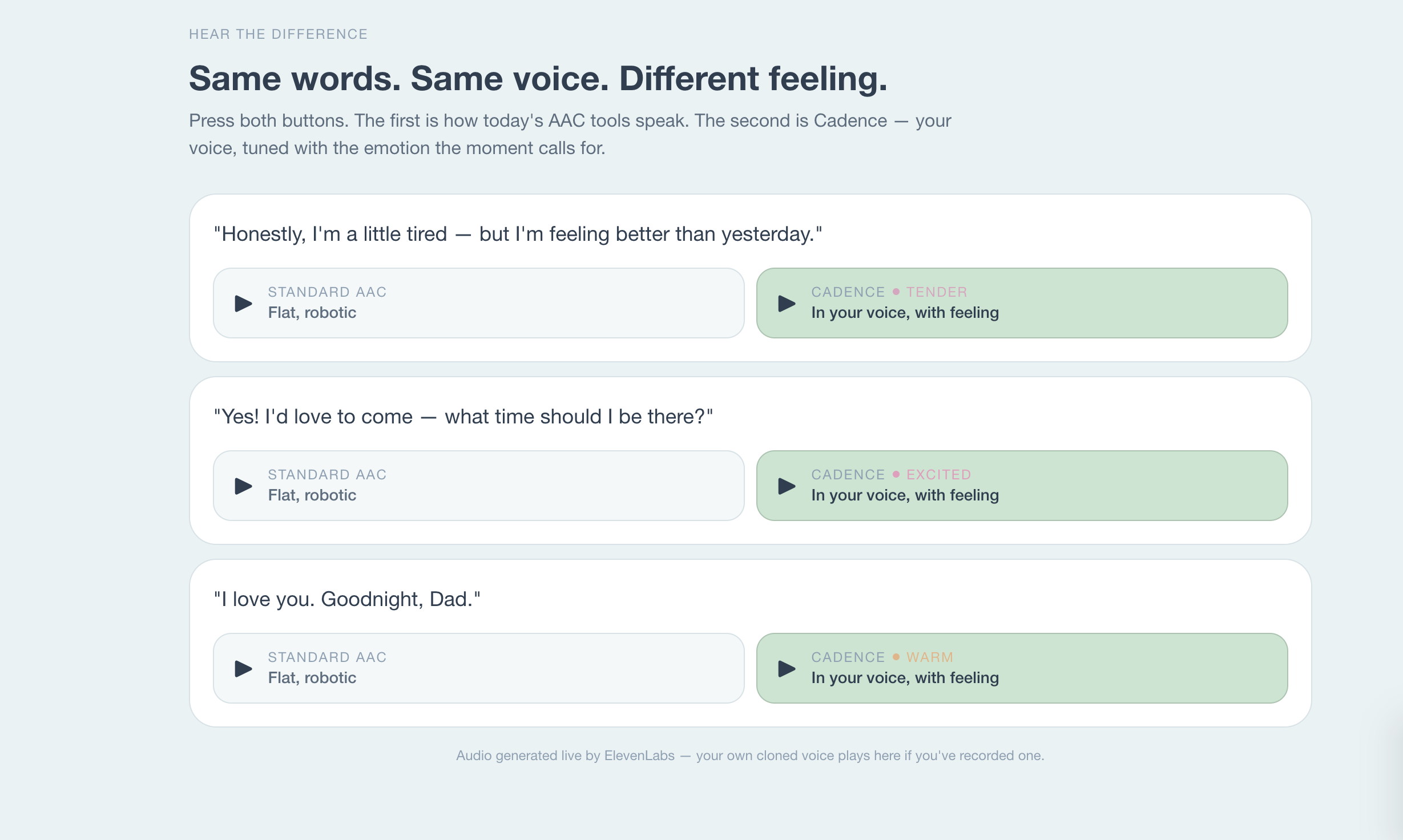
We built Cadence because "I love you" should never sound like a GPS announcement.
