-
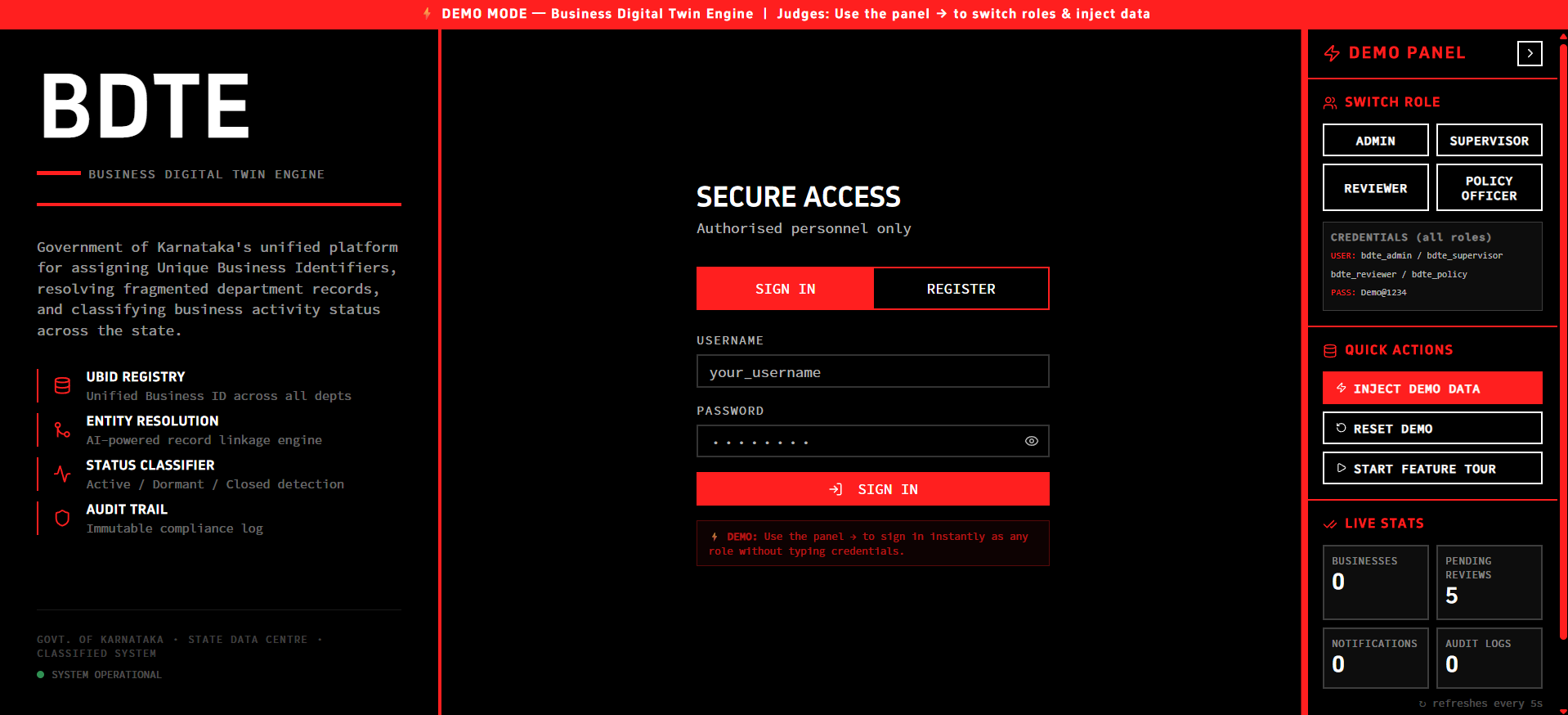
Login and Signup
-
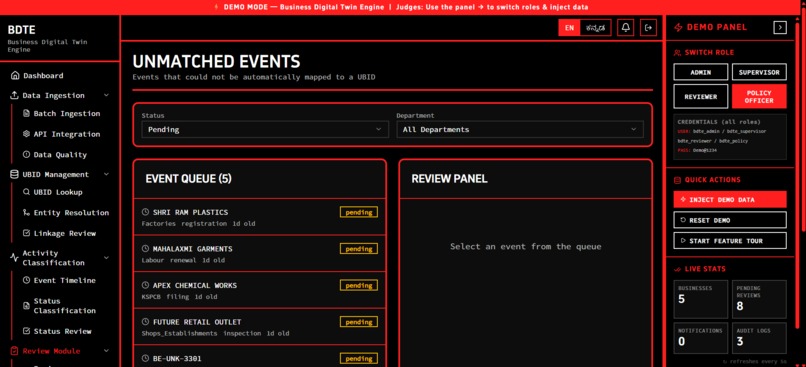
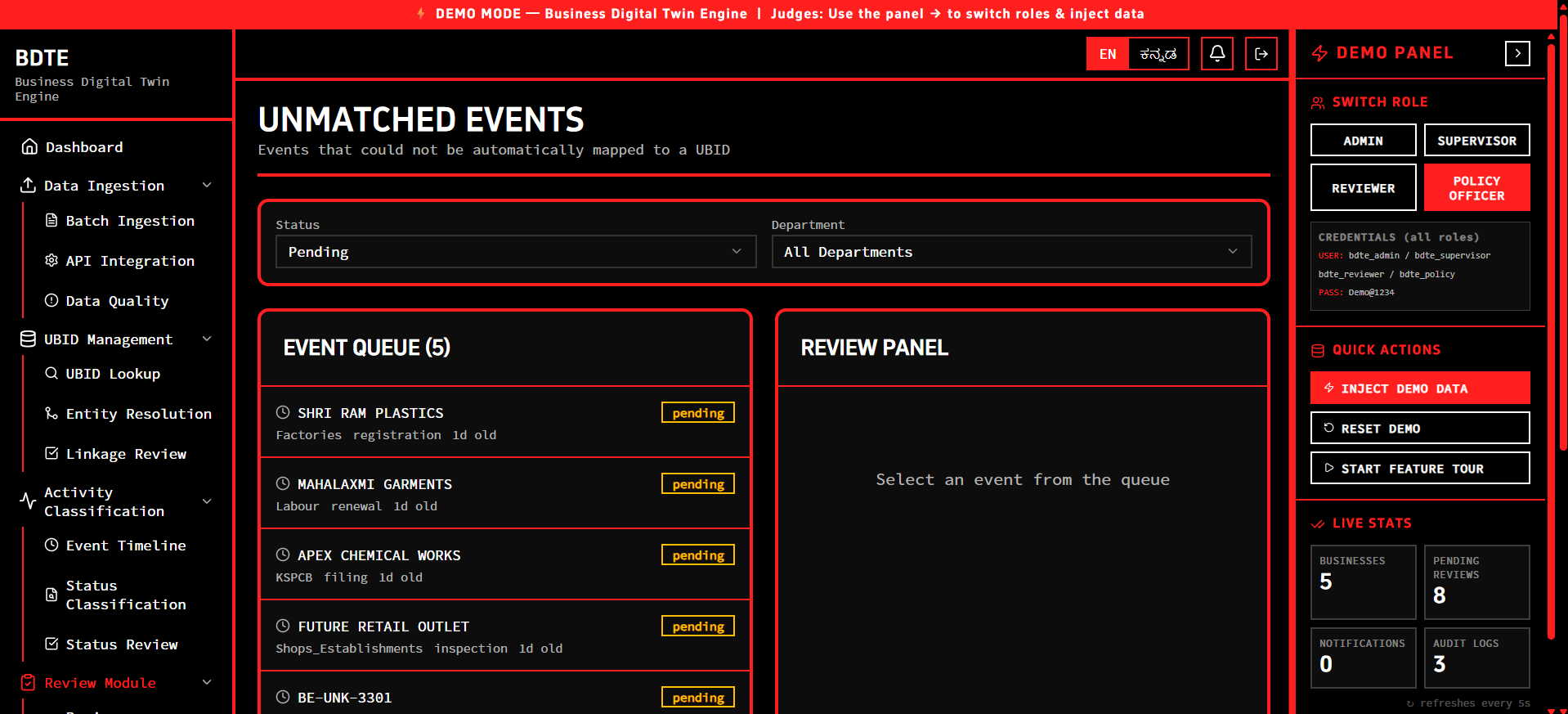
