-
-
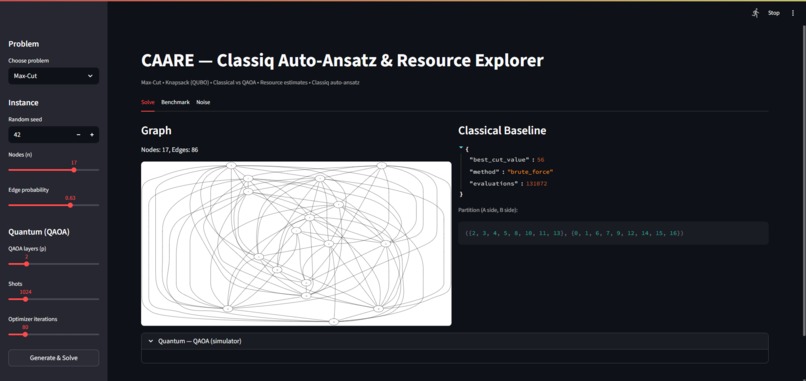
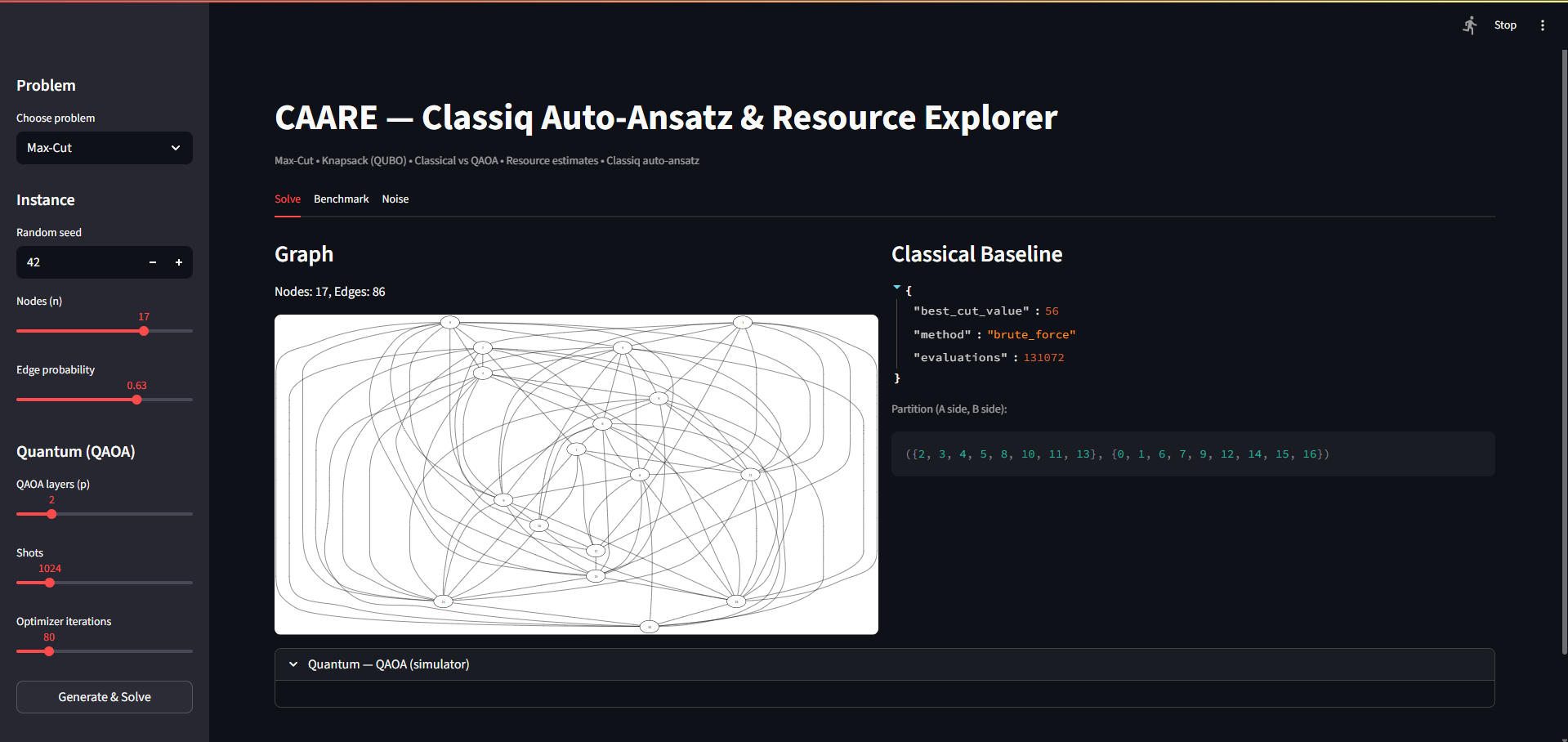
Main graph of Max-Cut
-
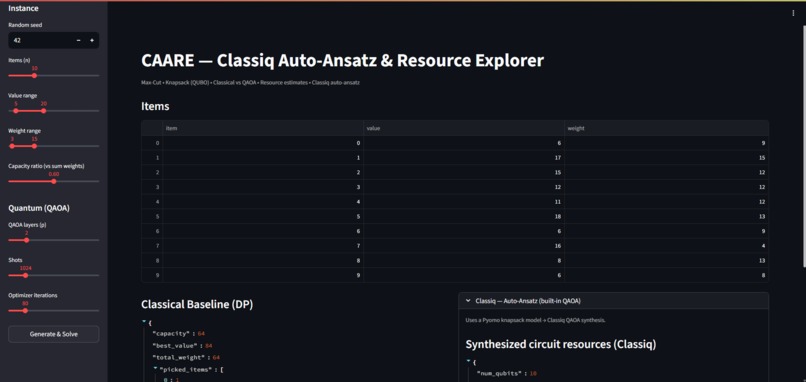
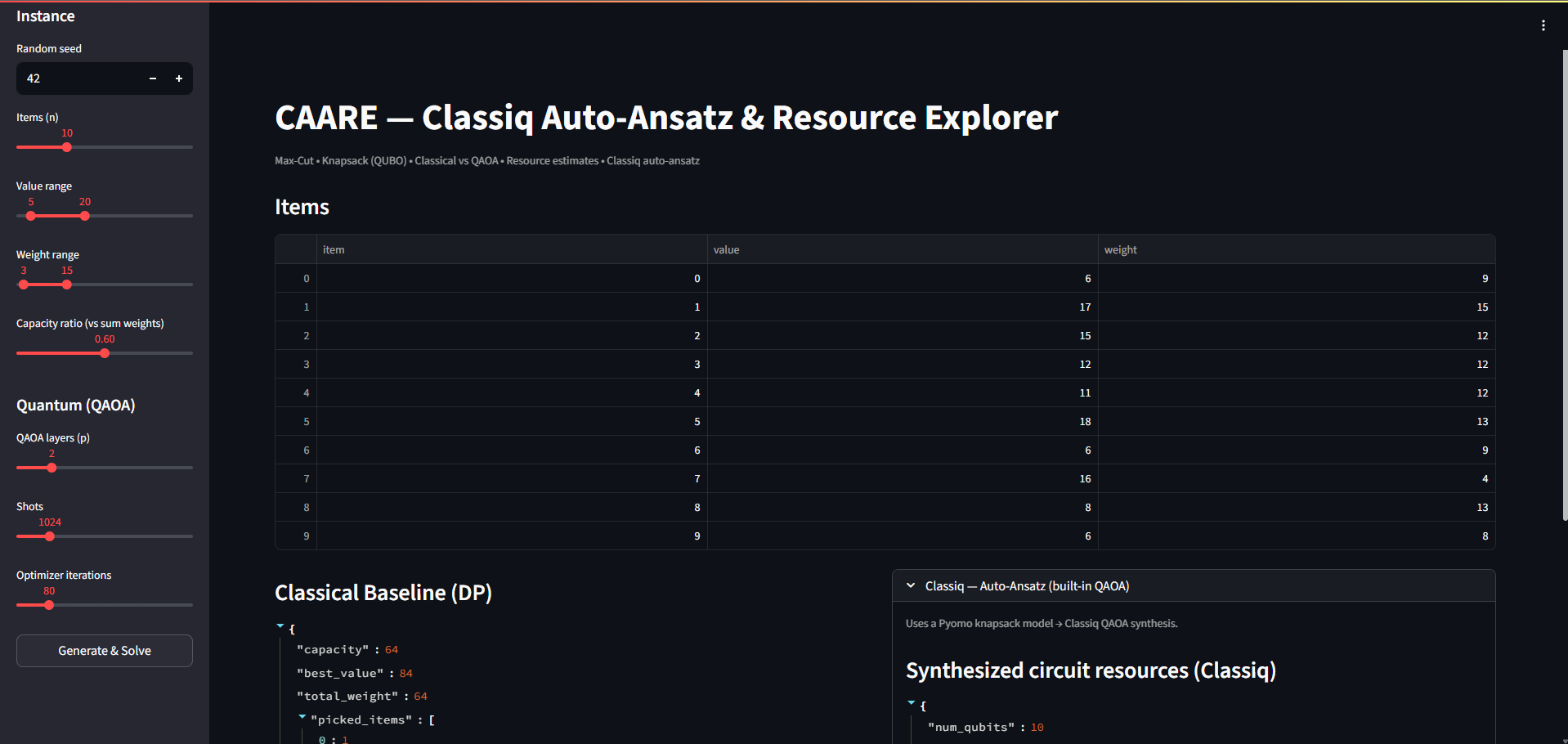