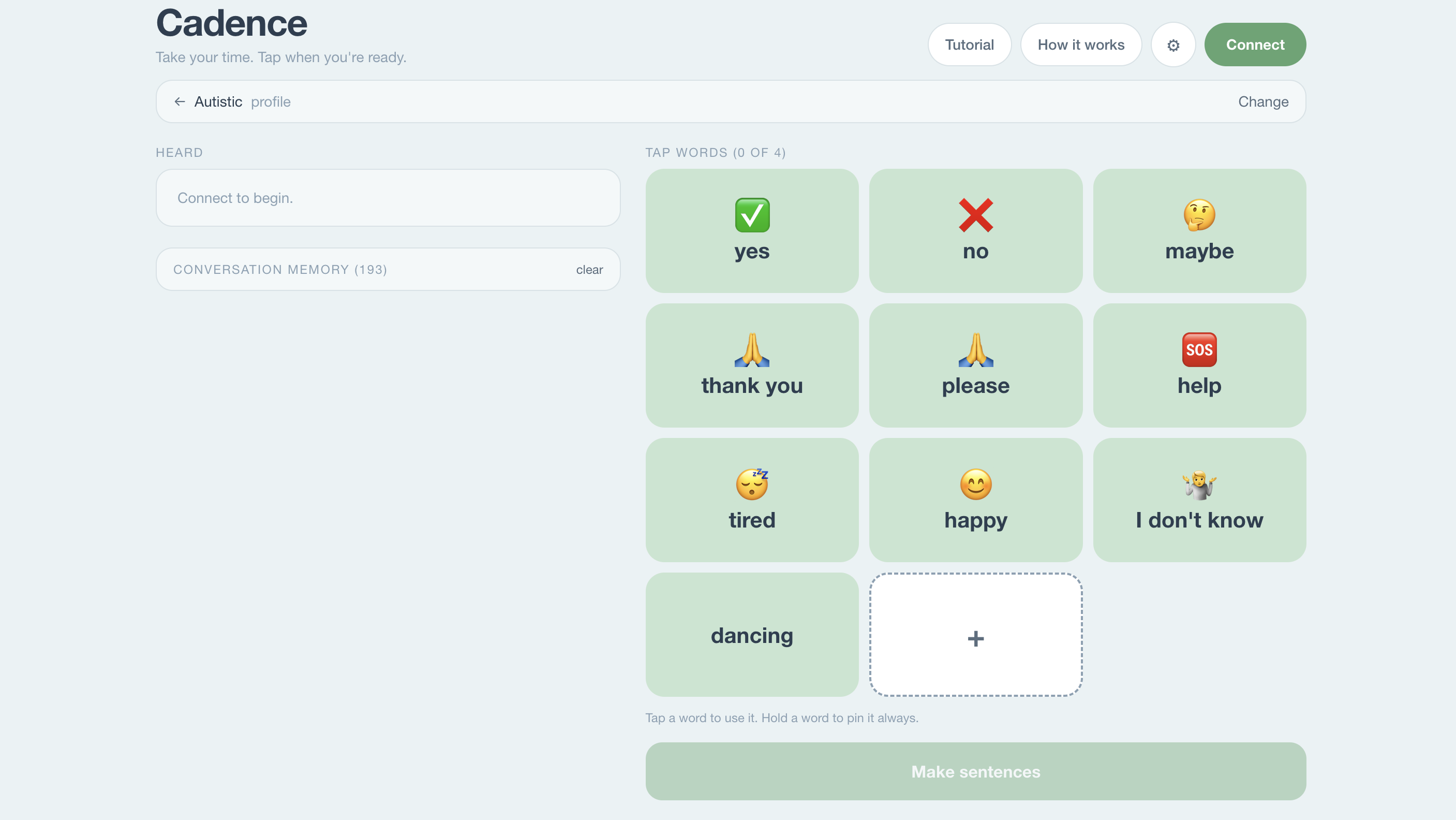
🌊 What It Does
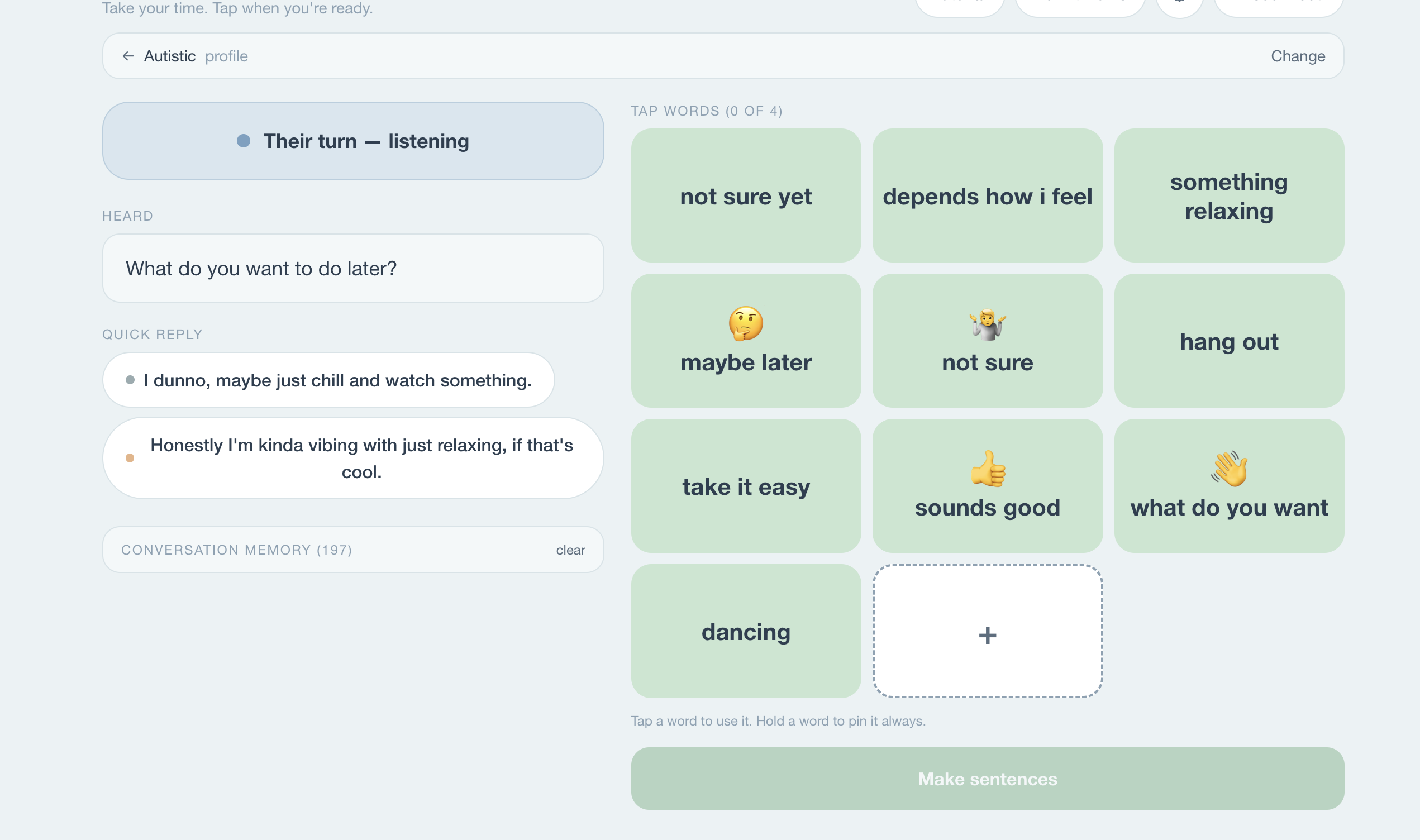
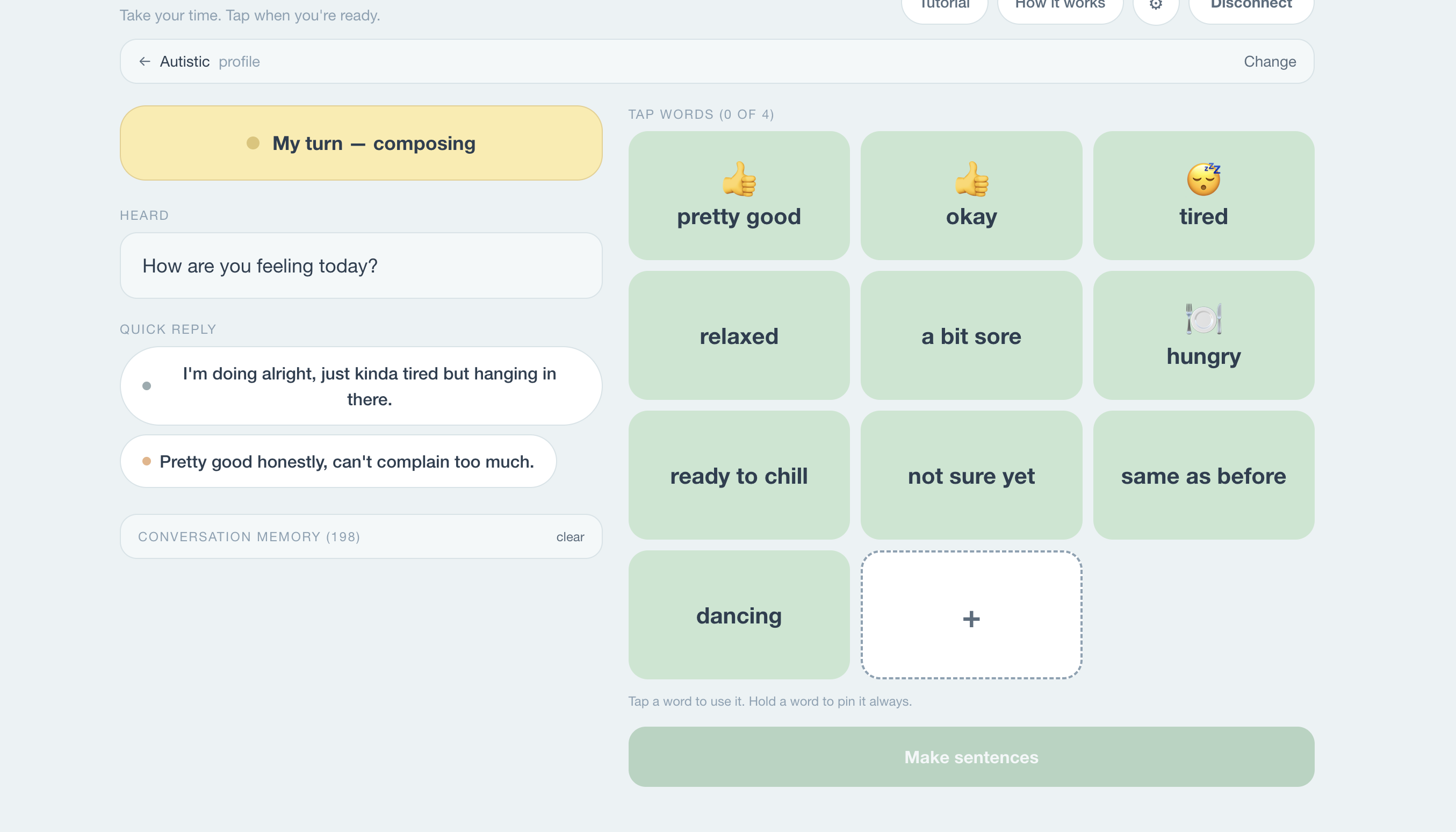
Cadence is a real-time AAC tool. Four live AI agents turn a heard conversation into a reply spoken in your own cloned voice, with the right feeling, in seconds — using ElevenLabs Instant Voice Cloning + emotion-tuned voice_settings for the output.
The full loop:
$$ \text{partner speech} \;\rightarrow\; \text{Listener (Deepgram)} \;\rightarrow\; \text{transcript} \;\rightarrow\; \text{Tiles + Memory} \;\rightarrow\; \text{tile grid} \;\rightarrow\; \text{taps} \;\rightarrow\; \text{Generator} \;\rightarrow\; {c_1, c_2, c_3} \;\rightarrow\; \text{pick} \;\rightarrow\; \text{ElevenLabs} \;\rightarrow\; \text{your voice} $$
Each candidate \(c_i\) is a tuple:
$$ c_i = (\text{text}i,\ e_i,\ \mathbf{S}{e_i}) $$
where \(e_i\) is one of 13 emotion labels and \(\mathbf{S}_{e_i}\) is the hand-tuned ElevenLabs voice_settings vector for that emotion.