Unmatched Events
-
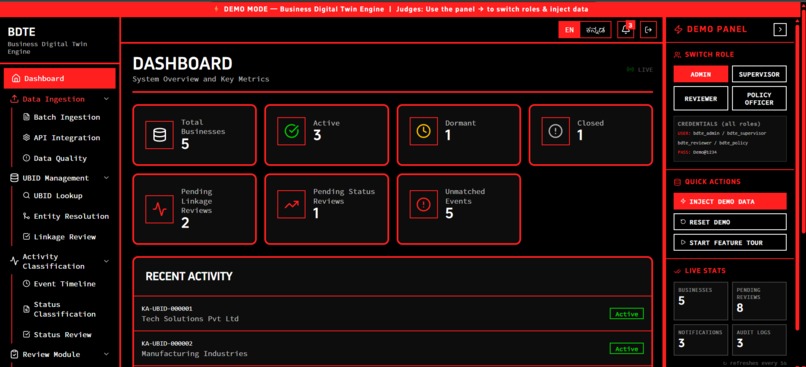
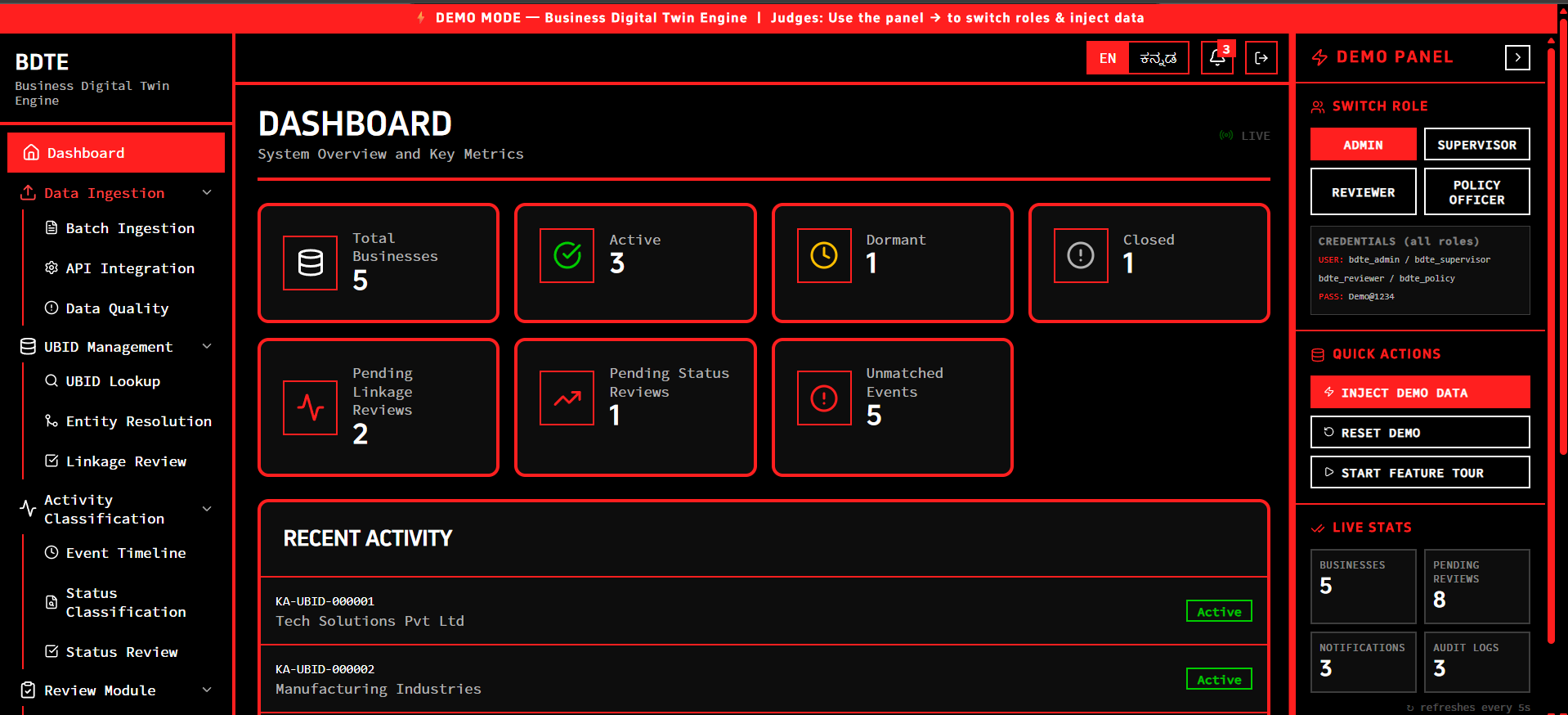
Dashboard
-
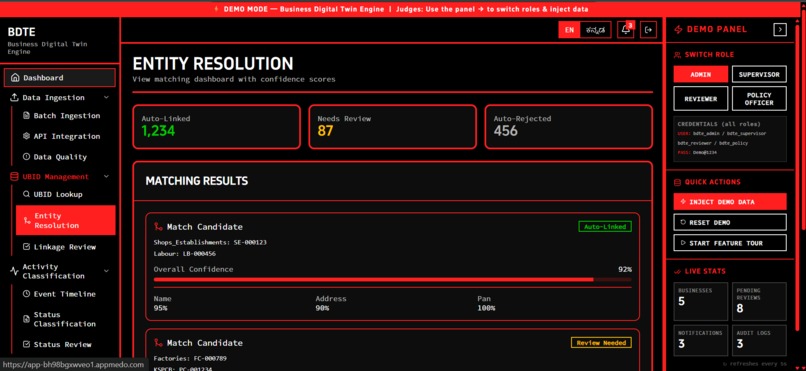
