-
-

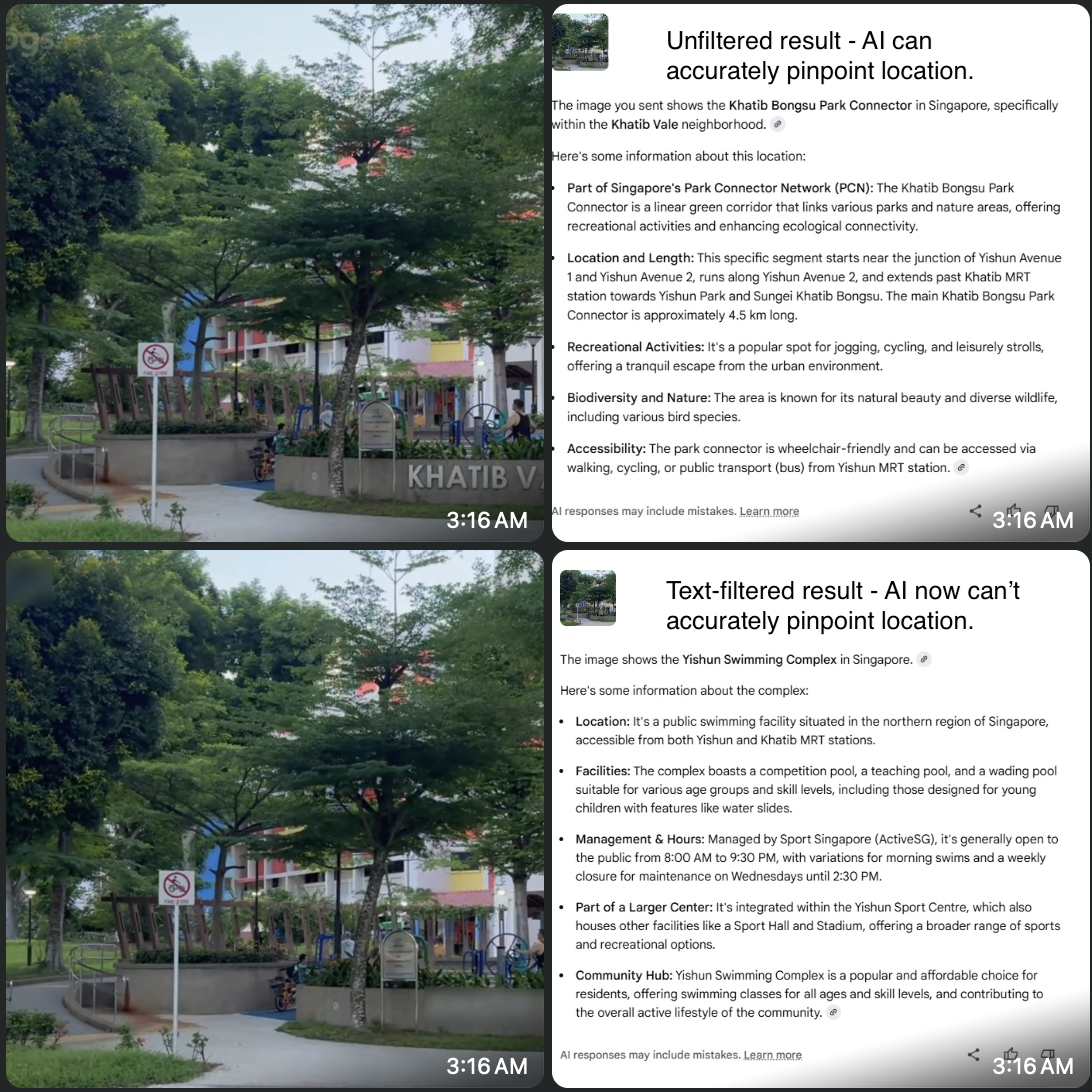
Text filter effect
Our Inspiration
In March 2025, the tragic death of Airi Sato in Tokyo highlighted the dangers of location doxxing during livestreams. While broadcasting near a train station, her attacker tracked her down by recognising her surroundings. Unfortunately, similar incidents happen globally: streamers and everyday users can be exposed when street signs, storefronts, and other location indicators, combined with reverse image search engines, give away their exact location. The risk goes beyond the streamer alone: bystanders in the background can also be exposed, even if they didn’t consent to being filmed. Faces caught in livestreams or videos can be identified using facial recognition, linked to social media profiles, or used to infer their locations.
