Inspiration
Nearly half of workers globally are currently experiencing burnout, according to BCG research across 11,000 employees. But we noticed something frustrating about existing burnout tools:
They only ask, they don't measure. Self-reported data is unreliable people often don't recognise their own fatigue until it's too late. They diagnose but never validate. You get a score and recommendations, but you never know if those recommendations actually work.
We asked ourselves: What if we could objectively measure fatigue, cross-validate it with user input, and actually prove our predictions are accurate over time?
That's when our Burnout Risk Analyser came to be.
What it does
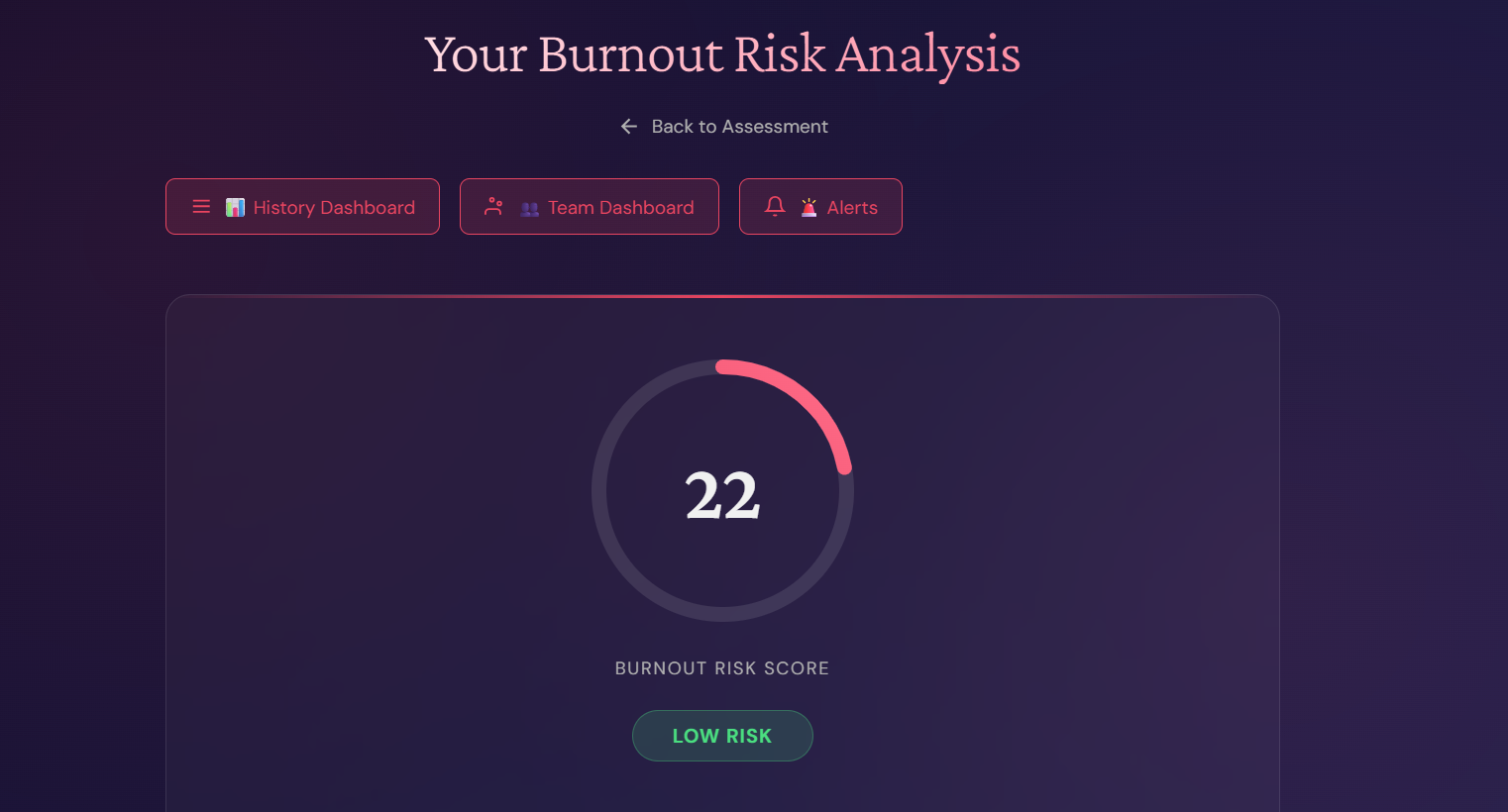
Burnout Risk Analyser is a multi-modal burnout prediction system that combines three data streams to create reliable, validated predictions: Multi-Modal Risk Assessment
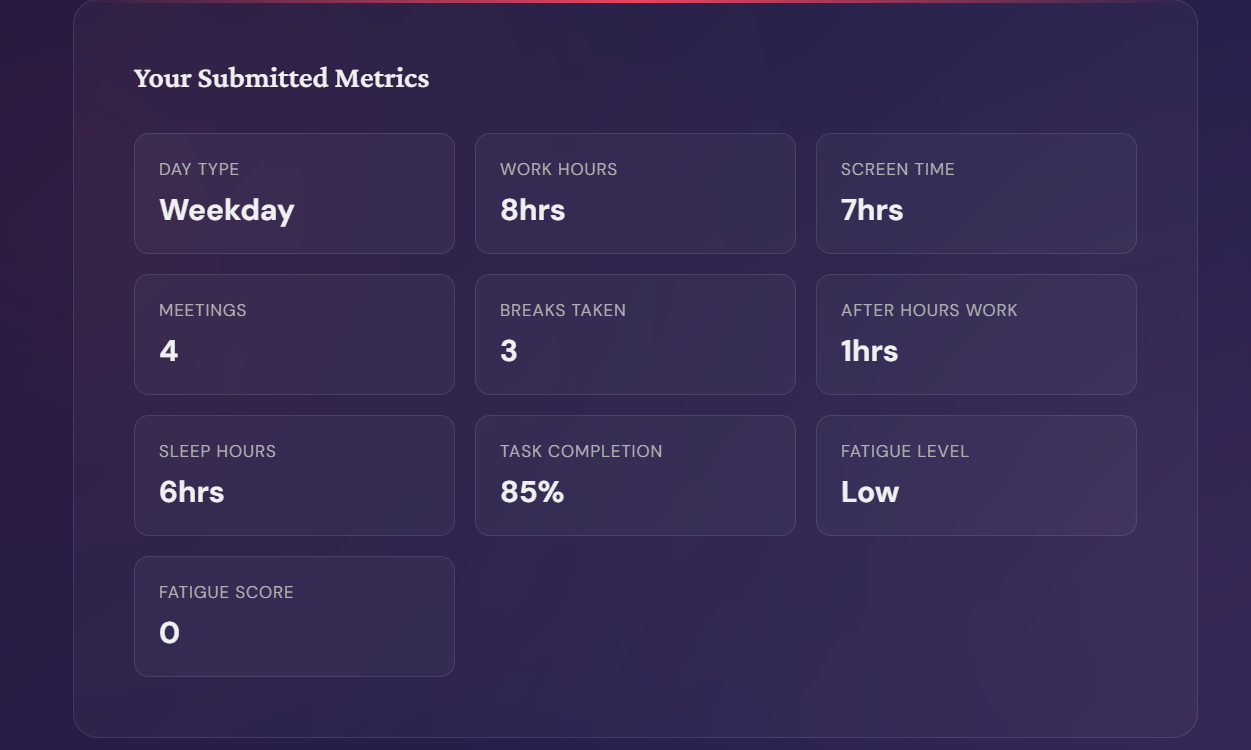
Behavioural Metrics: Work hours, screen time, meetings, breaks, sleep, task completion Computer Vision Fatigue Scan: Analyses eye aspect ratio, under-eye darkness, head tilt, gaze stability, and more Self-Report Validation: Cross-validates AI analysis with how you actually feel
Objective Measurement: Our vision pipeline captures 8 video frames and extracts facial fatigue indicators:
Eye openness (drowsiness detection) Under-eye darkness (eye bags) Head tilt (posture fatigue) Gaze stability (focus/attention) Blink patterns
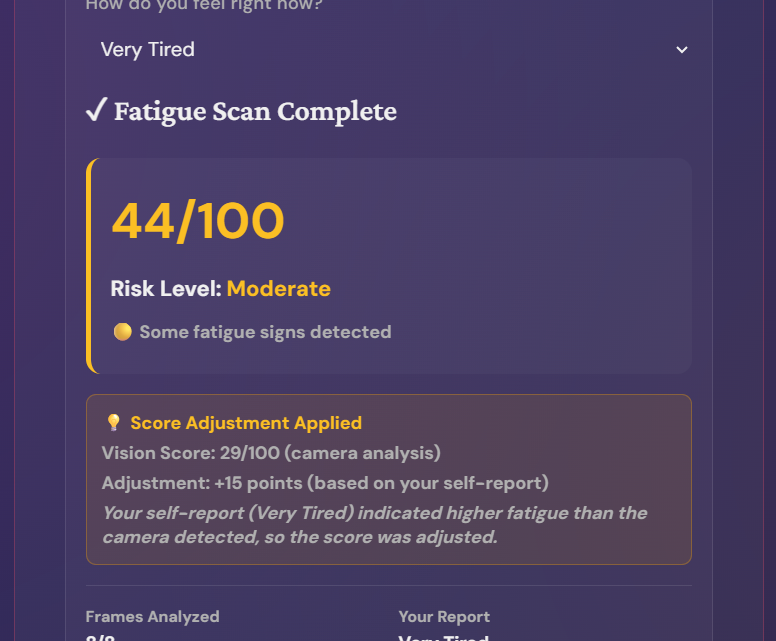