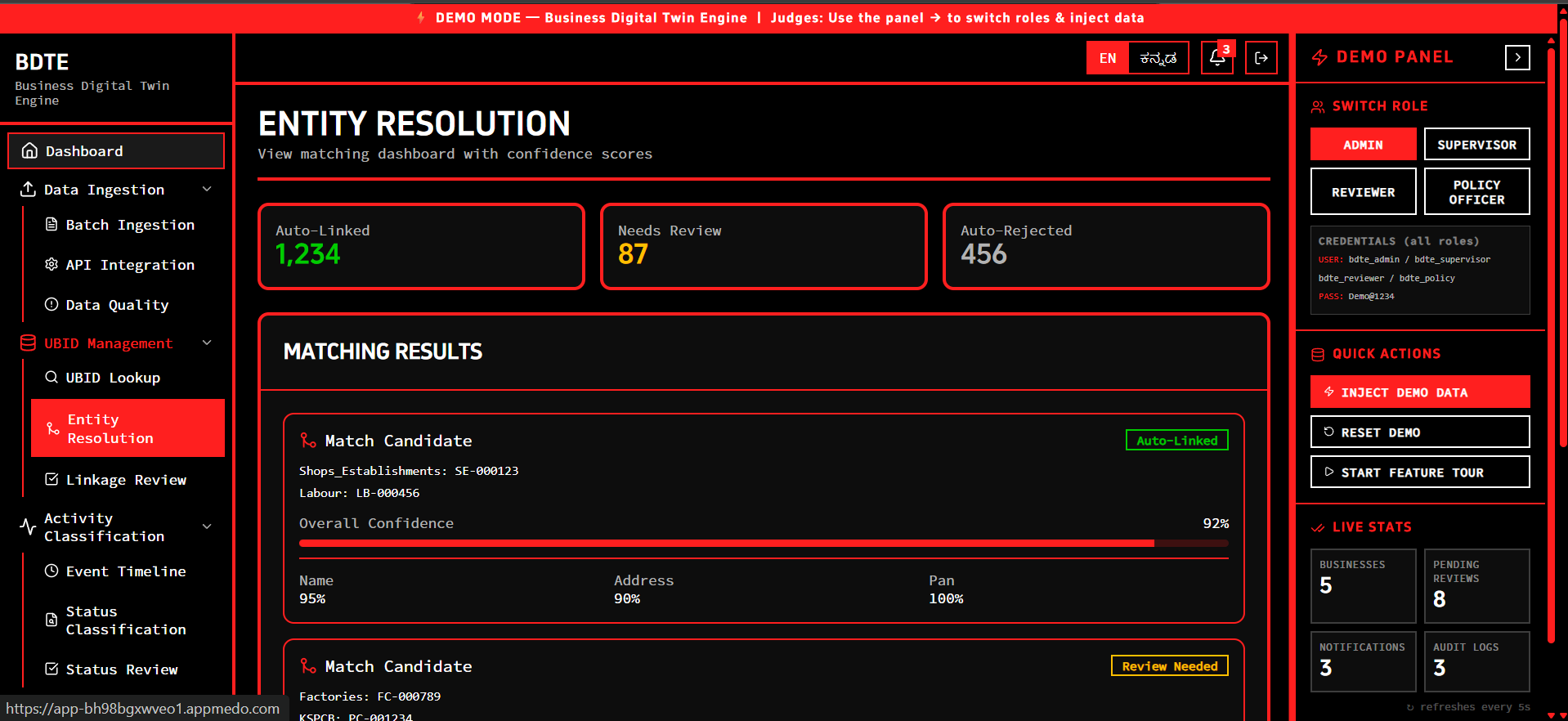
Entity Resolution
-
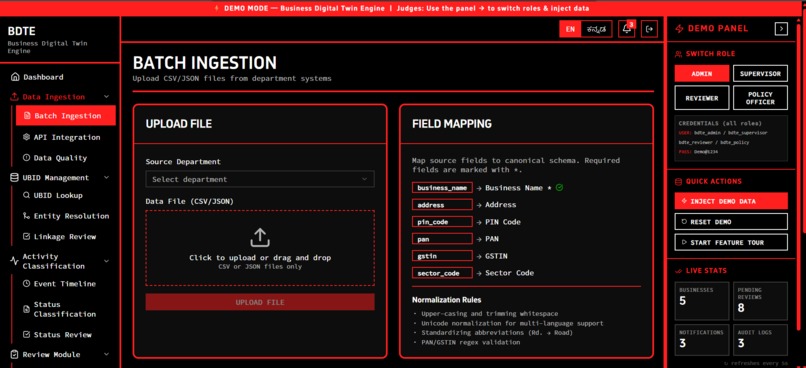
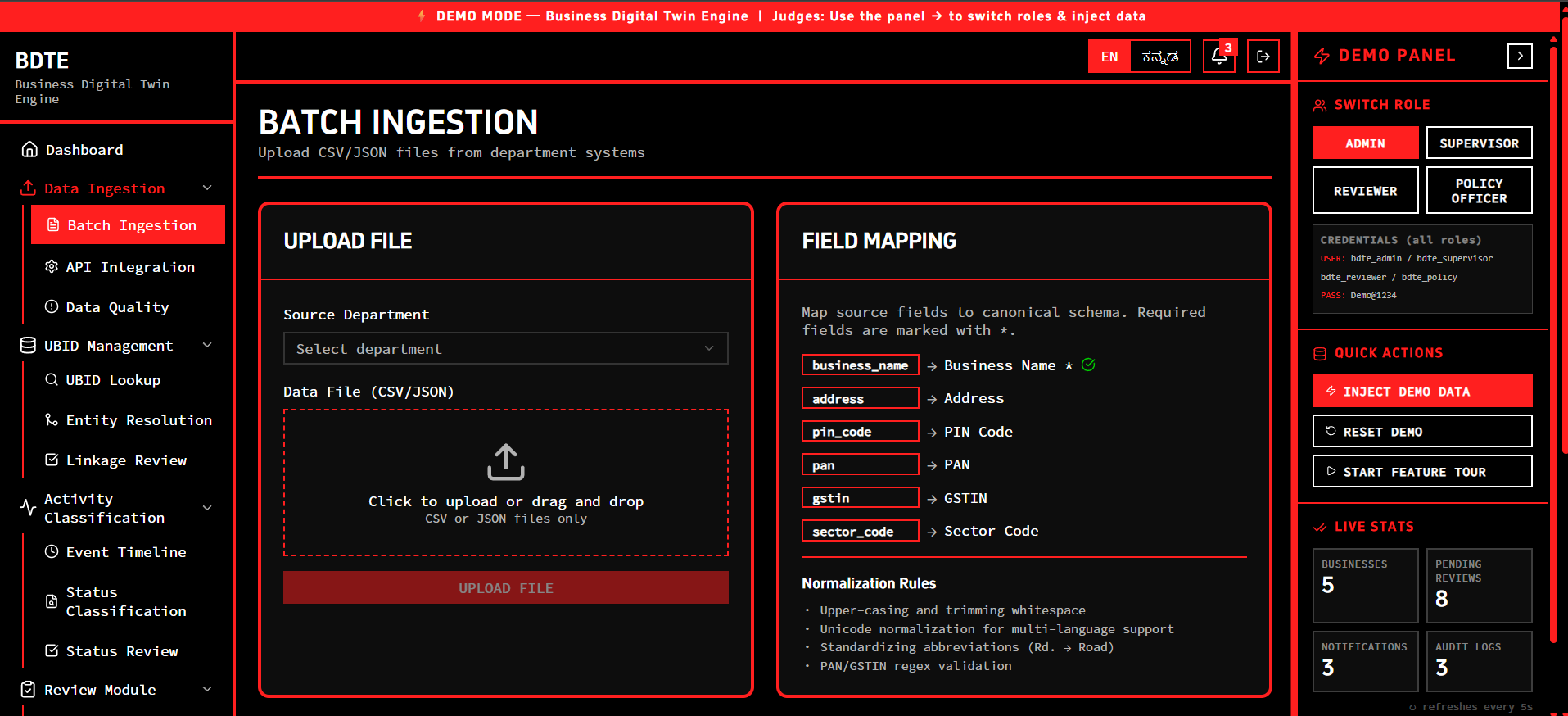
