-
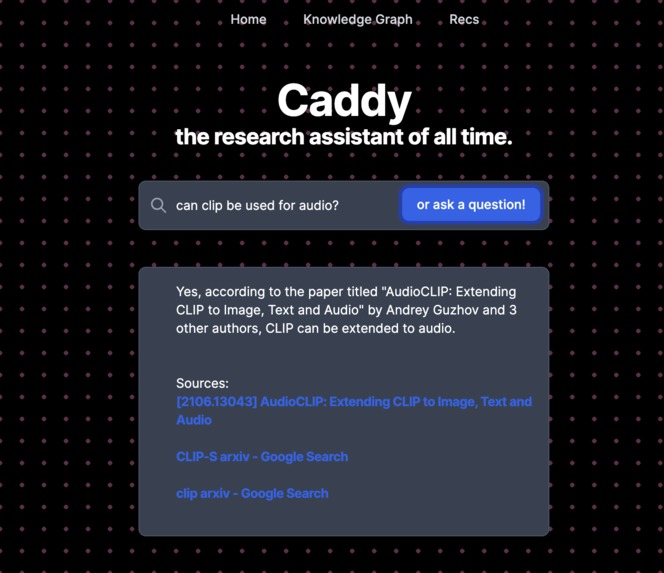
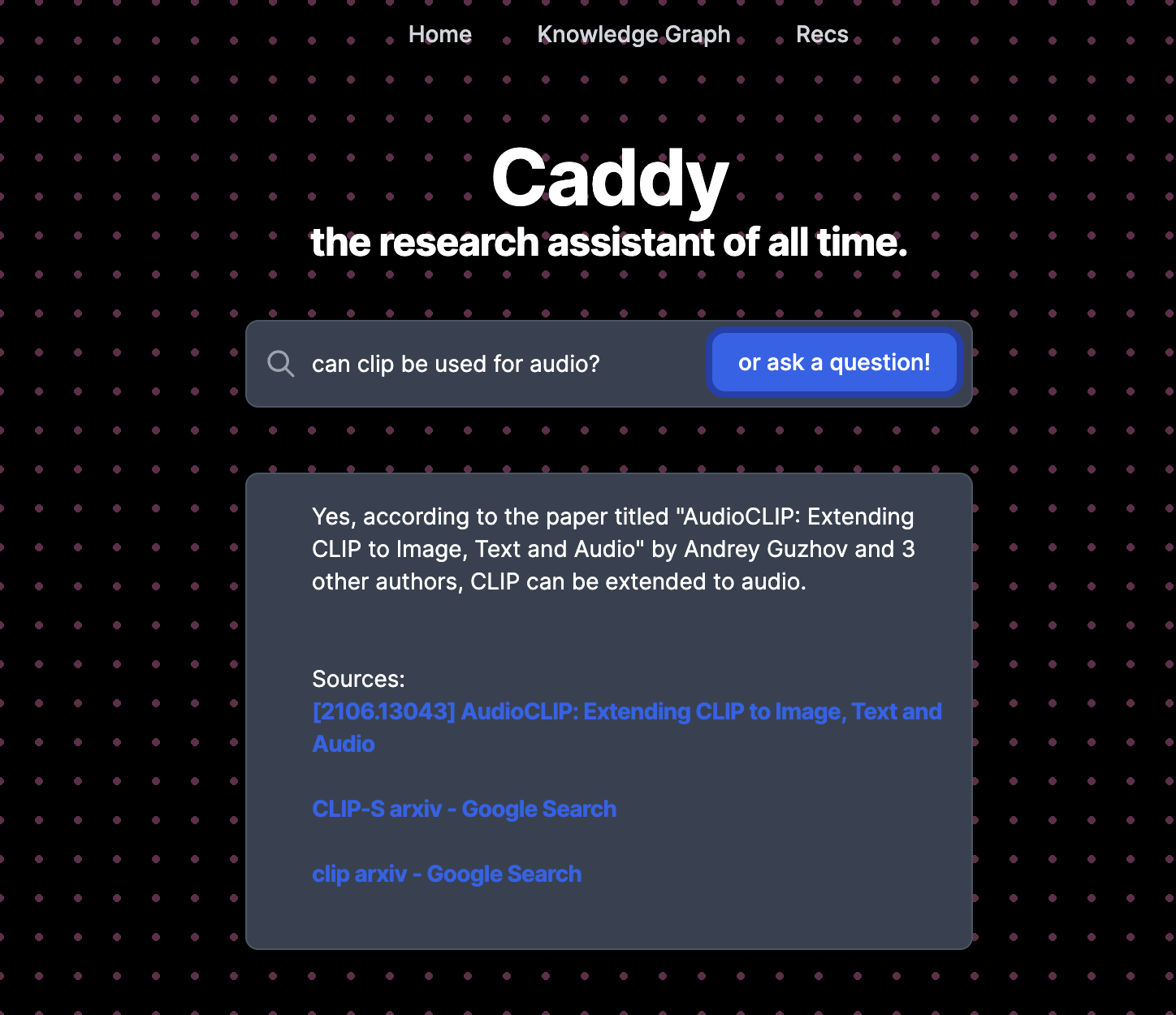
Question answer
-

Personalized recommendations
-
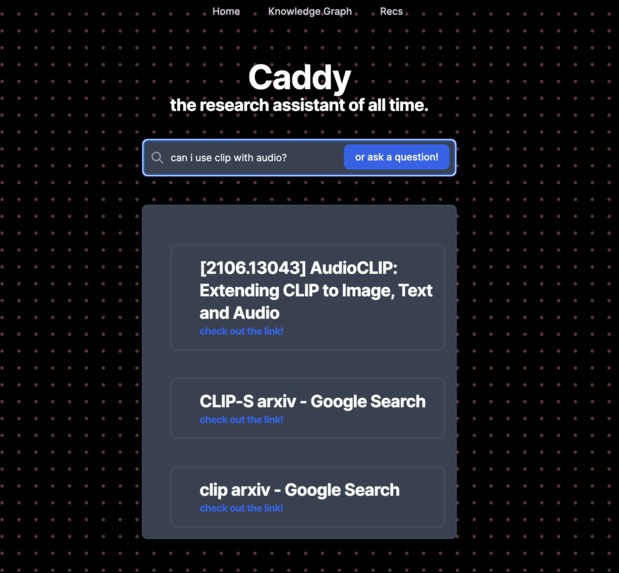
Semantic search using research papers you've read
-

Knowledge graph
-
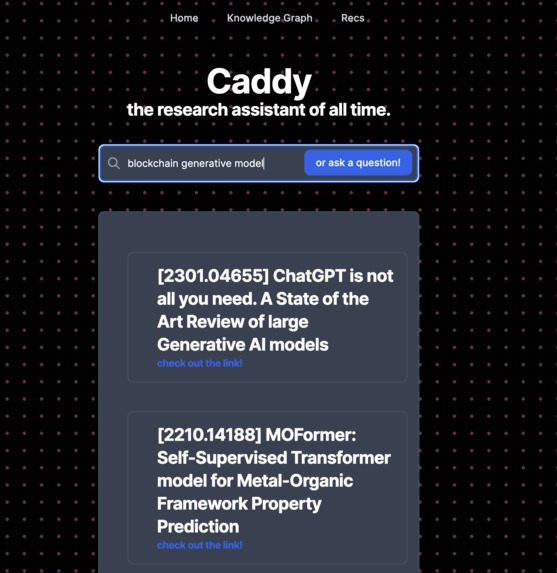
Semantic search using research papers you've read

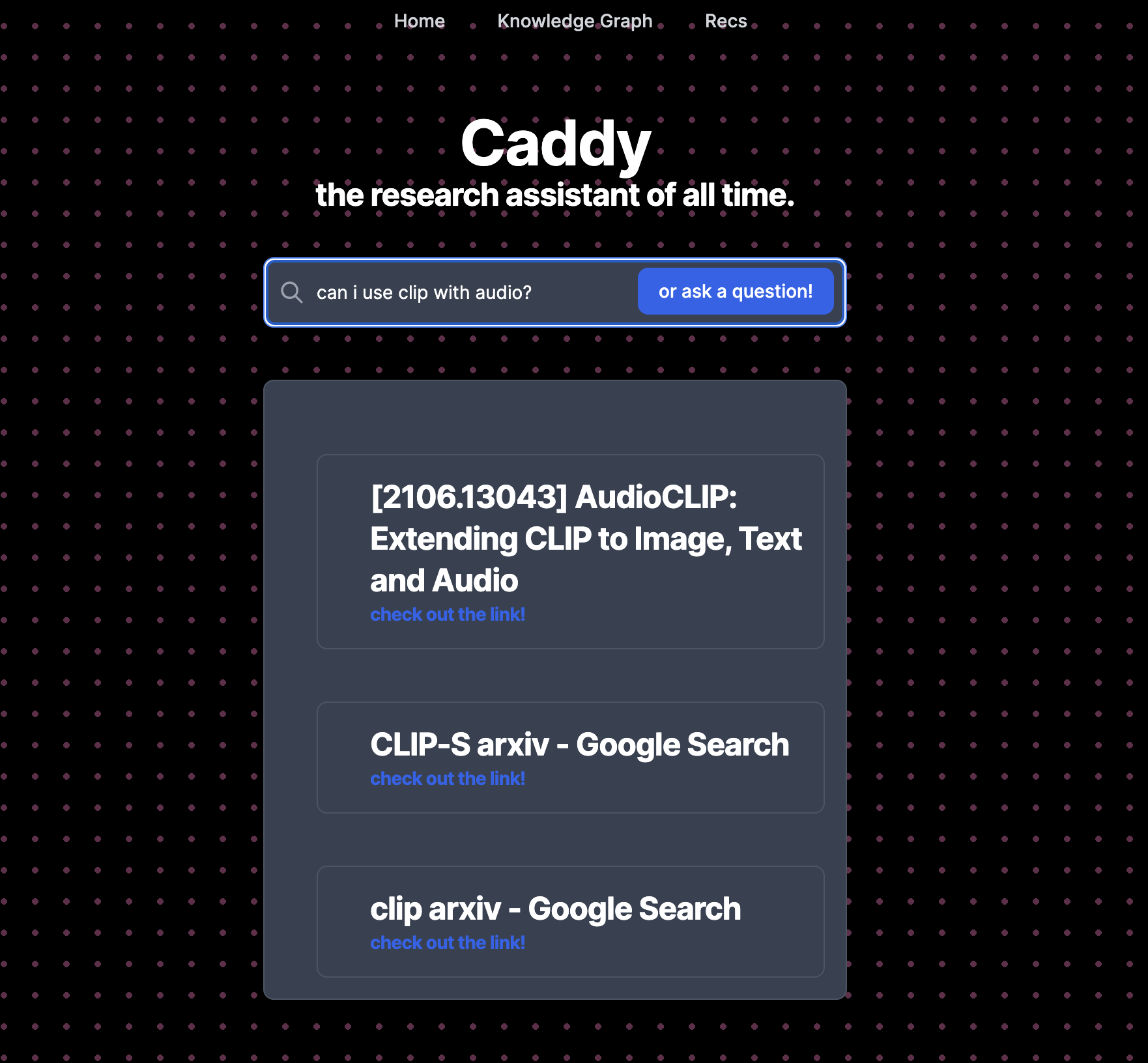

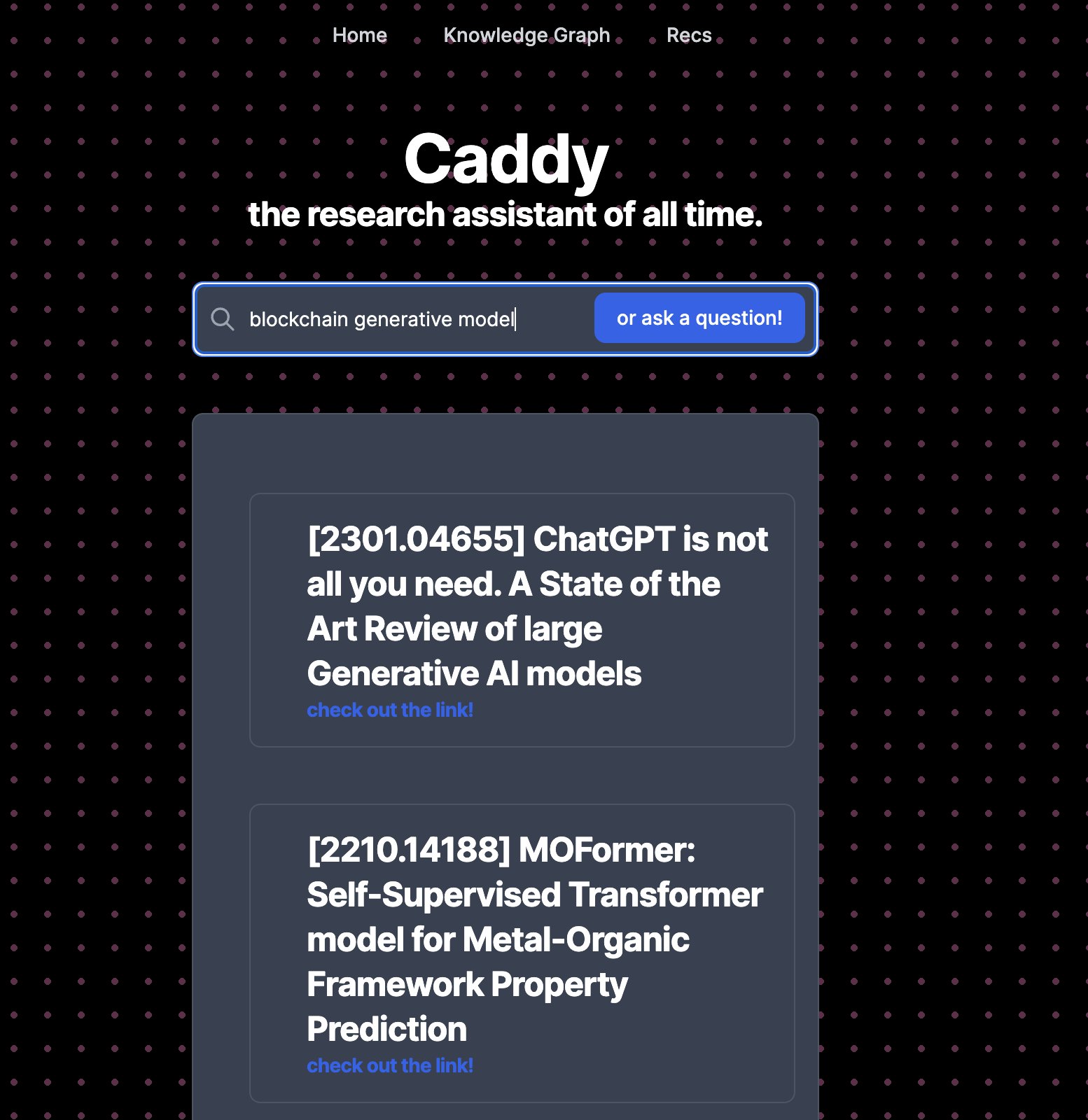
Inspiration
Imagine if recalling research papers and interesting blog posts was as easy as recalling memories -- based on semantics and relevant context instead of grasping for keywords.
Enter Caddy - an internet "caddy" for passing you the relevant research papers when you need it, acting as your companion to the semantic research web. Caddy uses your past papers