-
-

BYEas
-
BYEas
-
BYEas
-
BYEas
-
BYEas

Background
Bias in data and modeling is prevalent. Bias in machine learning can be applied when collecting the data to build the models, it can also come with testing the output of the models to verify their validity.
Bias can come from many places, but commonly it results from a distorted population. Data is not representative of the individuals and groups we are looking to build models for. Especially when it comes to financial service industries it could be very time consuming, complicated and expensive to try and naturally acquire more data.
What BYEas does
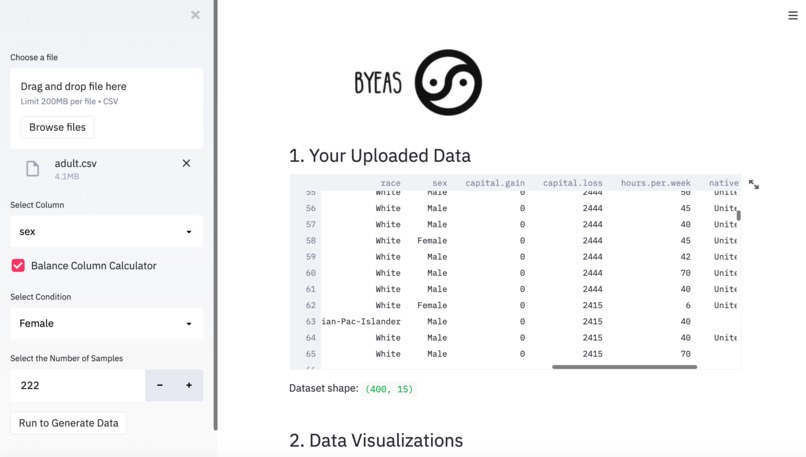
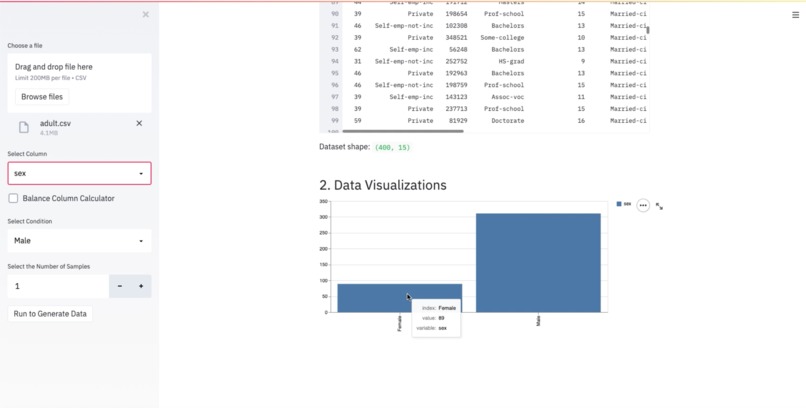