Batch Ingestion
-
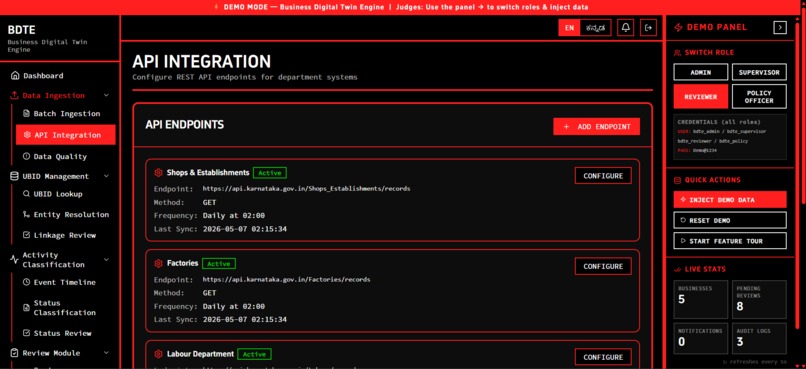
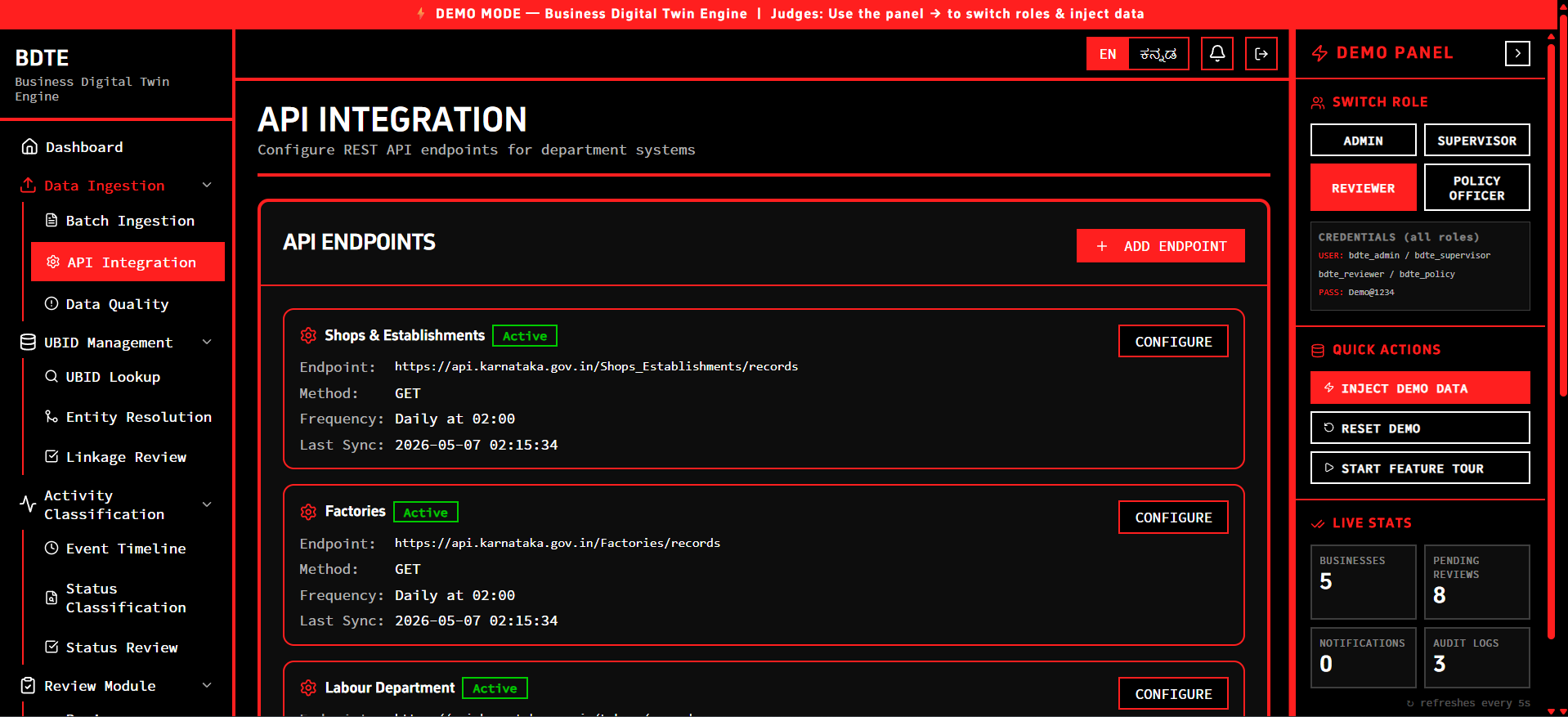
API Integration
Inspiration
Karnataka's business regulatory landscape relies on 40+ isolated state department systems (Shops & Establishments, Factories, Labour, KSPCB, etc.). Each was built in a silo with its own schema and validation rules. The government was facing a massive blind spot: they couldn't answer simple questions like "How many active factories actually exist in Bengaluru?" because the same business existed as five different unlinked records.