Main screen of Knapsack
-
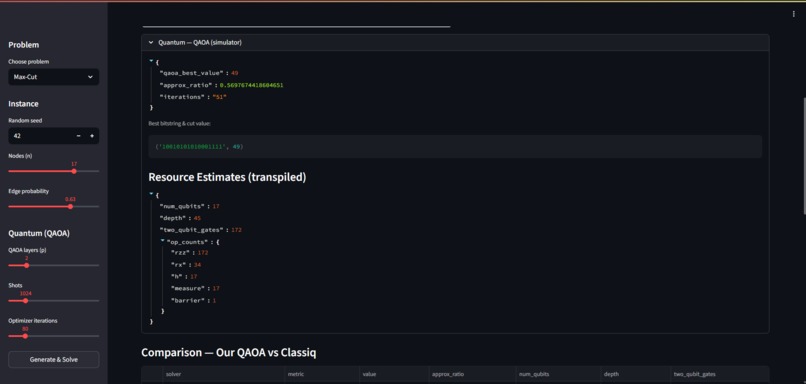
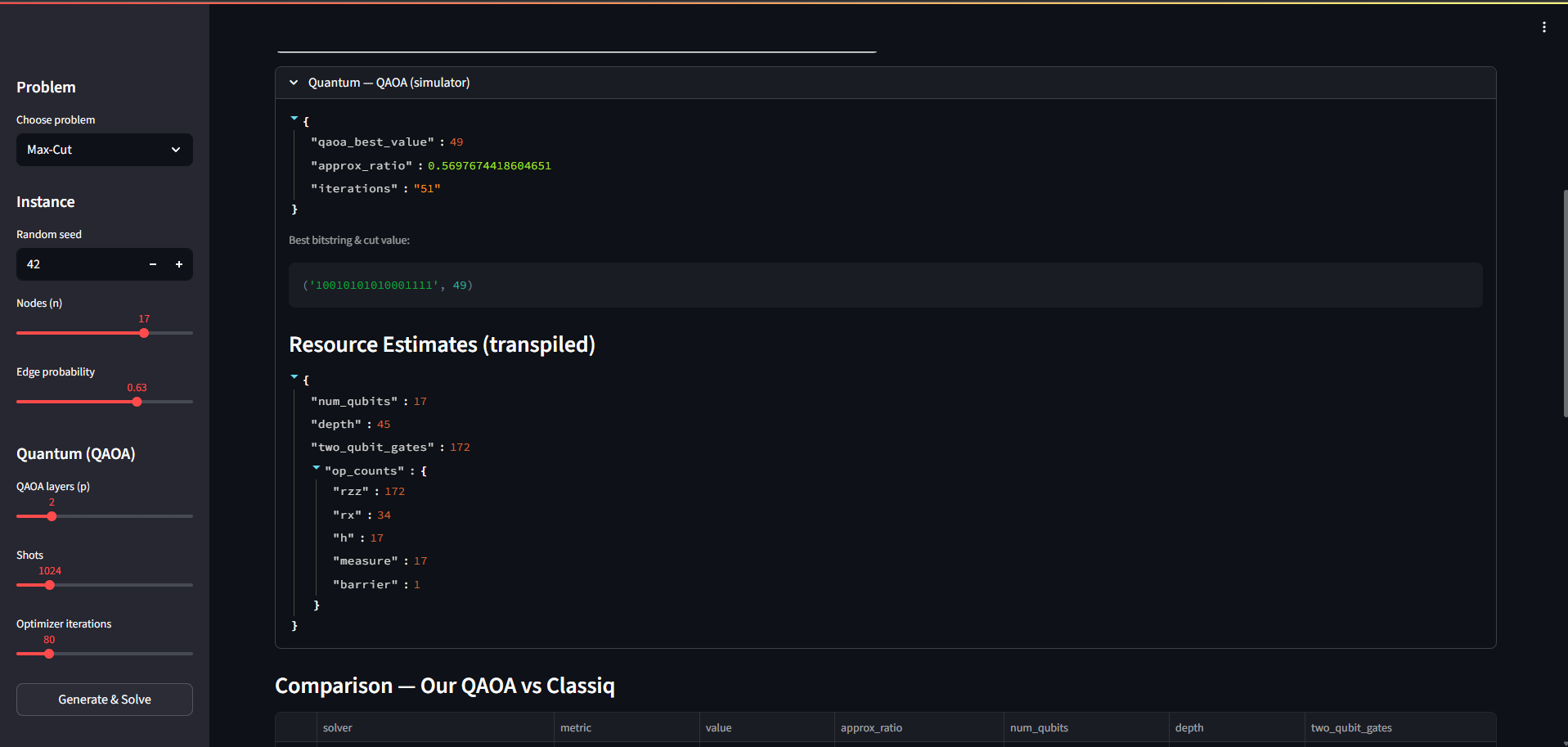
Data of resources required
-
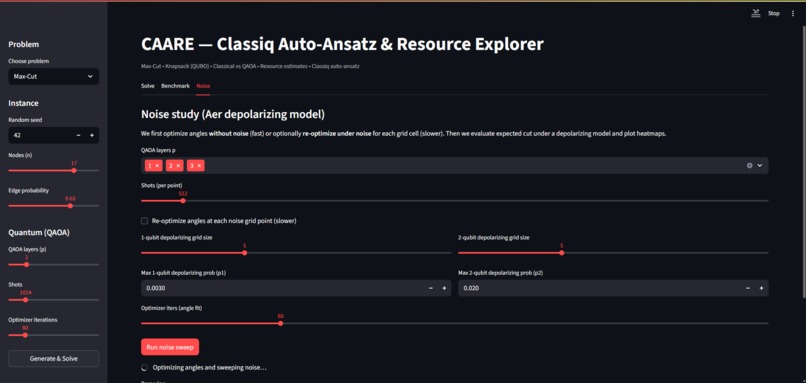
