-
-

Cadence Logo
-
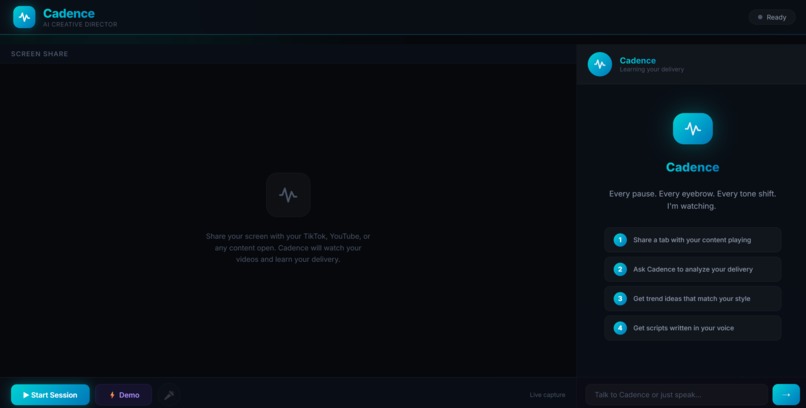
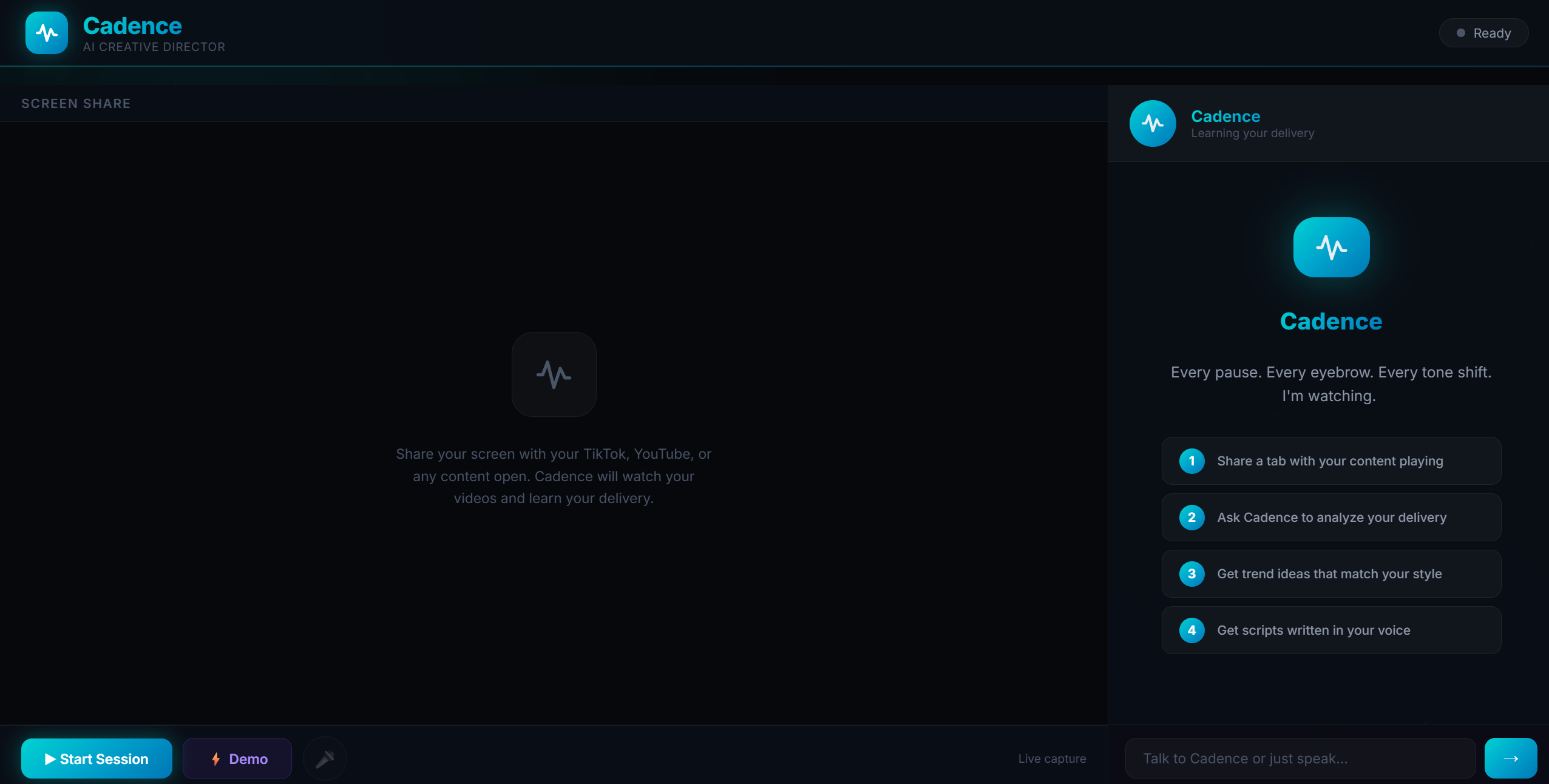
Home Page
-
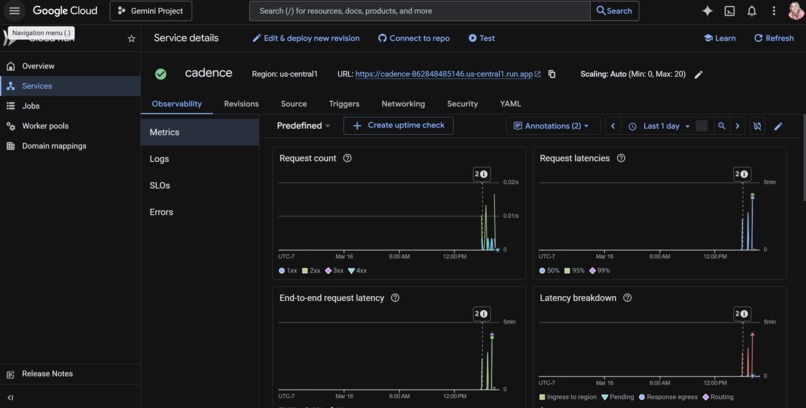
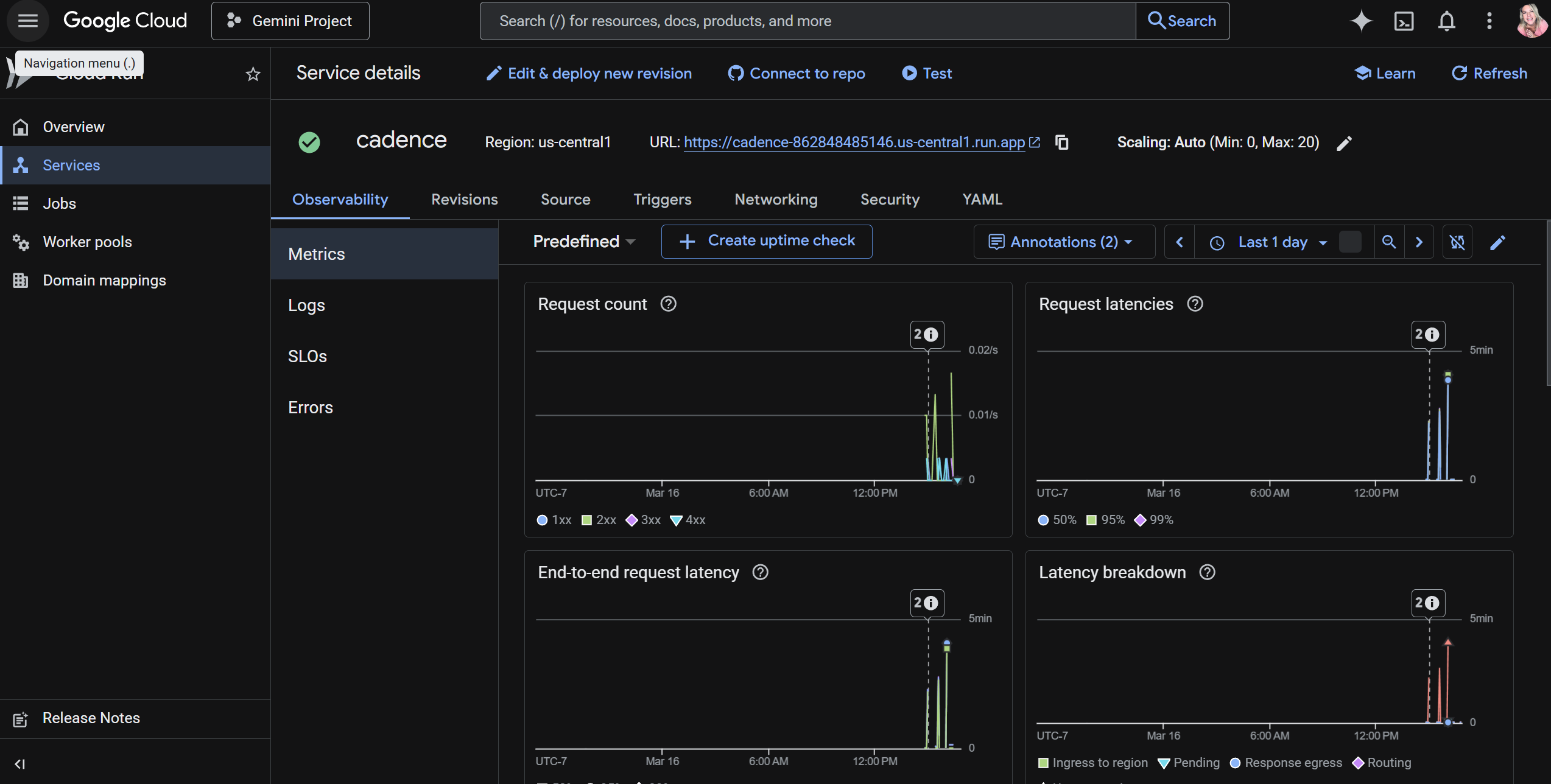
Proof of Google Cloud Deployment
-



Inspiration
I have a large TikTok following built on a very specific delivery style: deadpan sarcasm, heavy facial expressions, strategic pauses, rapid-fire pacing. The kind of performance that makes content work but is impossible to explain to a chatbot.
