-
-
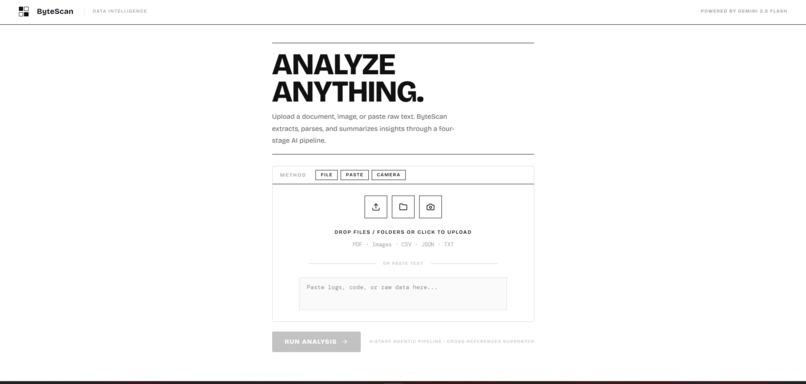
Main UI of ByteScan App
-
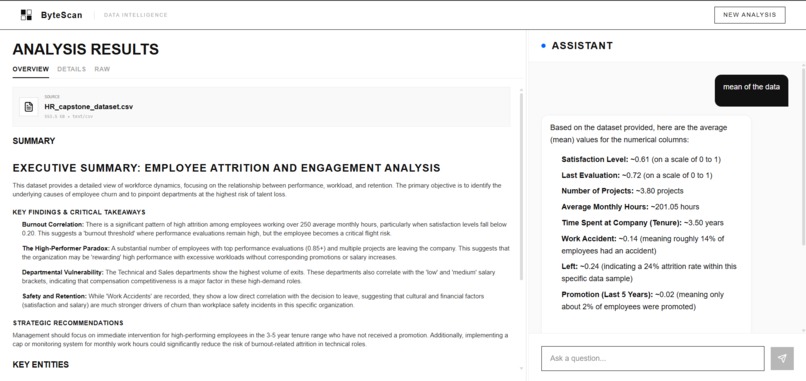
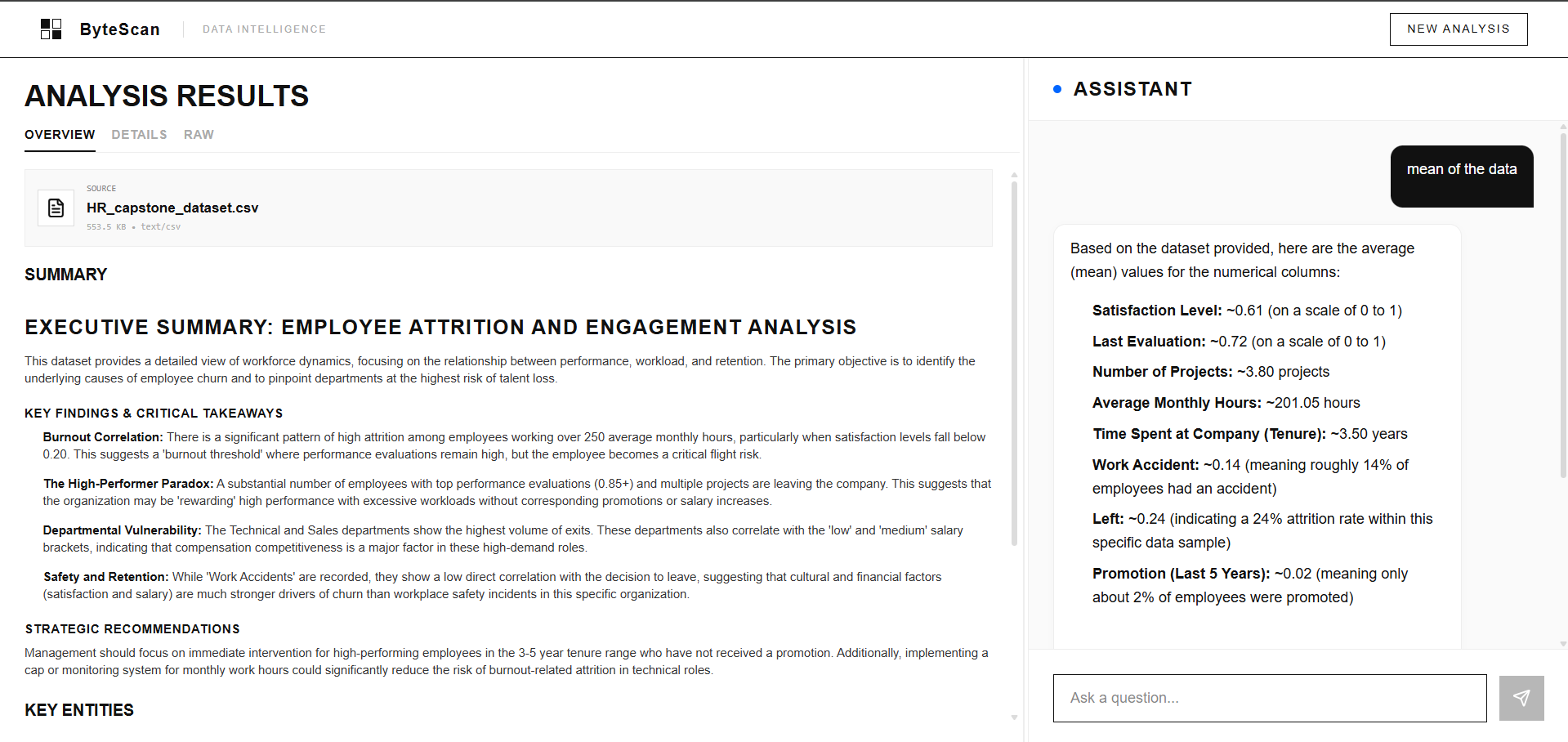
ByteScan Analysis of CSV file
-
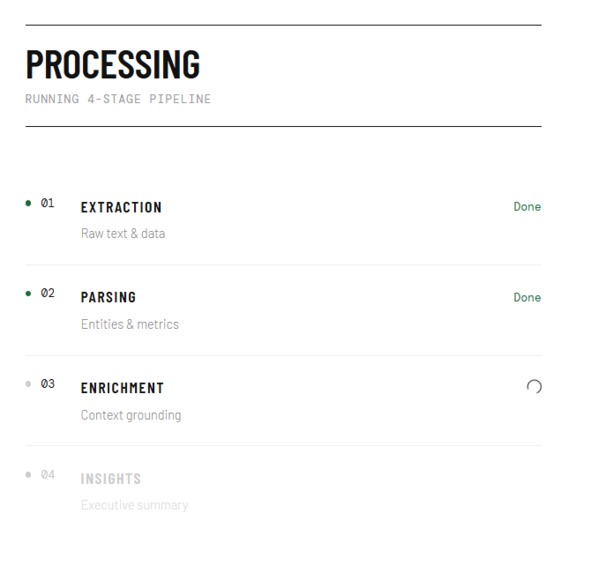
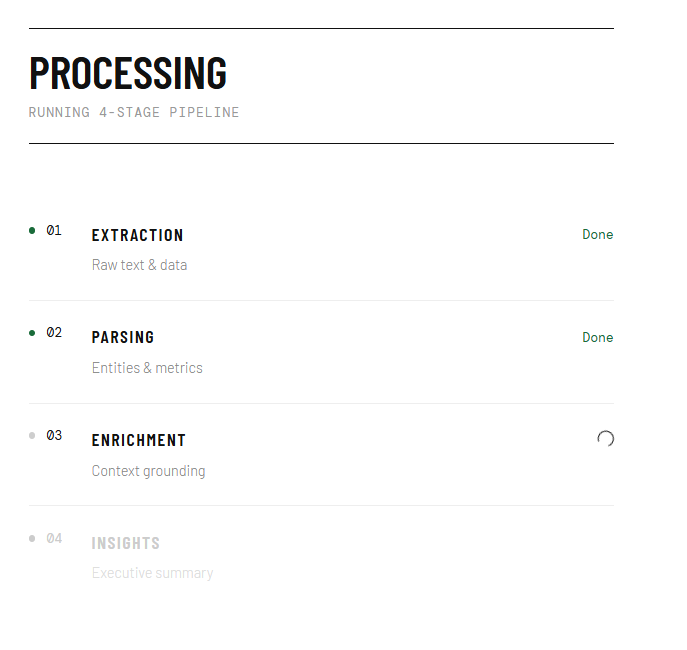
4 layer processing UI
ByteScan: The Multi-File Intelligence Platform
Inspiration
In an era dominated by sprawling raw datasets, reading through disorganized project folders, CSVs, and technical PDFs to extract a simple business heuristic or engineering overlap is notoriously taxing. We wanted to eliminate the manual labor of data correlation.
