-
-
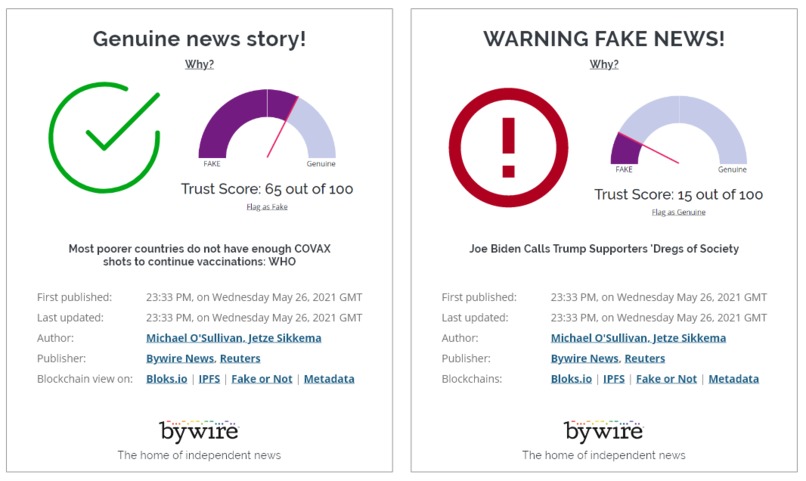
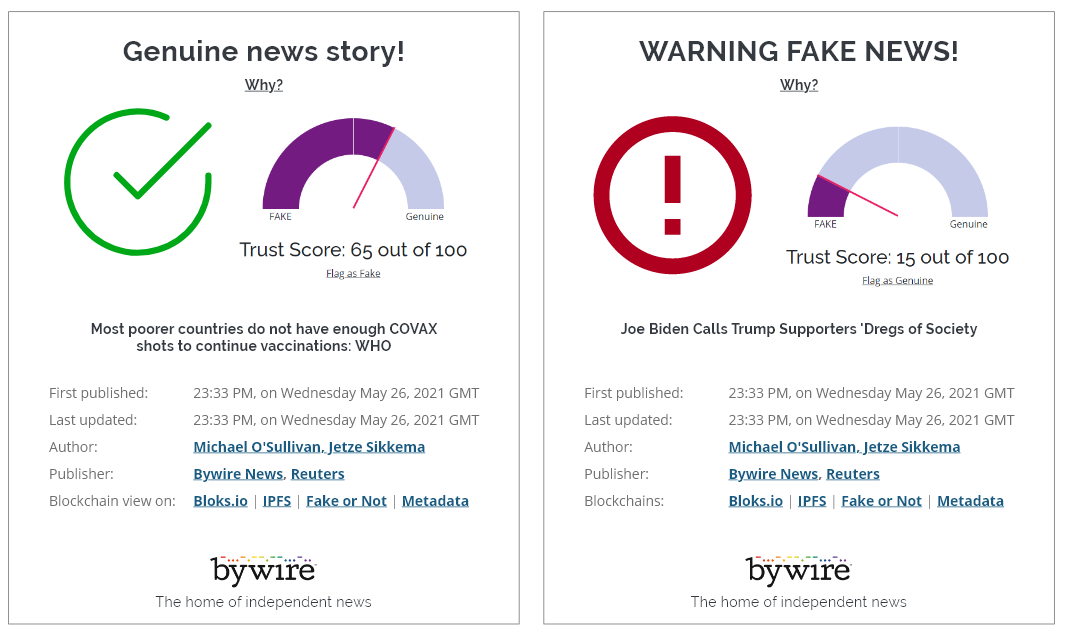
Our Fake News and decentralized example certificate
Inspiration
Bywire Disinformation Detection was inspired by the apparent omnipresence of fake news. Since bywire.news is an online publication where trust and quality of journalistic reporting is of critical importance we were inspired to find out if there are automatic ways of detecting fake news. Due to previous experience in accounting, where detecting falsified balance sheets is rather important, and which can be (in part) done using Benfords' law the thought arose whether we could use statistical measures to identify whether an article is trustworthy or not. While the ideas have been lying around gathering digital dust we never wrote any code to actually test which of them work or make them available to the public the hackathon was the catalyst to actually start implementing and testing them.
What it does
At the core the Bywire Disinformation Detector analyses text and translates an article to a feature matrix based on various neuro-linguistic programming (nlp) concepts. Key indicators are euphoria (is the article extraordinary positive/negative), emotional content (is the article designed to provoke fear or anger) and lexical complexity (is the text repetitive, what is the average word length, sentence length etc). This can be fed to either an heuristic model based on the current research in fake news detection or an artificial neural network. Both models enhance each other and improve our understanding of fake news. Since bywire.news stores all of it's articles on ipfs and the eos blockchain we added functionality to retrieve these articles by submitting the ipfs hash. The user interface consists of a rest-api where newspapers like bywire.news can plug in to so they can display on their website the trust score and the reasons why an article is distrusted and it consists of a fact checking website that displays the information neatly using the same rest api.
How we built it
Part of the project was building a rest-api using python flask a webfrontend using html5, javascript and php. This was rather straightforward. For the algorithmic part we used standard datascience approaches: we first looked up some review articles on the various approaches to fake news detection, used this to turn any news stories into a sensible feature vector, scaled this in order for gradient descent learning algorithms to function better. And finally fed it to the heuristic algorithm where it was tested against some known fake news and real news and the keras/tensorflow which fortunately handles a lot of the complexity in machine learning, like selecting appropriate error measures, parameter dampening,
Challenges we ran into
The major challenge is that the topic is huge and highly relevant but our time and development team very limited, especially since we became aware of the hackathon in the second week of June. Another challenge is to generate training data for the ann. The bywire.news database contains around 150k unique publications of which only little parts could be fed without additional cost into the expertai api and had to be labelled by hand to allow the creation of training data. For this we introduced configurable switches and an api endpoint so users can label whenever they disagree with our trust score.
Accomplishments that we're proud of
We could build a working prototype within 10 days time. It was able to classify a number of high profile news stories correctly as fake. For example the stories Biden Calls Trump and Supporters “Dregs of Society” and Pope Francis endorsed Donald Trump for president. are correctly classified as fake while Juneteenth: After decades, Opal Lee finally gets her day off and HSBC offers sub-1% mortgage as interest rate war intensifies are correctly identified as trustworthy.
What we learned
What's next for Bywire Disinformation Detection
There are many steps that we will have to make simultaneously.
- Business
- Introduce a subscription model for access to the server
- Allow notification of uploaded news stories, together with topic identification so bywire can report on it.
- Marketing
- Try the algorithm out on high profile stories like pizzagate and qanon.
- Algorithm
- Generate training data - Good quality training data is one of the things we most lack at the moment. This should highly improve the quality of the machine learning used.
- Switch to a convoluted neural network - Using a convoluted neural network will allow us to group features into groups of indicators as is now done in the heuristic model. This might not improve accuracy, but it will improve our understanding of which features are important in fake news detection.
- Include a wider range of features - In the literature many more indicators are mentioned as relevant. We need to implement and prune them. Particularly of interest is building a people/concept density using the expertai nlp api.
Built With
- amazon-web-services
- blockchain
- expertai
- flask
- html5
- ipfs
- javascript
- keras
- mongodb
- nltk
- php
- python
- restapi
- tensorflow
- ubuntu



Log in or sign up for Devpost to join the conversation.