and search history for fast knowledge retrieval, recommending new research papers, and a personalized and dynamic navigation to the literature landscape. Instead of reading something and forgetting about it forever, or going down a rabbit hole and losing track of those links, you'll be able to have this knowledge at your fingertips.
How we built it
- LLMs for knowledge retrieval (personal knowledge management)
- Pinecone vector DB
- Context-based injection for Q&A
- Retrieval-augmented generation for recall and semantic search
- NextJS, Tailwind, Vercel
Challenges we faced
LLMs have a lot of potential for improving knowledge retrieval and reinventing personal knowledge management, but the problem of being able to reference specific or non-public data is difficult. (Think "what is the last research paper I read about X?" and being able to have specific research papers you've read pulled up, as opposed to a fuzzy, general representation based on training set). Context-based approaches, such as adding in specific data in-context using prompt injection, is limited by number of tokens, while fine-tuning is expensive and burdensome to retrain every time the data updates.
Instead, Caddy uses retrieval-augmented generation to leverage embeddings of personal research data and LLMs for semantic search, combining pre-trained parametric (pre-trained seq2seq model) and non-parametric memory (personalized vector DB) for language generation.
Accomplishments that we're proud of
We'd personally love to use this for research and being able to pull from interesting things we've already read! Research paper rabbit holes, literature reviews, and finding "portals" on the Internet related to our interests and filtering out the relevant signal from the constant influx of new research.
What we learned
Embedding latent space as knowledge graph, integrating LLM prompt engineering with vector DB, retrieval-augmented generation.
What's next for Caddy
We're implementing more features for:
- Web crawling for research sites (recommending papers beyond ArXiv)
- Explore connected papers in visual graph and visualized clusters of research interests
- Functionality for blog posts, articles, etc. (in addition to research papers)
Built With
- huggingface
- nextjs
- openai
- pinecone
- pytorch
- tailwind
- vercel

Log in or sign up for Devpost to join the conversation.