-
-
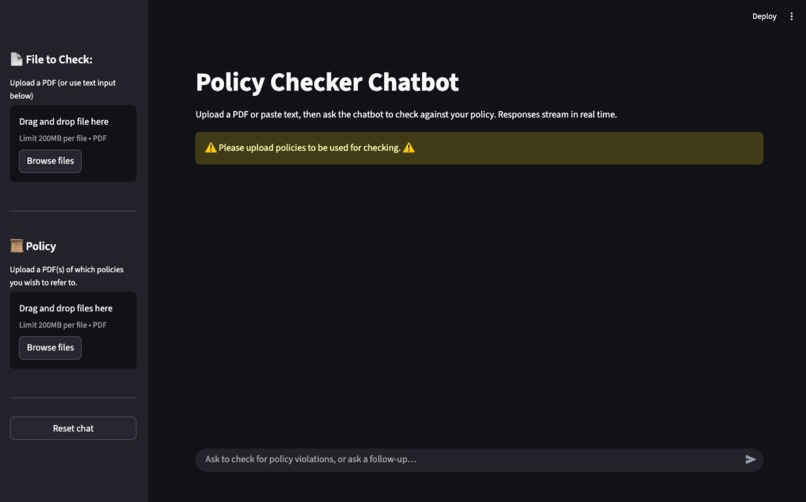
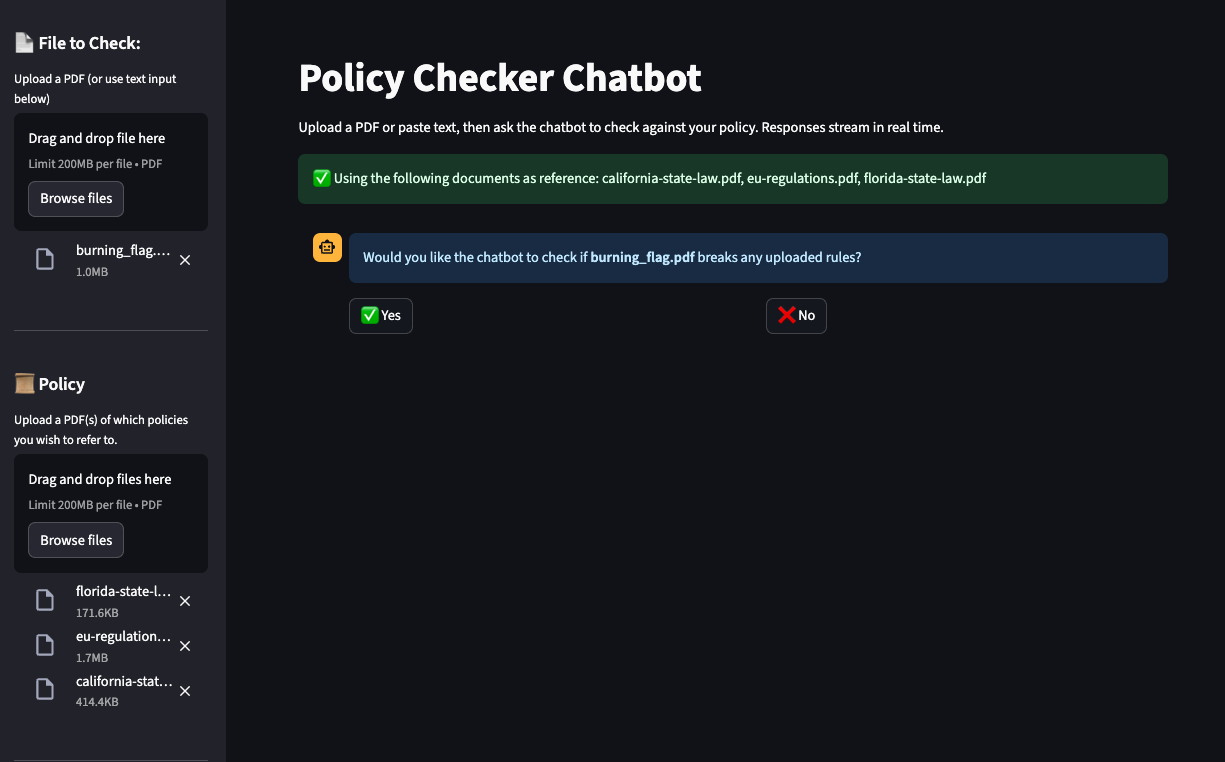
User is prompted to upload policies as rules
-
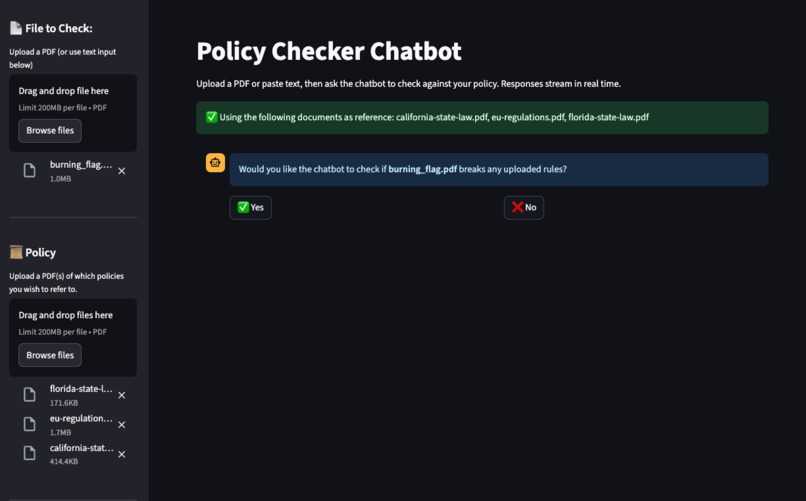
User is prompted on whether to process their own documents or not
-

Model response to one of TikToks sample data
-
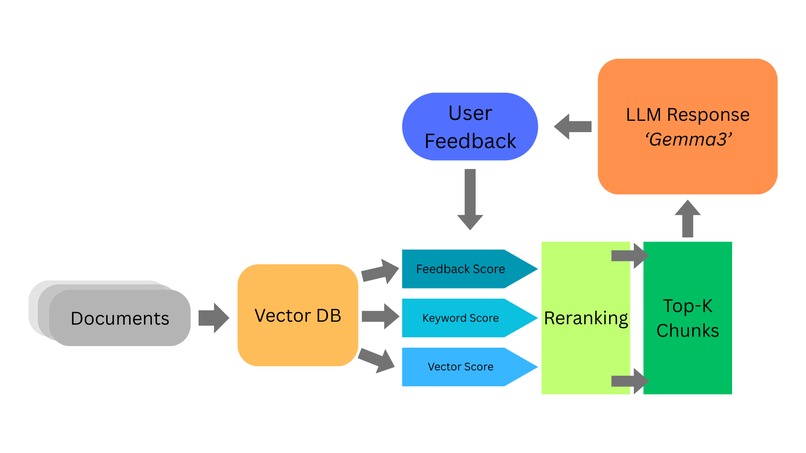
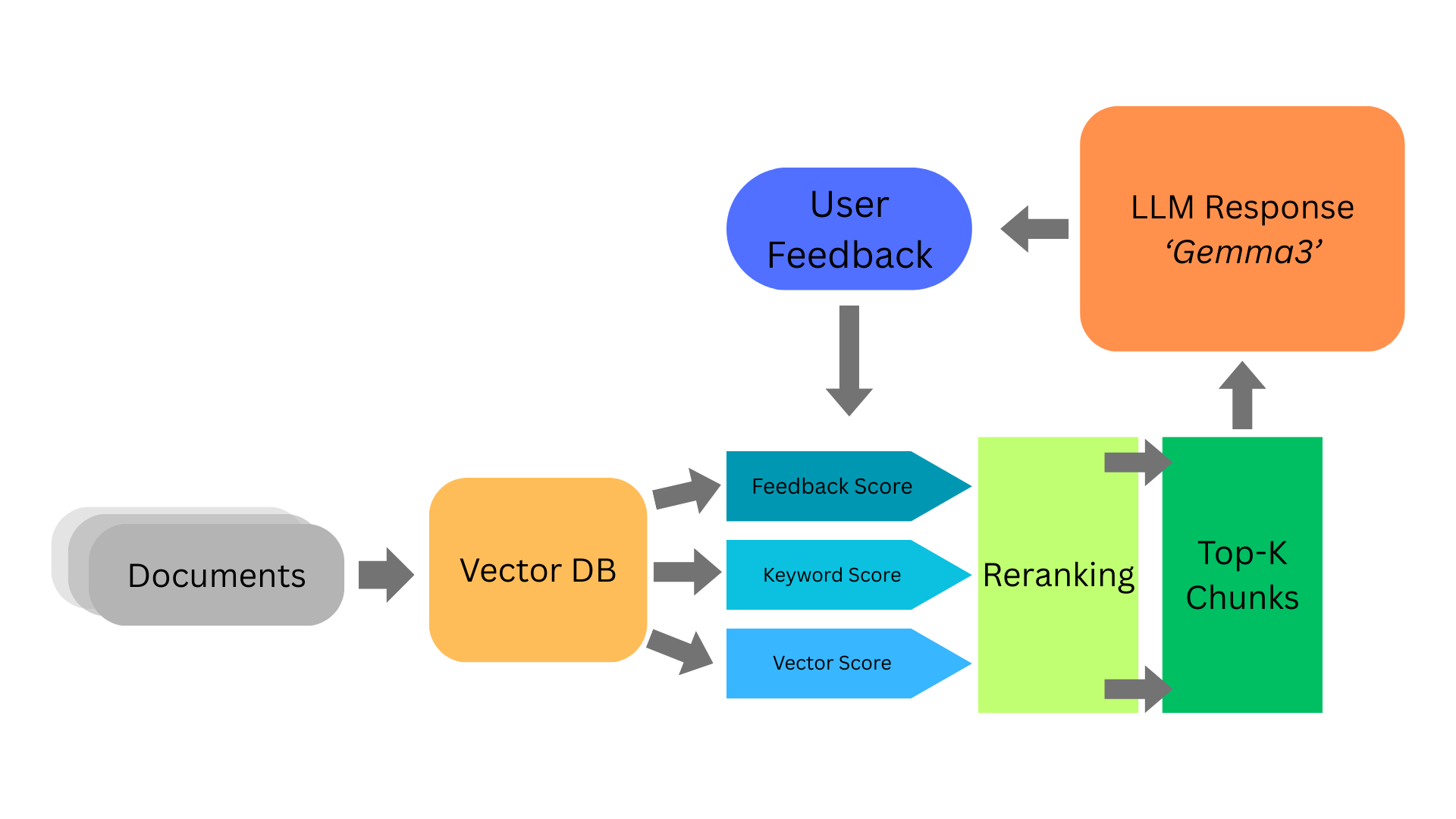
Rag Architecture

Inspiration
We repeatedly shipped features only to discover late-stage policy gaps. We wanted a fast, explainable way to check drafts against our own policy PDFs before review. LLMs are great at reasoning, but we needed grounded answers with citations and a consistent, structured output we could trust. We aimed for “drop a file, get a clear, citable answer in seconds.” Additionally, we hope that the users can play a part in training the model by providing valuable signals to the LLM training.
What it currently does (as seen in code)
- Upload one input PDF and multiple policy PDFs in the sidebar.
- On first upload of an input PDF, asks if you want an automatic compliance check; otherwise you can type questions in chat.
- Calls the trained LLM with an optional abbreviation-expanded prompt.
- Streams a readable reasoning preview, then renders a structured answer with implications and results