We were inspired by the challenge of creating a "Single Source of Truth" without doing a highly disruptive, multi-million dollar "big bang" database migration. We wanted to build a practical, privacy-first engine that could sit alongside existing infrastructure and bring order to the chaos using explainable AI.
What it does
The Business Digital Twin Engine (BDTE) is a robust backend platform and dashboard that creates a canonical digital twin for every business in the state.
- Assigns a UBID: It ingests fragmented master data from various departments and uses exact (PAN/GSTIN) and fuzzy matching to cluster them into a single Unique Business Identifier (KA-UBID).
- Infers Activity Status: It consumes one-way event streams (license renewals, inspections, utility usage) to dynamically classify a business as Active, Dormant, or Closed.
- Provides Evidence: It generates an "Evidence Timeline," proving exactly why a business has a certain status.
- Human-in-the-Loop (HITL): It never silently guesses on ambiguous data. Low-confidence matches and conflicting activity signals are routed to a specialized Reviewer Dashboard for human oversight.
- Enables Complex Queries: Policymakers can finally search: "Show me active factories in PIN 560058 with no labor inspections in the last 18 months."
How we built it
We architected BDTE using a modern, monorepo approach split between a fast API backend and an enterprise-grade frontend:
- Backend Core: We used Python with FastAPI to handle data ingestion and routing. To solve the entity resolution problem, we used Pandas for data normalization and TheFuzz for calculating Levenshtein distance on business names and addresses.
- Database: We utilized SQLite via SQLAlchemy ORM for the prototype, designing a relational schema that mimics a production PostgreSQL environment.
- Frontend Dashboard: We built the UI with Next.js (App Router) and TypeScript, styled with Tailwind CSS. We focused heavily on creating intuitive side-by-side comparison tables for the Human-in-the-Loop review queue.
Challenges we ran into
- The Messiness of Indian Addresses: Free-text addresses without standardization meant basic string matching often failed. We had to carefully weight PIN codes and specific tokens to prevent false positives.
- Balancing Precision vs. Recall: A wrong merge is much more costly than a missed merge. We spent significant time tuning our confidence thresholds (e.g., Auto-Merge > 0.85, Review Queue 0.60–0.85) to ensure absolute data integrity.
- DPDP Compliance (Privacy): We couldn't just throw the data at a cloud-based LLM like GPT-4 to solve the matching problem, as sending raw citizen/business PII outside the government network violates privacy laws. We had to build entirely local, explainable matching logic.
Accomplishments that we're proud of
- 100% Explainable AI: There are no "black box" decisions in our app. Every merge and every status change comes with a generated audit trail and a transparent confidence score.
- The Reviewer UI: We built a highly polished, side-by-side "Record A vs Record B" interface that highlights textual differences, making life incredibly easy for government data stewards.
- Zero Disruption to Source Systems: We successfully proved that we can achieve a unified business registry via one-way data feeds without requiring a single change to the legacy department software.
What we learned
- Building for the government requires a strict adherence to constraints. Sometimes, "boring" but verifiable local algorithms (like fuzzy string matching) are infinitely more valuable than cutting-edge Generative AI that hallucinates or leaks data.
- Creating a seamless interface between human reviewers and automated AI models is just as important as the backend algorithm itself. AI should empower the data steward, not replace them.
What's next for Business Digital Twin Engine
- State Data Centre (SDC) Sandbox: Transitioning from SQLite to PostgreSQL and deploying the engine into the Karnataka SDC sandbox to process millions of rows of scrambled data.
- Advanced Machine Learning: Using the decisions made by humans in the Reviewer Queue as labeled training data to train a custom, local NLP model to improve match recall for edge cases.
- Utility Data Integration: Connecting real-time power consumption data from BESCOM to detect business dormancy within weeks rather than months.
python fastapi next.js react typescript tailwind-css sqlite sqlalchemy pandas thefuzz
Built With
- fastapi
- next.js
- pandas
- python
- react
- sqlalchemy
- sqlite
- tailwind-css
- thefuzz
- typescript

Log in or sign up for Devpost to join the conversation.