-

-
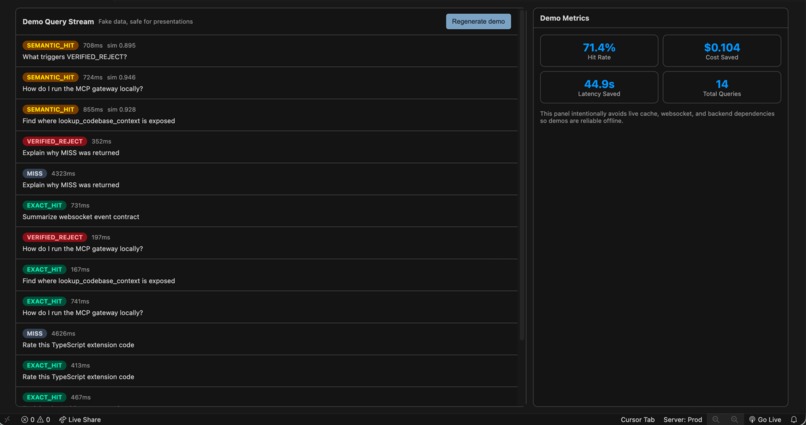
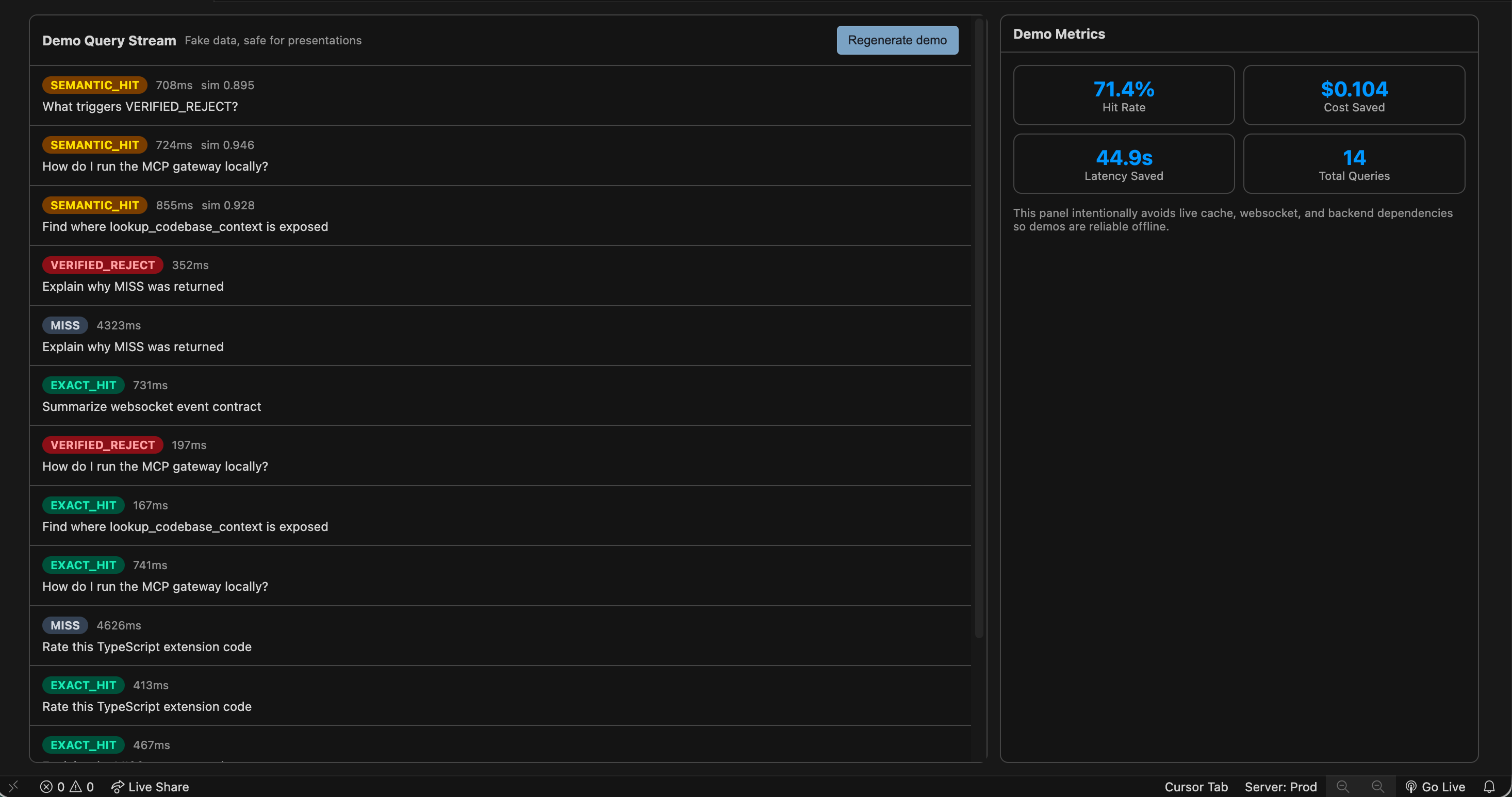
-
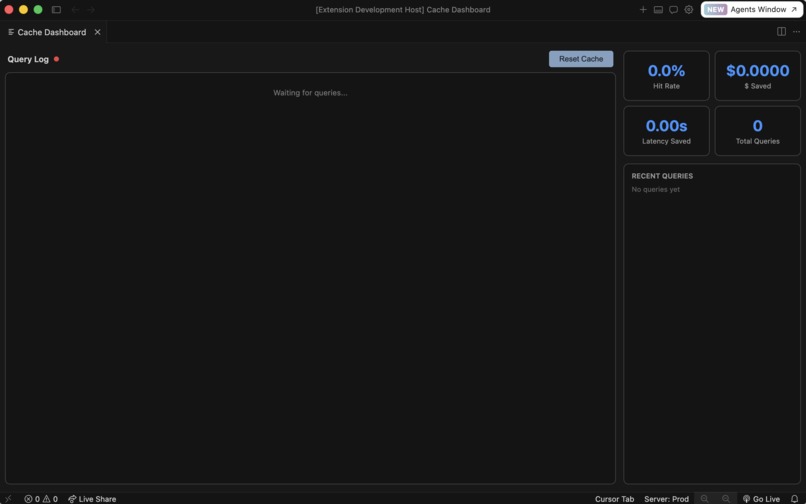
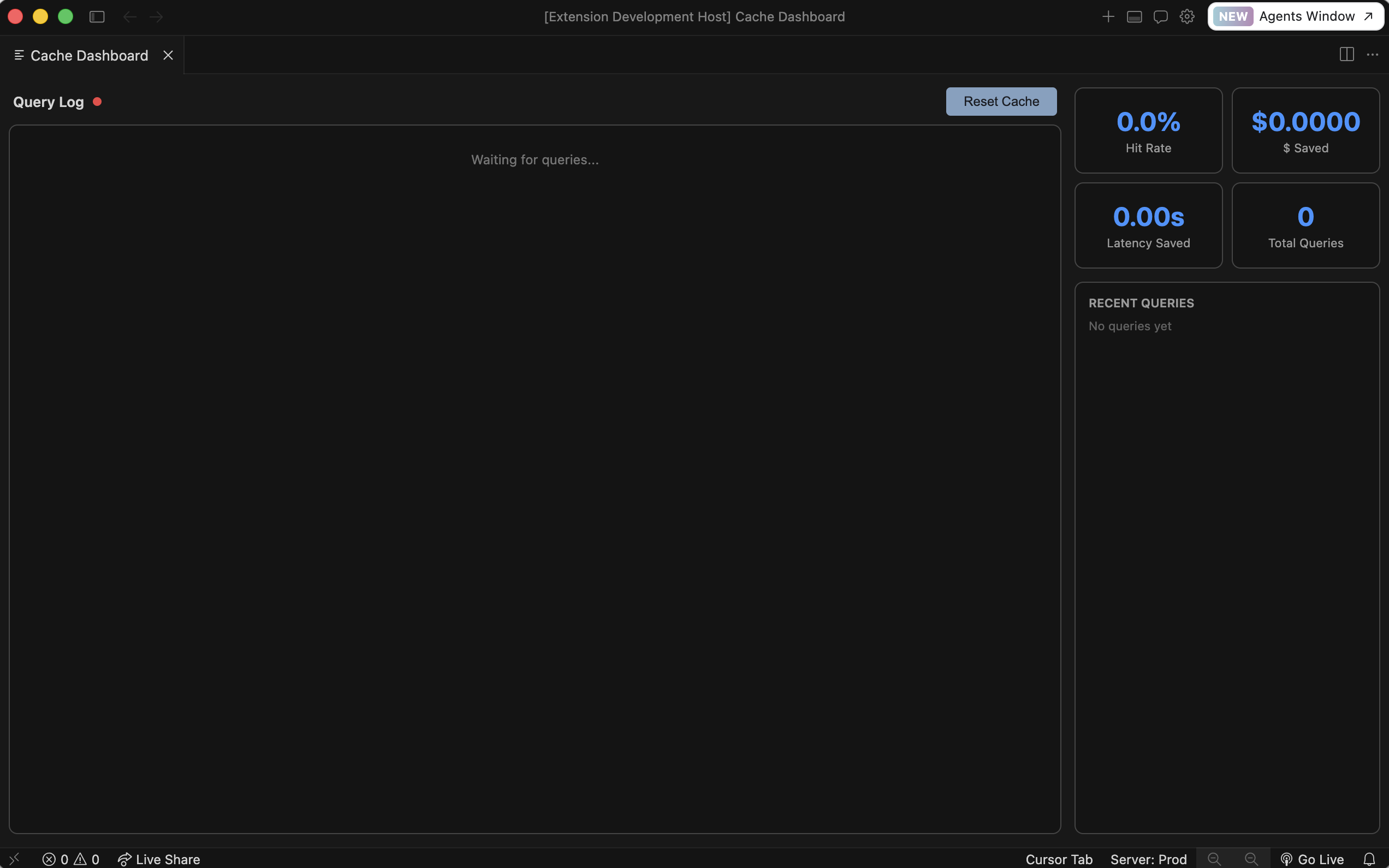
Main dashboard to track hit, misses, and savings.

Inspiration
Cursor agents repeat the same codebase context fetches: same intent, slightly different wording, same expensive round trip. Every redundant call costs money and slows the loop. We wanted a layer that sits invisibly in between and absorbs the repetition.
What it does
We intercept every lookup_codebase_context call from Cursor at an MCP gateway. For each query we:
- Ask a semantic cache whether we already have a good answer.
- On a strong match, return in milliseconds (your “under 5 ms” target on hot paths when the cache and embedder are warm).