Our Idea
Our project is a real-time privacy shield designed to prevent these risks. While targeted at livestreamers streaming at public locations, it can also accept video inputs and lessen the workload of content creators who want to maintain their privacy and reduce doxxing. It automatically detects and blurs text in the background such as street signs, station names, or storefronts while also blurring the faces of bystanders to protect their privacy.
Why This Matters
By combining text blurring and facial blurring, our system provides a comprehensive privacy shield. Our mission is make digital sharing safer for everyone in the frame, not just the person holding the camera.
What it does
Byte Meets Vibe keeps your world private while you share it. Our AI not only spots every face around you and automatically blurs anyone who isn’t you, but also blurs any location indicators that might expose where you are. Snap photos, stream live or take calls without worrying about accidentally exposing yourself or bystanders. Privacy - in real time.
How we built it
Byte Meets Vibe has 2 components: the Frontend (React Native/Expo) and the Backend (Python Flask). Frontend
- Is a cross-platform mobile application using React Native and Expo.
- Implemented camera functionality for real time video capture and processing
- Created a calibration system with 14 different facial poses for accurate face recognition
- Integrated with backend APIs for video processing and face calibration
Backend
- Developed a Flask REST API Server for video processing and facial recognition
- Integrated YOLOv8m-face model for high-accuracy face detection
- Fine-tuned an ArcFace model to generate consistent, normalised 512-dimensional embeddings. The mean vector embedding is then stored in a database.
- Facial Recognition is performed using the ArcFace model by calculating the cosine similarity between a detected face's embedding and the stored embeddings of known individuals.
- Created a multi-criteria scoring system for automated quality assurance. It automatically validates samples based on Laplacian variance (sharpness/blur), brightness, contrast, and face size to filter out poor-quality images.
- Used Non-Maximum Suppression (NMS) to eliminate duplicate bounding boxes for the same face.
- Adopted advanced GPU acceleration with TensorRT for maximum performance by transitioning our pipeline to TensorRT 10.13, using FP16 precision to accelerate inference.
- Shifted to a single-threaded processing model to avoid CUDA context conflicts, while still using thread-safe queues for ingesting frames from the camera.
- Stabilised the filtered live stream with a 5-second buffer delay, which absorbs processing time variations and presents the user with a consistently smooth video stream rather than a choppy, lagging one.
- Implemented PaddleOCR with GPU support to identify and blur text-based Personal Identifiable Information (PII) from the video feed.
- Hybrid "Detect-and-Track" Architecture: Every 12 frames, the PaddleOCR model performs a high-quality scan of the scene to find all text. For the frames in between, a set of Channel and Spatial Reliability Tracking (CSRT) trackers take over. These trackers smoothly follow the objects identified, and ensure the blur locks on to moving text.
Challenges we ran into
Frontend
- When we are building the frontend, we were deciding between lynx and react native as our main framework, weighing factors like development speed, cross-platform support, and user experience.
Backend
- While finding ways to reduce lag, we have tested many techniques such as frame skipping, reducing the frequency of object recognition, multi-threading, including a buffer delay, using a whole different model. Nevertheless, we were almost always frequently led to a whole other nest of problems such as bounding box delays, jittering, frame rate volatility and even the infamous dependency hell :(
Accomplishments that we're proud of
- We have made a working AI that helps to blur other people faces with the exception of the user, and is able to track location indicators in real time accurately.
- We have made a working Frontend that helps acts as a live streaming service.
What we learned
- We have learnt various machine learning pipelines.
- We have learnt how to write frontend code in react native.
What's next for Byte Meets Vibe
- We hope to expand this product into tiktok live streaming service, so it will aid content creators in being safe.
- Include the capability to unblur certain objects by tapping on them.
- For the text filter, include Named Entity Recognition (NER) such as email addresses (@gmail.com) and phone numbers (+65) for PII detection, so that our model is privacy-aware and intelligently redacts sensitive information.
Built With
- arcface
- cupy
- flask
- paddleocr
- python
- react-native
- tensorrt
- yolo





Log in or sign up for Devpost to join the conversation.