[ {law, reasoning, highlight, supporting_text, confidence} ]. - Maintains chat history with both user prompts and stored JSON answers for persistent re-rendering.
How we built it
Frontend
Streamlit UI with chat history, structured rendering, and smooth streaming UX.
RAG pipeline:
- Sentence tokenizing and chunking
- ChromaDB vector database populated from
rag_chunks.json. - Embeddings via Ollama
mxbai-embed-large. - Hybrid search approach: utilizing vector scores, keyword scores via BM25 & feedback scores
- Cross encoder reranks the chunks based on their adjusted scores
- Top‑k context assembly from nearest chunks. ### Human feedback loop:
- After LLM response, users are prompted to provide thumbs up or down
- The rating is added into another collection such that the rating can be fed back into the feedback scores whenever a similar query is met.
Reasoning + JSON:
- Generation with gemma3 via Ollama’s /generate.
- Strict prompt schema that demands valid JSON (no code fences).
- Robust parsing with retries: json.loads → brace‑substring recovery →
ast.literal_eval. - Validation rules ensure non-empty implications, results, reasoning, and numeric confidence.
- PDF ingestion: pypdf text extraction with graceful fallbacks for tricky pages.
Challenges we ran into
- JSON determinism at scale. Even with a strict schema, edge prompts produced stray prose or code-fenced JSON. We built a 3-step parser (json → brace-substring → literal_eval) plus validation rules to fail fast and retry.
- Determining if LLMs are truly hallucinating or referring to the source documents.
- Knowledge gaps for us as individuals. As only two of us are working on this, we had to fill our gaps with tutorials and research.
- Being too ambitious with features and ending up with lack of time.
Accomplishments that we're proud of
- Nice frontend
- Robust JSON handling. Practical recovery path for messy model outputs plus a validator that guards against empty or low-signal payloads.
- Performance-aware caching. @st.cache_resource for the vector collection and @st.cache_data for PDF extraction keep the UI snappy.
What we learned
- Micro-states matter in chat apps. Small flags like check_prompt_shown_for prevent accidental duplicate actions and confusing re-prompts.
- Performance is very important when running such chatbot like apps.
- Utilised methods in document search and retrieval to gain better accuracy
Built With
- chromadb
- ollama
- python
- sentence-transformers
- streamlit
- tokenizers
- transformers




Log in or sign up for Devpost to join the conversation.