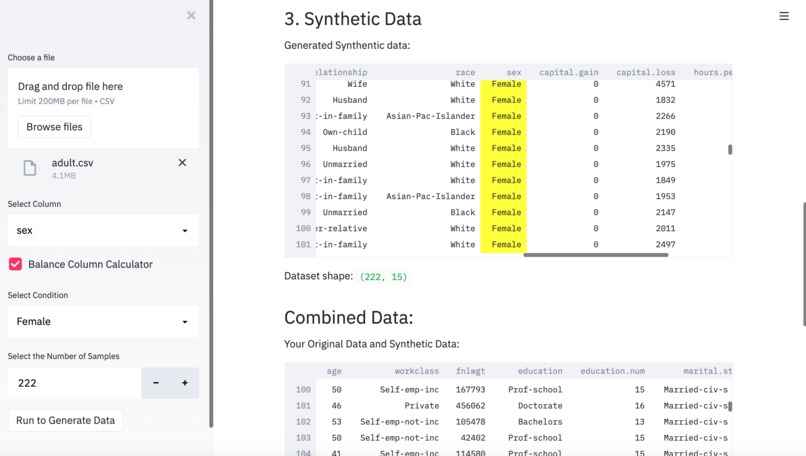
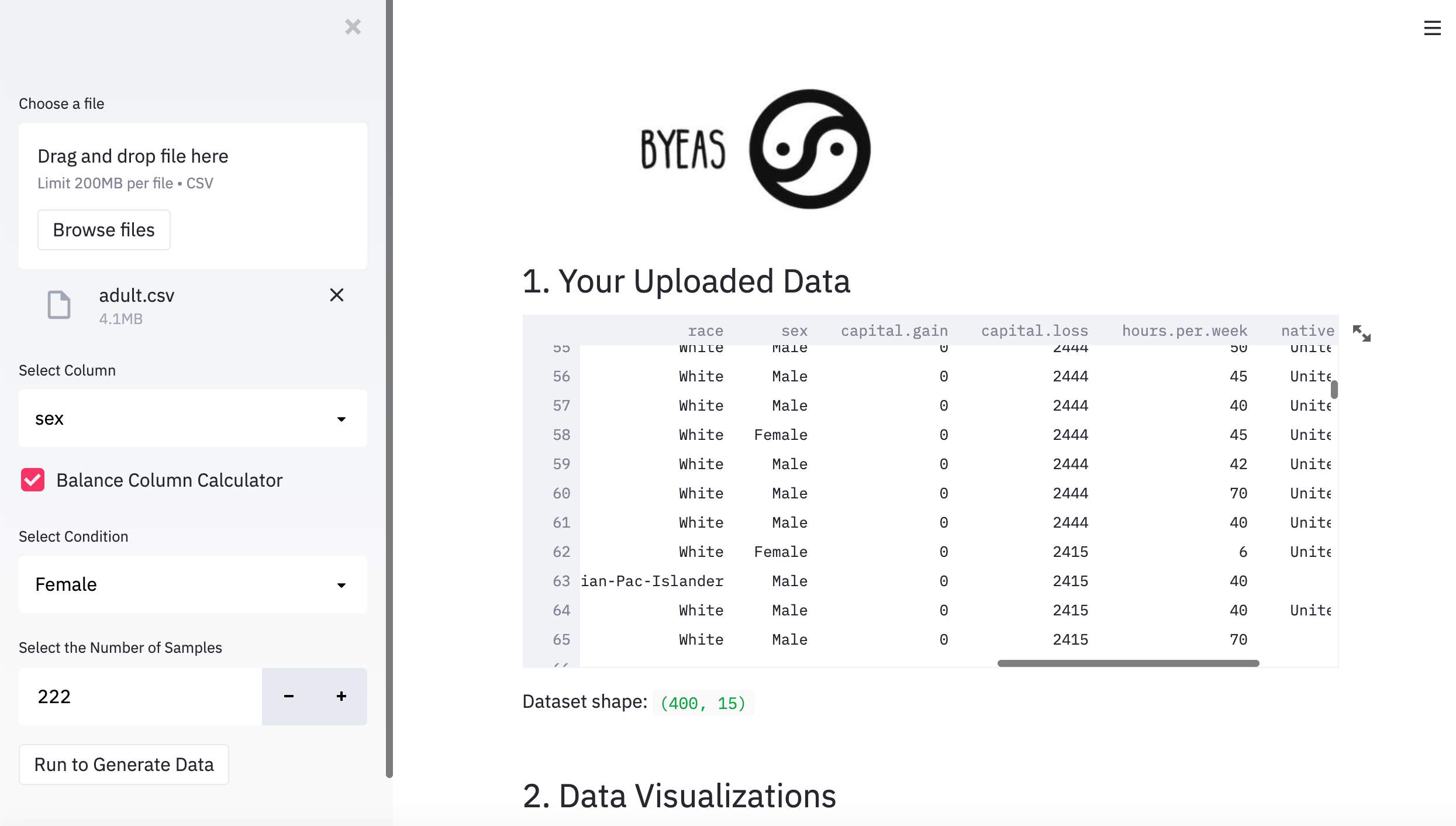
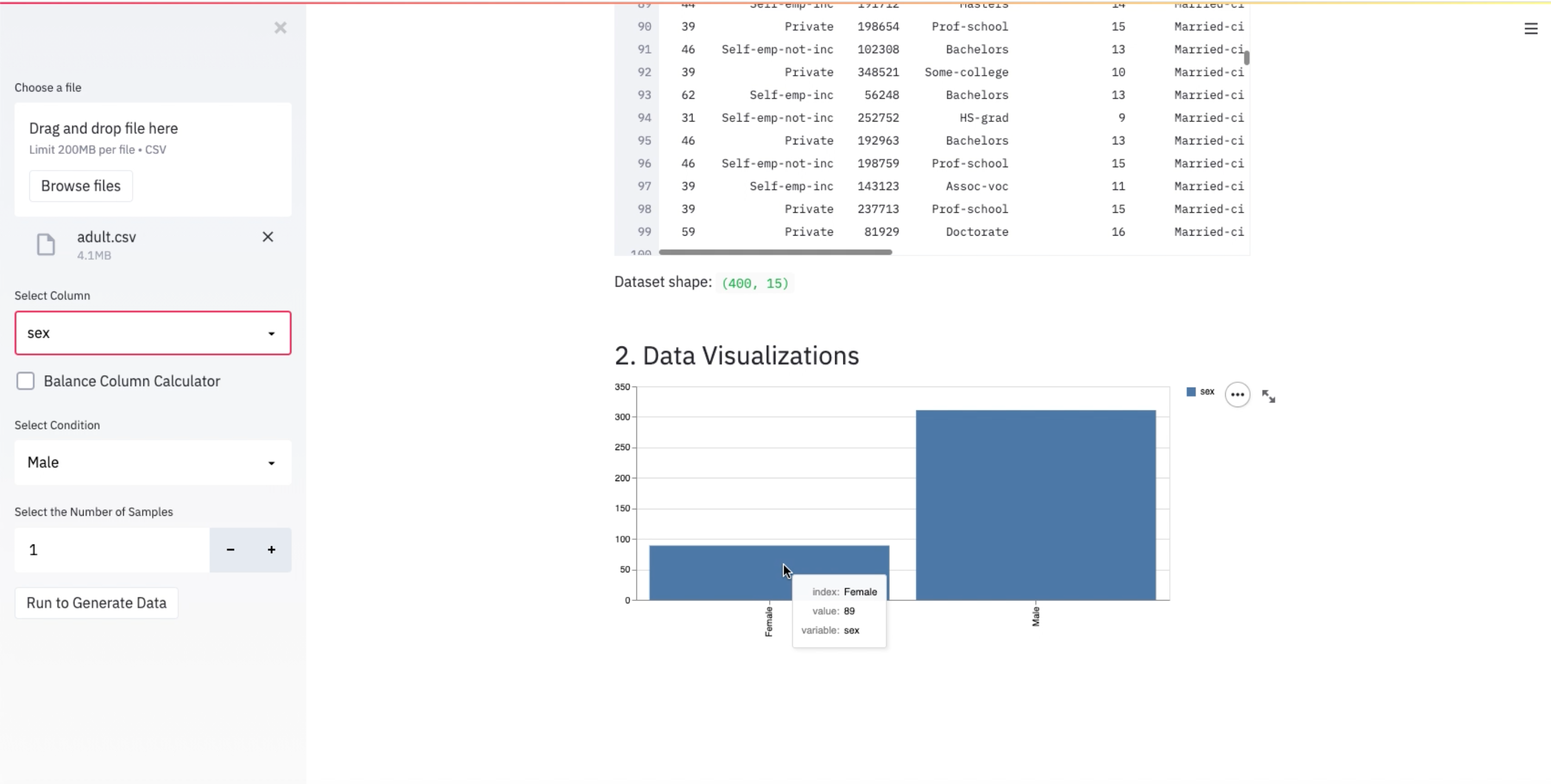
BYEas leverages deep learning algorithm to help you generate more synthetic data based on the column, condition and the amount you choose. BYEas also helps you understand the dataset you uploaded and provide data insight to you.