The camera score is then cross-validated with your self-report. If you say "Very Tired" but the camera shows 37, we boost to 52 because we trust humans over algorithms when they disagree.
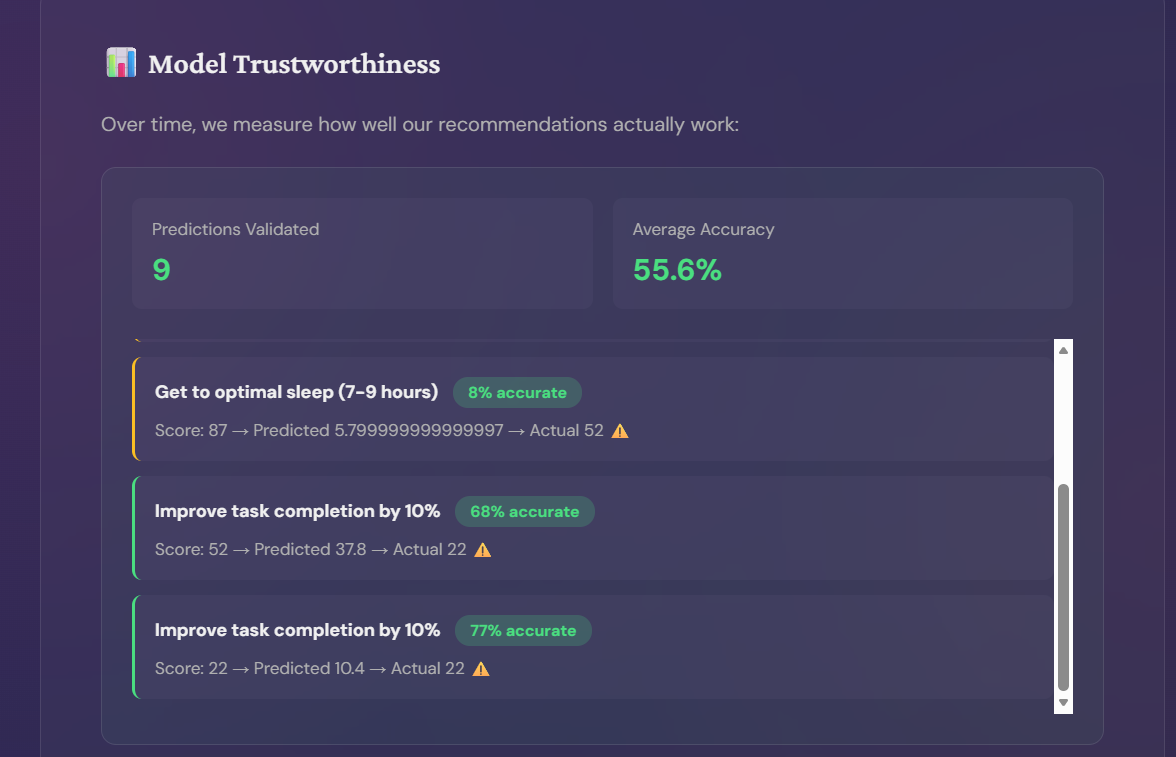
Closing the Feedback Loop: This is our key differentiator. We don't just predict we validate:
You get a burnout score and ranked recommendations You commit to an intervention ("I'll reduce meetings by 3") After a set period, you reassess The system compares predicted improvement vs. actual improvement Over time, we track model accuracy and build trust
Team & Organisational Insights:
Team dashboards showing aggregate burnout patterns Systemic risk detection (when multiple people share the same stressors) Automated alerts for high-risk individuals or teams
How we built it
Architecture: Architecture Frontend (HTML/JS)
Form inputs + Camera UI MediaPipe FaceMesh (client-side CV) Real-time fatigue scoring
⬇️ Backend (Flask/Python)
XGBoost ML model inference Intervention tracking & validation History & team analytics
⬇️ Persistent Storage
Assessment history (JSON) Intervention commitments Validation results & accuracy stats
Tech Stack:
Frontend: HTML5, CSS3, Vanilla JavaScript Computer Vision: MediaPipe FaceMesh, (runs entirely client-side for privacy) Backend: Flask (Python) ML Model: XGBoost trained on 1,800 real burnout assessments Data: JSON-based persistence
Vision Pipeline Deep Dive: Our fatigue detection processes 8 frames and extracts:
Eye Aspect Ratio (EAR) - measures eye openness Under-eye Darkness - compares brightness of cheek vs. under-eye region Head Tilt - detects fatigue-related posture changes Mouth Aspect Ratio (MAR) - jaw tension indicator Gaze Stability - eye movement consistency Brow Position - raised/furrowed detection
We use trimmed mean aggregation across frames to remove outliers, then weight each feature based on reliability research.
Challenges we ran into
Blink Detection is Unreliable Our initial approach heavily weighted blink frequency. Turns out, some tired people blink more, some blink less there's no consistent pattern. We pivoted to eye bag darkness detection, which proved far more reliable.
Balancing the ML Model Our first XGBoost model let task completion rate dominate predictions (59-point swings!). We retrained with feature scaling and regularization to achieve balanced importance ( 20% each for top features).
Self-Report vs. Camera Disagreement What happens when the camera says you're fine but you feel exhausted? We chose to trust the human and implemented a boost system that adjusts scores when self-reports indicate more fatigue than detected.
Client-Side CV Performance Running MediaPipe in the browser is computationally expensive. We optimized by capturing only 8 frames with 500ms intervals and processing asynchronously.
Accomplishments that we're proud of
Multi-modal data fusion - Behavioural metrics, computer vision, and self-report combined into a single prediction pipeline.