🧠 How We Built It
Four AI agents + a Memory layer + a Voice layer
| Layer | Tech | Role |
|---|---|---|
| Listener | Deepgram streaming WS | Real-time partner transcription with endpointing + KeepAlive |
| Tiles agent | Claude Haiku 4.5 | Picks 12 contextually relevant tiles per partner turn |
| Suggester | Claude Haiku 4.5 | Proactive 2 reply predictions (no taps needed) |
| Generator | Claude Haiku 4.5 | Fuses heard context + taps + memory into 3 emotion-tagged candidates |
| Memory | Redis (per session) | Persistent conversation log; last 6 turns feed back into Generator |
| Voice | ElevenLabs turbo_v2_5 + Instant Voice Cloning | Speaks chosen candidate in the user's cloned voice with per-emotion voice_settings |
Four decision-making AI agents — Listener, Tiles, Suggester, Generator — coordinate over a Redis memory layer, with ElevenLabs as the voice output layer.
ElevenLabs Voice Cloning — the identity layer
For users who can still speak (ALS pre-diagnosis, autistic adults, anyone before a stroke), we record \(\sim 60\) seconds of phoneme-balanced Harvard Sentences in the browser and POST to ElevenLabs Instant Voice Cloning. The returned voice_id is stored per-session in Redis under cadence:session:{sid}:voice so it survives page refresh. From that moment, every TTS call uses the user's voice, not a stock voice.
Latency budget
Cadence has to feel as fast as natural conversation:
$$ T_{\text{total}} = T_{\text{stt}} + T_{\text{generate}} + T_{\text{select}} + T_{\text{tts}} $$
Empirically: \(T_{\text{stt}} \approx 200\text{ms}\), \(T_{\text{generate}} \approx 600\text{ms}\), \(T_{\text{tts}} \approx 700\text{ms}\).
ElevenLabs is tuned for low first-byte latency: output_format=mp3_44100_64
optimize_streaming_latency=2
model_id=eleven_turbo_v2_5 turbo_v2_5 was picked over flash_v2_5 because cloned voices need its better prosody handling; mode 2 keeps prosody intact while streaming the first byte fast.
Pre-warming (the biggest latency win)
The moment the Generator returns the 3 candidates, the frontend issues 3 parallel ElevenLabs TTS requests before the user has even read them:
$$ T_{\text{perceived}} = T_{\text{generate}} + \max\left( T_{\text{select}},\ \max_i T_{\text{tts}}(c_i) \right) $$
Because users spend \(T_{\text{select}} \approx 2\text{s}\) reading and deciding, we cache the audio during that window, so:
$$ T_{\text{tap-to-sound}} \approx 0\text{ms} $$
candidates.forEach((cand, i) => {
fetch(ttsUrl(cand)) // hits ElevenLabs via our /tts proxy
.then(r => r.blob())
.then(blob => {
audioCacheRef.current[i] = URL.createObjectURL(blob)
})
})
Savings vs. no pre-warming: \(\Delta T \approx 700\text{ms}\) per turn. Over a 20-turn conversation, \(\sim 14\) seconds of accumulated waiting removed.
Emotion engine — the moat
Cloning a voice is easy now. Making an ElevenLabs cloned voice express emotion is what nobody else does for AAC.
Each emotion \(e\) maps to a voice_settings vector:
$$ \mathbf{S}_e = (s_e,\ b_e,\ y_e,\ v_e) $$
where \(s_e\) = stability (lower = more variation), \(b_e\) = similarity_boost (anchors the cloned identity), \(y_e\) = style, \(v_e\) = speed multiplier.
Selected profiles after 13 hand-tuned iterations:
$$ \mathbf{S}{\text{excited}} = (0.35,\ 0.80,\ 0.55,\ 0.98) $$ $$ \mathbf{S}{\text{warm}} = (0.45,\ 0.80,\ 0.40,\ 0.92) $$ $$ \mathbf{S}{\text{tender}} = (0.55,\ 0.82,\ 0.40,\ 0.88) $$ $$ \mathbf{S}{\text{neutral}} = (0.55,\ 0.80,\ 0.25,\ 0.92) $$
Critical constraint discovered empirically: \(s_e \geq 0.35\) for all \(e\). Drop below this floor and the cloned voice warbles. The Generator returns only the label \(e\) (from a closed vocabulary of 13); the backend looks up \(\mathbf{S}_e\) and passes it to ElevenLabs. Numbers are locked; expression is flexible.