How we built it
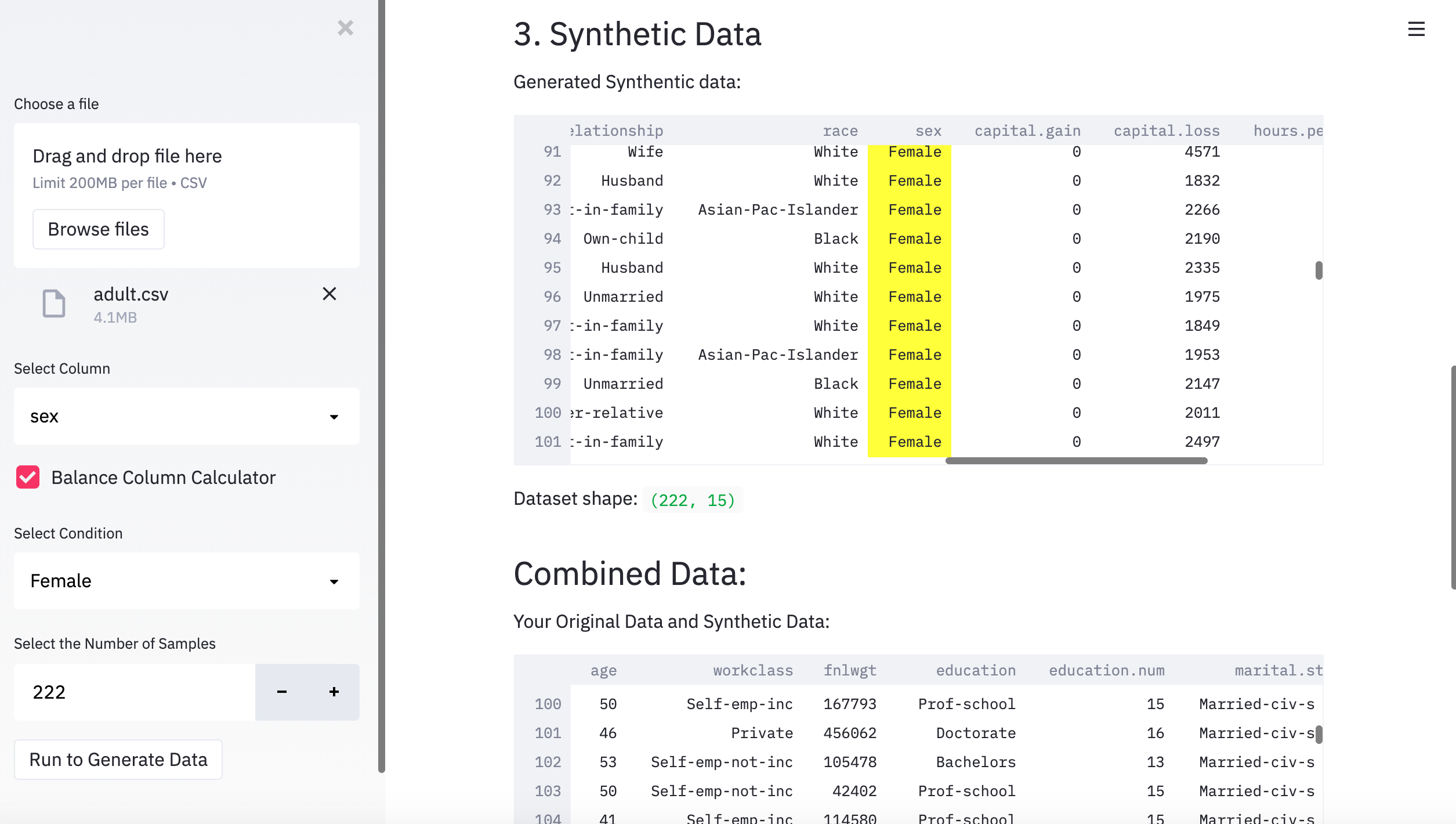
Synthetic data is our solution.
Synthetic data, by its name, is not collected by any real life survey or experiment. It learns from the real dataset and resembles the real data as some fake data programmatically.
Synthetic data can be used for:
-- Protecting data privacy
-- Solving data scarcity
-- Improving model performance
Accomplishments that we're proud of
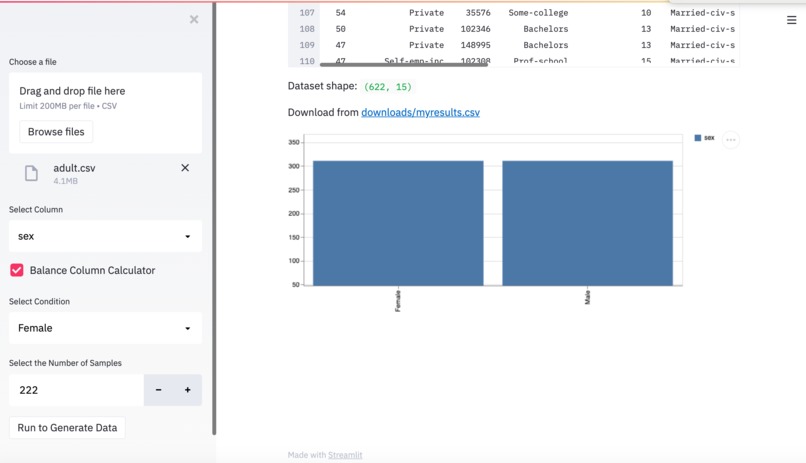
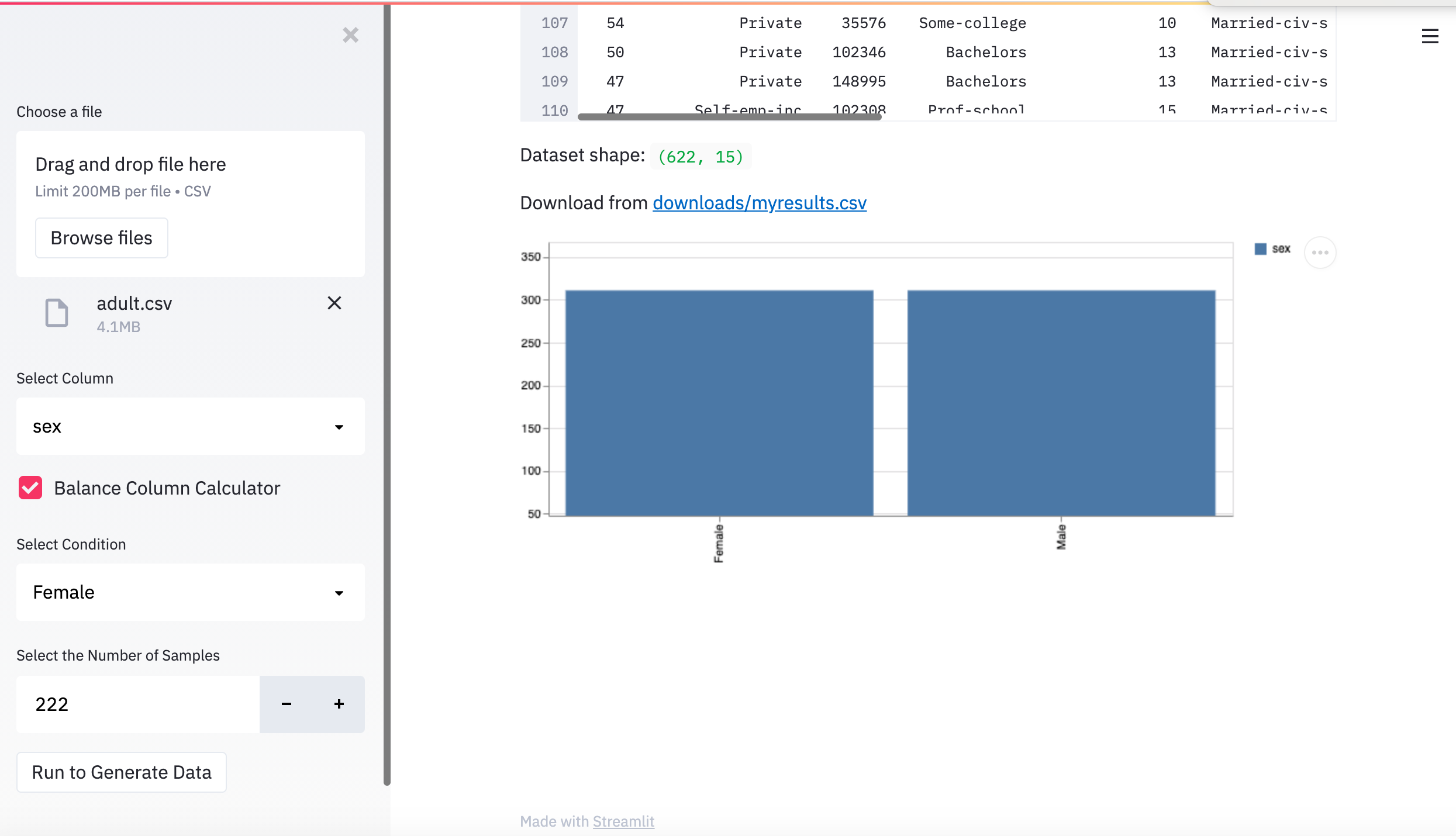
We helped users say goodbye to imbalanced data. We use synthetic data by making data more representative of the population you wish to model. Not only can we use BYEas in the financial service industry to help balance data, but we can also apply BYEas in many other industries as well !
Synthetic data will allow data scientists to continue ongoing work without involving real/sensitive data.
What's next for BYEas
We are planning add an evaluator section in BYEas to show the user how synthetic data's distribution compare to real data we have. This will help the user have more confident in the data BYEas generated for them.
Behind the Scenes
- Python
- Streamlit
- Deep-learning
- CTGAN
- Synthetic Data





Log in or sign up for Devpost to join the conversation.