Privacy-first CV - All facial analysis runs client-side. Video never leaves your browser. Closed feedback loop - Predictions are validated against real outcomes, with accuracy tracked over time. Principled human-AI reconciliation - When camera and self-report disagree, the system has a clear protocol to resolve it. Production-ready architecture - Team dashboards, history tracking, intervention validation, and accuracy statistics all built in.
What we learned
Self-reported data is necessary but insufficient. Objective measurement adds real value, but users should always have the final say. Predictions without validation are just guesses. The feedback loop transforms our tool from "wellness app" to "decision support system." Feature importance matters. An unbalanced ML model produces nonsensical recommendations. Regularization and scaling are essential. Demo != Production. Designing for both (configurable time intervals) requires upfront architectural thinking.
What's next for Burnout Risk Analyser
Calendar Integration - Automatically pull meeting counts from Google Calendar / Outlook Wearable Integration - Import sleep data from Apple Watch / Fitbit Longitudinal Analysis - Track burnout patterns over months, not just days Organizational Benchmarking - Compare team burnout to industry averages Mobile App - React Native version for on-the-go assessments Advanced CV - Pupil dilation analysis, micro-expression detection
Built With
- computer-vision
- css3
- flask
- html
- javascript
- machine-learning
- python

Log in or sign up for Devpost to join the conversation.