Every time I tried using an LLM to help write scripts, I'd spend 20 minutes trying to describe my style in words: "ok so I do this thing where I pause and raise my eyebrow right before the punchline, and my humor is dry, and I lean into the camera when I shift from facts to opinion..." The AI would nod along and then hand me something that sounded like every other creator on the internet.
The problem isn't that AI can't write. It's that AI has never watched me perform.
That's what Cadence solves.
## What it does
Cadence is an AI creative director that learns your delivery by listening to your actual content — not a text description of it.
You share your screen, play your videos, and Cadence listens in real-time through Gemini's native audio model. It picks up on things you can't put into a prompt: your pacing patterns, your humor timing, the emotional arcs you use in every video, the way you open with a deadpan hook and dissolve tension with a half-laugh.
It builds a persistent voice profile that gets smarter every session. Then it uses that profile to:
- Study your delivery patterns across multiple videos
- Scout trending content that matches your specific style
- Create full scripts written in your voice with line-by-line delivery coaching
## How I built it
The core insight was that Gemini's native audio model can process raw audio — not transcripts, but the actual vocal performance. I built a bidirectional streaming pipeline using Google ADK that sends mixed audio (microphone + tab audio from screen share) to Gemini in real-time over WebSocket.
Backend: Python/FastAPI server handling WebSocket connections, with Google ADK orchestrating the Gemini BIDI streaming session. Voice profiles are persisted as JSON and injected at session start so Cadence remembers creators across sessions.
Frontend: Vanilla JavaScript with Web Audio API. Three AudioWorklet processors handle mic capture, tab audio capture, and PCM playback — all running off the main thread for low-latency streaming.
The key technical challenge was getting the mixed audio pipeline right. The native audio model needs a single coherent audio stream, so I had to mix microphone input (boosted 1.5x) with tab audio from screen share (0.7x) into one PCM stream before sending it to Gemini.
## Challenges
- BIDI streaming quirks: Gemini's live audio API drops connections periodically and doesn't send
turnCompleteevents, so I built an auto-reconnect system with exponential backoff and timeout-based turn detection. - Audio-only model: The native audio model can't process video frames— only audio. Cadence analyzes video content entirely through what it hears, which turned out to be surprisingly effective for studying delivery patterns.
- Voice profile injection: Getting the model to actually use stored profile data when writing scripts (rather than falling back to generic content) required very explicit system instructions and structured profile injection.
## What I learned
The most valuable AI training data creators have isn't their scripts — it's their performances. The micro-expressions, the vocal inflections, the exact moment where humor lands and fear dissolves. That's the data that makes content feel like one specific person, and it's what AI has been missing.
## What's next
- Multi-modal analysis when Gemini supports video in BIDI streaming
- Collaborative sessions where creators can study each other's styles
- Export performance documents with delivery coaching for production use## Inspiration
ARCHITECTURE DIAGRAM IN LINKS BELOW PROOF OF GOOGLE CLOUD DEPLOYMENT IN LINKS BELOW
Built With
- docker
- fastapi
- google-adk
- google-gemini-2.5-flash-native-audio
- javascript
- playwright
- python
- web-audio-api
- websocket


Log in or sign up for Devpost to join the conversation.