- On near-misses—high embedding similarity but possibly wrong intent—we run a CLōD verifier (yes/no on whether the cached context still answers the new query). That catches “authentication” vs “admin authentication” without blindly serving the wrong snippet.
- On miss or reject, we forward to Nia, insert the result, and keep the dashboard honest. A Cursor extension subscribes to a WebSocket from the gateway and shows hits, misses, rejects, and savings in real time so the behavior isn’t a black box.
How we built it
TypeScript MCP server in front, Python FastAPI cache behind it, and Clod for verification. A Cursor extension with a live WebSocket dashboard showing hits, misses, and savings in real time.
Challenges we ran into
The verifier threshold tuning was harder than expected for example, a query about "authentication" and "admin authentication" looks similar but need different contexts. Getting responses without killing the hit rate took most of our time.
Accomplishments we're proud of
- Being able to use new tools like Clod and Nia, caching at two layers simultaneously without either knowing about the other.
- Observable system: WebSocket + extension makes hit rate and savings something you can see during a demo, not infer from logs alone.
- Contracts-first hackathon glue: ports, payloads, and statuses shared via CONTRACTS.md so three runtimes could integrate without endless coordination.
What we learnt
- Treat threshold + verifier tuning as a first-class workstream, not a polish step at the end.
- Embedding similarity ≠ user intent; the verifier is the difference between “clever cache” and “wrong answers fast.”
What's next for CacheForge
Future developments for CacheForge would be centered on using it in a team environment. Including a shared cache, multi-repo support, and a cost dashboard over time.
Built With
- clod
- nia
- typescript




Log in or sign up for Devpost to join the conversation.