Parameter selection for Noise
-
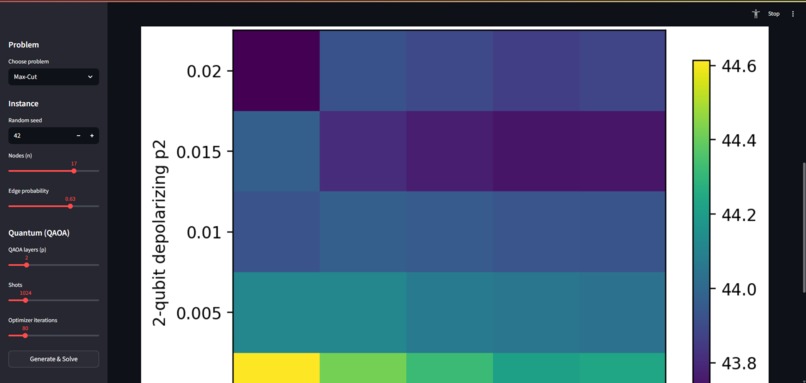
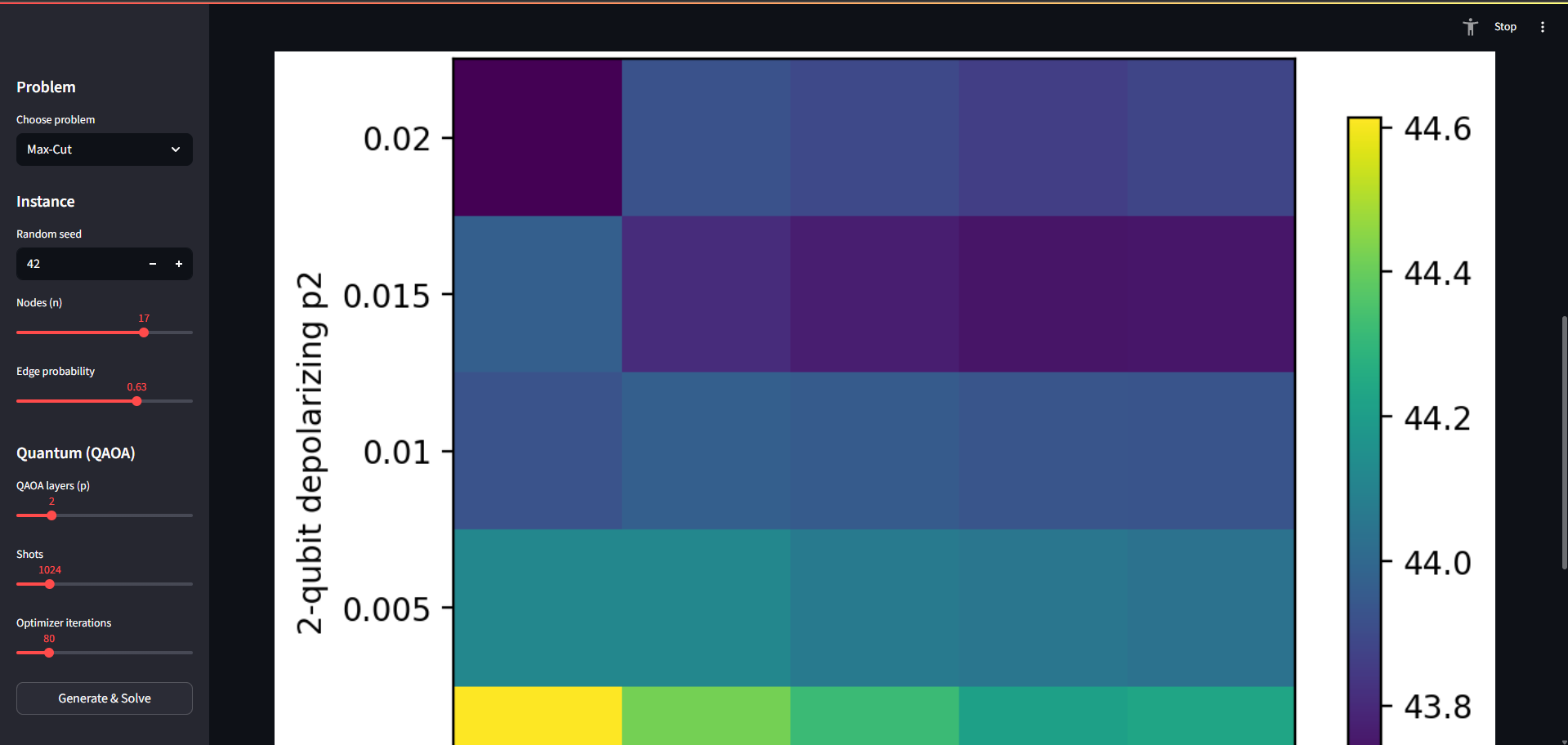
Heatmaps for Noise
Inspiration
Quantum is exciting, but teams keep asking the same question: “Is it worth it for my problem on near-term hardware?”
I wanted a tool that makes this answer visible and quantitative. So I made a tool to compare a clear QAOA baseline with an auto-synthesized ansatz (Classiq), and surface the things that matter in the NISQ era, depth, two-qubit gates, noise sensitivity, and time-to-solution, without needing real hardware.