Turn-taking state machine
A 2-state machine (Listening / Composing) with timer-driven transitions: Listening → Composing on a final transcript followed by \(\Delta t > 3.5\text{s}\); Composing → Listening when a candidate is picked and playback ends + a 500ms buffer; auto-return to Listening if idle \(> 120\text{s}\) with no taps.
AudioWorklet-level mic gating
Mic state is read synchronously in the worklet, not via React state:
worklet.port.onmessage = (e) => {
if (listeningRef.current && deepgramReadyRef.current) {
wsRef.current.send(e.data)
}
}
When listening is false, audio frames are dropped at the worklet level — they never reach Deepgram. No re-render lag, no echo from ElevenLabs playback feeding back, no room-noise pollution of memory.
Durability — surviving long conversations
Deepgram closes idle WS connections after \(\sim 10\text{s}\). During "My turn" no audio flows, so we send a KeepAlive every 5s (\(5\text{s} < 10\text{s}\)):
async def keepalive_dg():
while True:
await asyncio.sleep(5)
await dg_ws.send(json.dumps({"type": "KeepAlive"}))
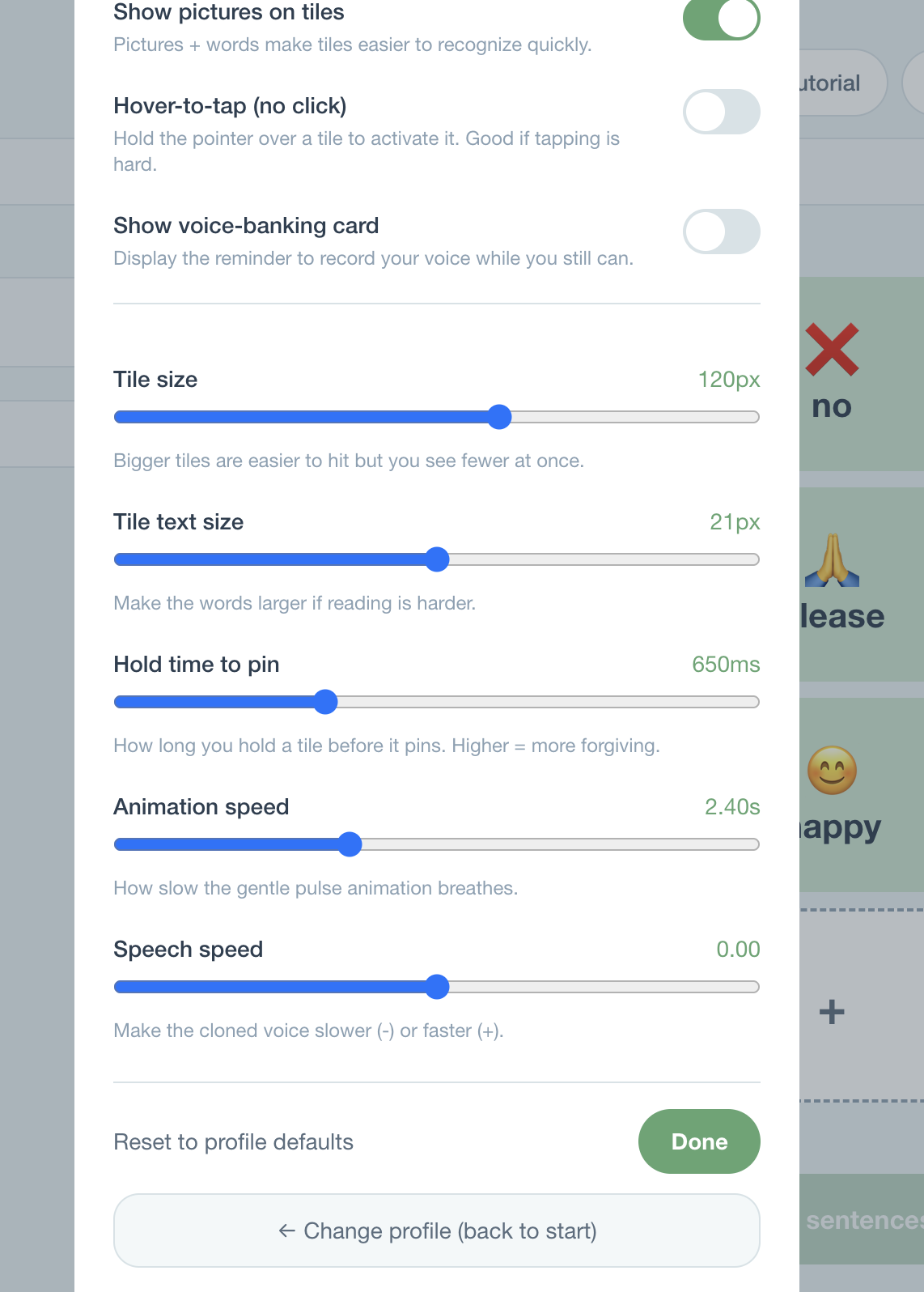
Dwell-click for cerebral palsy users
A progress value \(p(t) = \min(1,\ (t - t_0) / T_{\text{dwell}})\) with \(T_{\text{dwell}} = 1.1\text{s}\) by default, rendered with requestAnimationFrame. Reach \(p = 1\) to activate the tile — no physical tap required.
Per-profile feature differentiation
PROFILES = {
autistic: { symbolMode: true, longPressMs: 550, tileFontPx: 16 },
als: { showVoiceBanking: true, longPressMs: 700, tileFontPx: 18 },
aphasia: { symbolMode: true, emphasizeSuggestions: true, longPressMs: 650 },
cp: { dwellEnabled: true, dwellMs: 1100, tileMinHeight: 110 },
}
ALS gets the voice-banking prompt because voice cloning is most emotionally loaded for them — recording now, before speech is lost. Every value overridable in Settings.
🛠️ Challenges We Faced
- ElevenLabs cloned voices warbling at low stability. Early high-emotion profiles used \(s_e \in [0.15, 0.25]\) and warbled. Fix: floor stability at \(s_e \geq 0.35\), compensate with higher style and anchor identity with \(b_e \geq 0.80\).
