-
-
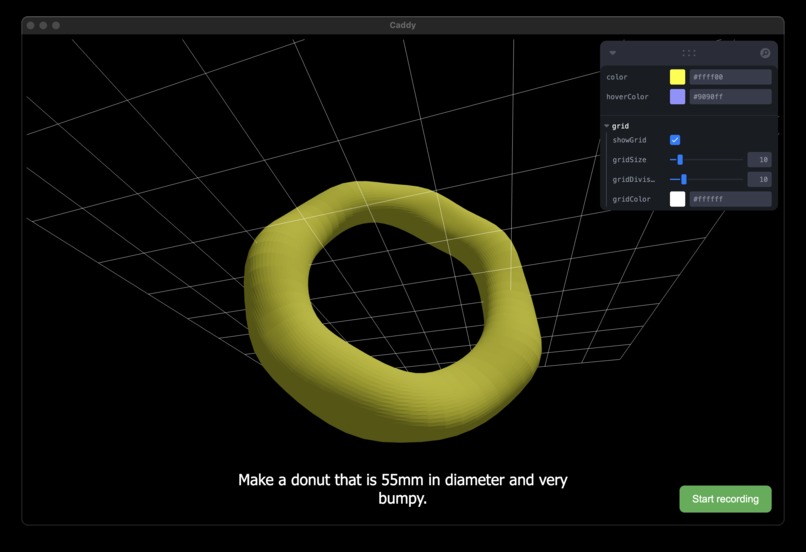
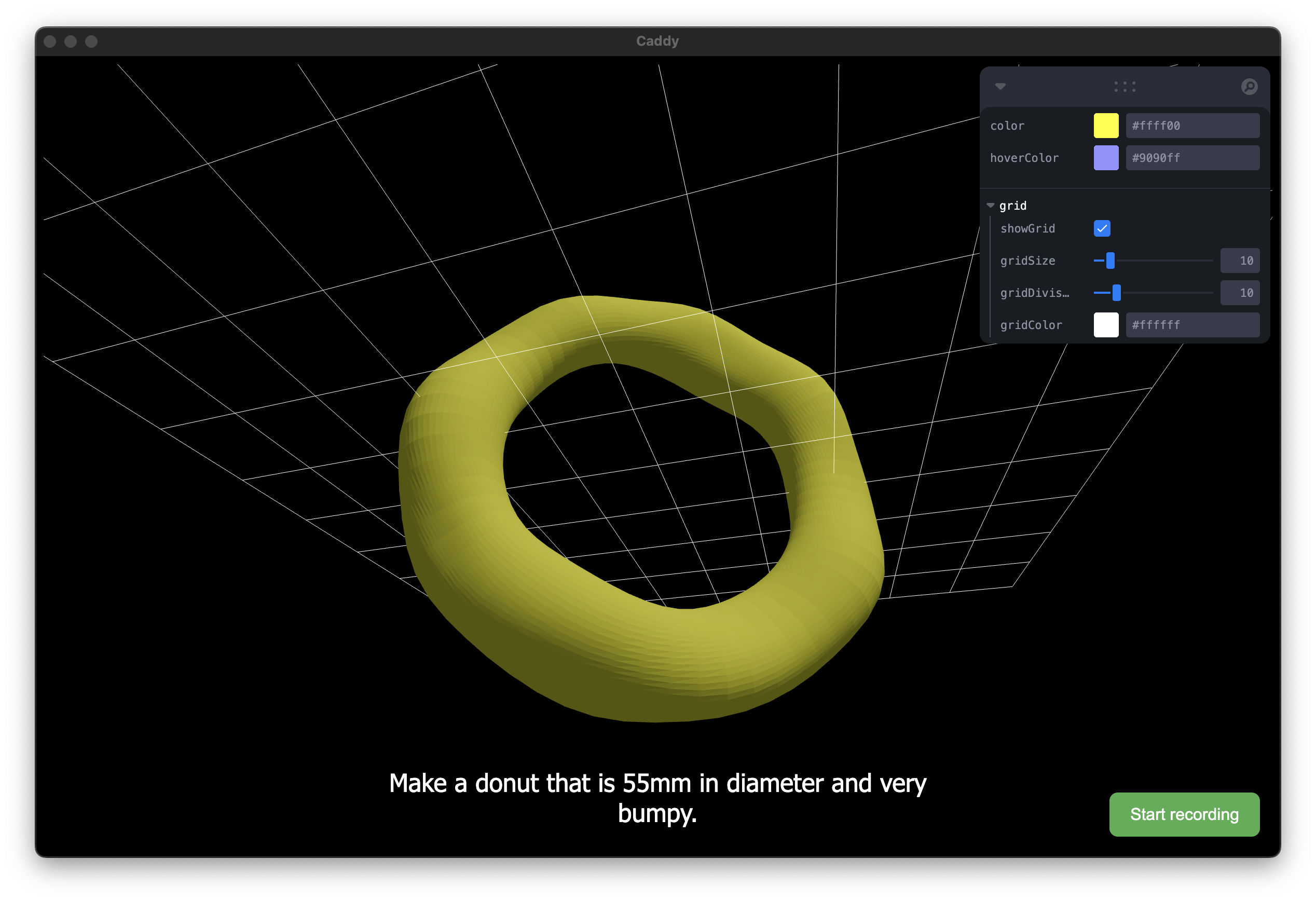
Make a bumpy (morphed) donut!