The inspiration for ByteScan was born out of this bottleneck: What if we could drop an entire directory of mixed files into an engine, and have an AI agent autonomously route, read, cross-reference, and summarize overlapping correlations in seconds? We envisioned an intelligence pipeline that didn't just summarize one document, but engineered an enterprise-grade correlation mapping system across multiple unstructured datasets simultaneously, with absolute uptime.
How we built it
ByteScan was constructed using a React 18 frontend coupled tightly with TypeScript and Vite for massive edge-deployment speed.
We engineered a 4-Stage Agentic Pipeline:
- Extraction Pipeline: Reads the raw metadata and byte structures.
- Parsing Pipeline: Transforms unstructured context into structured JSON entities.
- Enrichment Pipeline: Uses external tool-calling to validate and cross-reference node entities.
- Insights Synthesizer: Formats the correlations into a board-ready executive markdown summary.
The backend intelligence routes natively through the Google GenAI SDK, leveraging gemini-2.5-flash as the core reasoning engine. To ensure absolute data reliability, we built a seamless polyfill adapter wrapper around the OpenAI Node SDK (gpt-4o-mini). If at any point the Gemini node experiences token exhaustion, the pipeline instantly reroutes the multi-file buffer through the OpenAI fallback network—resulting in absolute zero-downtime for the user.
Challenges we ran into
The most severe hurdle we faced was LLM Token Exhaustion Limits and Input Rate Caps. When feeding an entire project folder or extremely bloated CSV files through an extraction zero-shot prompt, the API quota limits trigger HTTP 429 blockades instantly.
To resolve this, we mapped strict payload-balancing algorithms into the pipeline architecture. To stay within dynamic token limits (such as a 200,000 character soft cap), we employed proportional chunking mathematically represented as:
$$ \text{Chunk Size}{file} = \left\lfloor \frac{\text{Maximum Character Limit}}{\max(1, N{\text{files}})} \right\rfloor $$
Where $N_{\text{files}}$ is the total number of documents uploaded. This ensures that no matter how many files a user drops in, the payload remains strictly optimized across the agent's context window.
Furthermore, orchestrating the failover pipeline to mimic the exact stream formatting of a Gemini endpoint utilizing an OpenAI alternative required deep structural overhauls to our prompt injections and isExhausted(error) try-catch boundaries.
What we learned
Building ByteScan fundamentally altered our perception of building scalable LLM pipelines. We learned:
- Resilience Architecture: AI applications cannot rely on a single endpoint; integrating a "secret" fallback logic block is critical to enterprise software success.
- Agentic Workflows: Splitting an LLM task into 4 distinct modular "agents" (Extract -> Parse -> Enrich -> Synthesize) yields infinitely more accurate data extraction than attempting a massive one-shot prompt.
- Mobile Edge Cases: Handling iOS Safari's aggressive auto-zooming logic by enforcing strict bounds ($\geq$
16px) and parsing extreme horizontal JSON flexing parameters fundamentally polished our frontend architecture.
What's next for ByteScan
ByteScan is ready to scale. Our immediate architectural goals include migrating the raw processing boundaries to leverage full semantic Vector Search (RAG). We plan on implementing local SQLite architectures built on WebAssembly to run vector embeddings directly in the client's browser, entirely eliminating external endpoint bottlenecks for massive files, and opening up native Cloud SQL persistence!

Log in or sign up for Devpost to join the conversation.