- Deepgram dropping connections during composing. WS dies silently after 10s idle. Fix: explicit KeepAlive every 5s.
- Echo loop from speakers. TTS playback got captured by the mic and transcribed as a partner turn. Fix: AudioWorklet-level mic gating during my-turn + 500ms post-playback buffer.
- Profile differentiation felt cosmetic. Fix: built real per-profile features — picture+word tiles, ALS voice-banking flow, dwell-click for CP.
- Generator returning unreliable numeric voice settings. Claude's free-form numbers drifted out of range. Fix: Generator picks only a label \(e\) from 13; backend maps \(e \mapsto \mathbf{S}_e\) deterministically.
📚 What We Learned
- Voice cloning is the easy part. Emotion is the moat. Making a cloned voice feel requires hand-tuning, not auto-generation.
- Pre-warming is the cheapest latency win. Generate TTS while the user reads candidates and tap-to-sound feels instant.
- Real-time systems are 80% durability work. KeepAlives, heartbeats, mic gating — the difference between a demo and a product.
- AAC needs vary wildly even within one diagnosis. Profiles set defaults; Settings override everything.
- Empathy first, tech second. Every decision flowed from: would this make someone feel more like a person?
🚀 What's Next
- Deployment — Vercel + Render/Fly so anyone can try it
- Screen-reader ARIA pass — accessibility audit
- SLP partnership — speech-language pathologist review of the defaults
- Switch/scanning input — single-switch users (severe CP, late-stage ALS)
- Real user testing — paid co-design with AAC users from each of the four audiences
Cadence is a working prototype today — but the dream is that one day, someone who can't speak will look up from their tablet, hear their own voice say "I love you" with real warmth, and the person across the table will hear them. Really hear them. For the first time in years — maybe ever.
That's why we built this.
🌊
Built With
- anthropic-claude
- deepgram
- elevenlabs
- fastapi
- framer-motion
- javascript
- jsx
- python
- react
- redis
- vite
- web-audioapi
- websocket

Log in or sign up for Devpost to join the conversation.