-
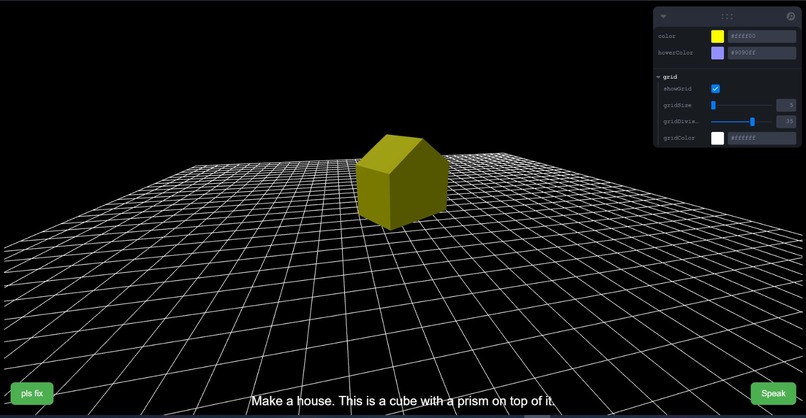
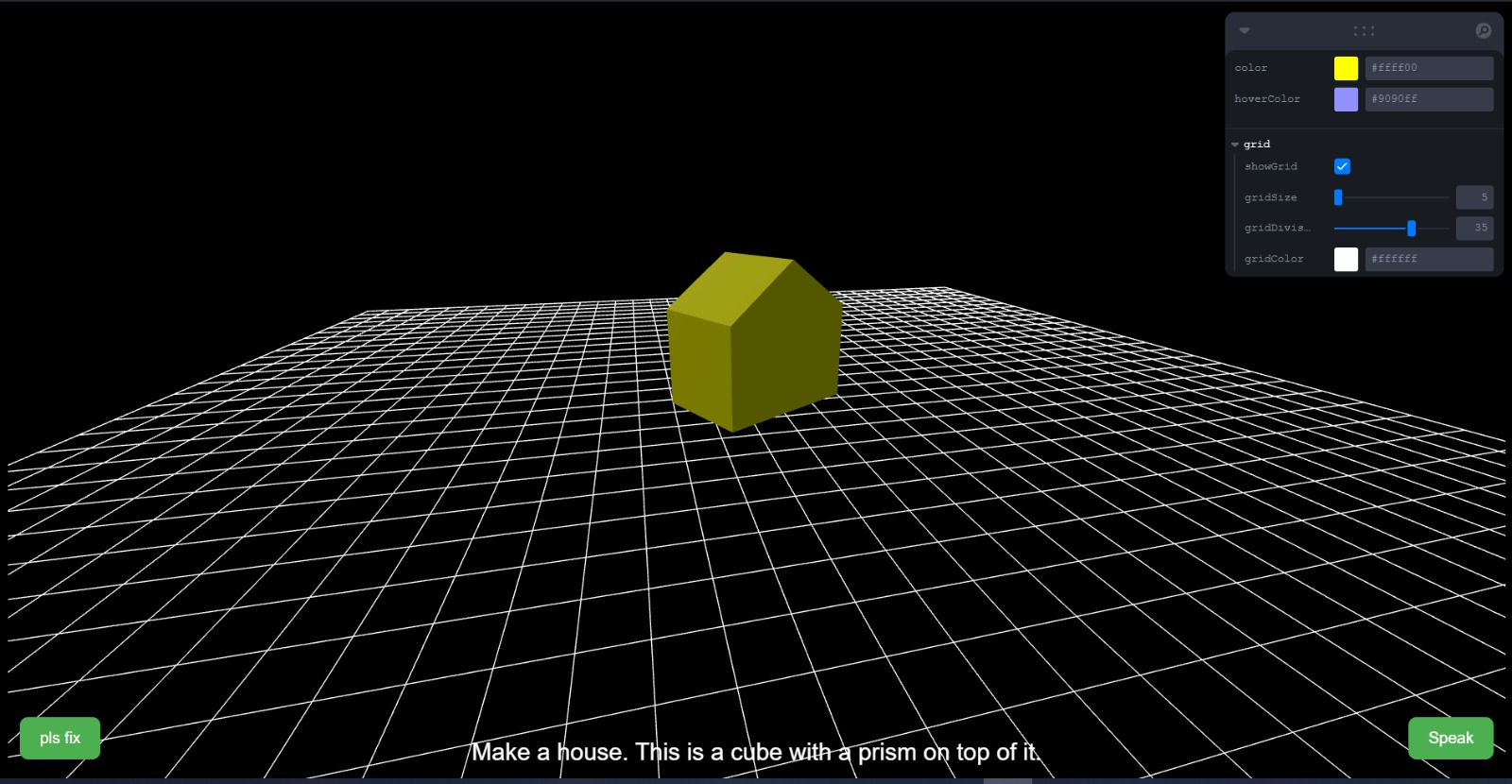
Build a house!