What it does
- Supports Max-Cut and Knapsack (QUBO) with reproducible instance generation.
- Runs QAOA on Qiskit Aer with tunable layers \( p \), shots, and optimizer iterations.
- Computes resource estimates via transpilation:
num_qubits, depth, two_qubit_gates. - Integrates Classiq SDK:
- Build a Pyomo model to auto-ansatz synthesis to resource metrics.
- Optional sampling when a Qiskit circuit is returned.
- Build a Pyomo model to auto-ansatz synthesis to resource metrics.
- Auto Compare Summary: side-by-side table + bullet insights (ours vs. Classiq).
- Noise study: heatmaps over 1-qubit and 2-qubit depolarizing noise; optional re-optimize under noise.
- Benchmarking: sweep \( p \) to show quality vs. cost curves.
How it was built it
- Frontend: Streamlit (tabs, expanders, charts, progress bars).
- Modeling: NetworkX (Max-Cut graphs), Pyomo (Max-Cut & Knapsack formulations).
- Quantum stack: Qiskit Aer simulator; custom QAOA circuit builder (cost as ZZ, mixer as RX); SciPy COBYLA for angle optimization; Qiskit transpile for resource counts.
- Classiq integration:
construct_combinatorial_optimization_model+QAOAConfig/OptimizerConfig; robust circuit unwrapping (handles tuple/list/SDK variations) and graceful fallbacks when a Qiskit object isn’t returned. - Noise lab: Aer
NoiseModelwithdepolarizing_error, grid sweeps, optional re-optimization; heatmaps with Matplotlib. - Resource reasoning: if two-qubit counts are missing, I show analytical estimates for Max-Cut QAOA:
$$ \text{RZZ gates} \approx p \cdot |E|, \quad \text{CX-equiv} \approx 2p \cdot |E| $$
Challenges
- SDK variability: different Classiq builds returned tuples or non-Qiskit representations; sometimes 2-qubit counts were missing so I wrote defensive unwrappers and fallbacks.
- Auth & API codes (401/400): handled login prompts and informative UI messages.
- Streamlit reruns: prevented losing state by storing the generated instance in
st.session_state. - Optimizer differences: some SciPy builds lack
nit; normalized tonfevwhen needed. - Performance vs. fidelity: re-optimizing angles under noise is realistic but slow → added a switch and progress bars.
- Transpile accounting: ensuring meaningful 2-qubit metrics across native vs. decomposed bases.
Accomplishments
- A clean end-to-end workflow: classical baseline ↔ QAOA ↔ Classiq auto-ansatz ↔ resources ↔ noise ↔ benchmarks.
- Auto Compare Summary that turns raw metrics into quick, actionable insights.
- Noise heatmaps with optional noise-aware reoptimization, great for teaching and feasibility studies.
- Robust Classiq glue code that works across SDK versions and still provides value when circuits aren’t directly convertible.
- Multi-problem support (Max-Cut + Knapsack) with consistent UX.
- Simple public sharing (ngrok URL + QR) for live judging.
What we learned
- Two-qubit gates dominate practical cost; mapping and noise matter more than raw algorithmic elegance.
- Auto-synthesized ansätze can be competitive or lighter in specific metrics; having a transparent baseline (hand-rolled QAOA) makes the trade-offs clear.
- Reproducibility (seeds, cached angles) is essential for fair comparison and fast demos.
- Building useful quantum tooling is as much about engineering around edge cases (SDK, transpilers, reruns) as it is about algorithms.
What's next for CAARE
- More problems: MIS, Max-k-Cut, portfolio/CVaR, routing.
- More algorithms: VQE/CVAR-QAOA, parameter-shift gradients, warm-start strategies.
- Richer noise models: amplitude/phase damping, readout error; device-specific noise pulls.
- Real hardware runs: optional submits via IBM Runtime when credentials are present.
- Auto reports: export a PDF/HTML “experiment card” (plots + metrics + settings).
- Data import: load custom graphs/instances (JSON/CSV) for apples-to-apples comparisons.
- Ansatz search: meta-heuristics over mixer/cost structures with multi-objective scoring (quality vs. depth vs. 2-qubit).


Log in or sign up for Devpost to join the conversation.