caddy
📌 **Team 28:** Adam Byrne, Victor Panayotov, Daniel KennedyInspiration
We built caddy as a “copilot for CAD”, when doing side projects and club competitions (e.g. rocketry/robotics/hardware) that we are part of in University; we use CAD a lot and got sick of opening big CAD applications for only a small job.
We saw dingcad which is a typescript scripting utility library for coding models, which got us thinking “models can write code” so why for a small part or simple geometry would we do it manually (although some tools have generative AI you still have to pay licences or have a specific architecture to use them). We aimed to let AI remove steps entirely from the process.
Also we were heavily inspired by voice enabled AI, thinking along the lines of a workbench assistant - as little interaction as possible while maintaining a good workflow. So we decided to make it a real (voice) chatbot - “I want a given structure with these metrics” which would output an STL to be sliced and then printed.
We are aware some companies have proprietary point-cloud generative models, but they are inaccessible to many and we were really excited to see how far we could push text generation. We are acutely aware that they don’t get it right every time so we incorporated an inspection and feedback step to the rendering for easy iteration (along with code generation fixing too).
What it does
It is a cross-platform desktop app which you can speak to via your microphone. It will use three.js to generate a mesh geometry - which is made more robust by embeddings we built from three.js examples allowing non-uniform shapes and cut/union operations. It will display the model in a 3D renderer which can be inspected or iterated upon using OpenAI Vision.
How we built it
- Typescript project in the electron-forge toolchain (meta framework for electron - web on native)
- Web scraped three.js examples and used the OpenAI text embedding API to allow a rudimentary but powerful RAG feature to allow few-shot generation
- We used the Whisper API to transcribe speech to text
- This text is put through the Chat Completion API to generate Three.js
- This code is executed in a sandbox (we inject Three.js imports here)
- Enforce constraints with system-prompts
- Retry on error with smaller model (e.g. it tried to import something we don’t allow i.e
fs)
- The geometry is returned as an STL (needed to slice then print from for a 3D Printer)
- This STL is rendered in a simple and pragmatic GUI
- Can be accepted/retry requested by OpenAI vision inspection
Challenges faced
- Typescript
- Webpack
- OpenAI APIs were new to us
- Whisper, Text Embedding, Chat Completion and Vision functionalities.
- IPC between web server and electron frontend
- STL validity - we used ASCII STL as the
omodels were very capable here
Accomplishments we are proud of
- It worked on all of our machines (Mac, Arch, Windows)
- We used a lot of OpenAI features
- The use case and the pitfalls (confusion/lack of examples) allowed us to use Whisper, Text Embeddings, Completions, Vision
- It actually worked (we generated a banana and a slightly unsuccessful ice cream)
- Bumpy doughnut that used some
morphfunctionality from embedded examples - We also generated a house! (we tuned our prompting to allow stacking/geometry connections)
- Bumpy doughnut that used some
What we learned
- Don’t pick Typescript for a ~30hour hackathon
- LLMs can generate STLs
- We could use
o1-previewinitially and usegpt-4o-minifor smaller fixes (saving time and money) - We could automate the “that looks good” using Vision API which removes frustration from the process if shapes are not coming out as expected.
Future work
- As models improve so will the tool, its value-adds will only become more robust in-turn which makes it very valuable to users
- Since it is electron (react frontend and express web server) it can be deployed as a web app too
- It could be integrated with either a slicing library or an existing slicing app for specific printers/mills and the process would be even simpler.
- Intermediate steps: we could leverage the shared embedding spaces that allows model that allows them to be multi-modal; mapping from textual “knowledge” → image representations and back again
Built With
- electron
- openai
- puppeteer
- three.js
- typescript
- webpack

Log in or sign up for Devpost to join the conversation.