BunqShield
Inspiration
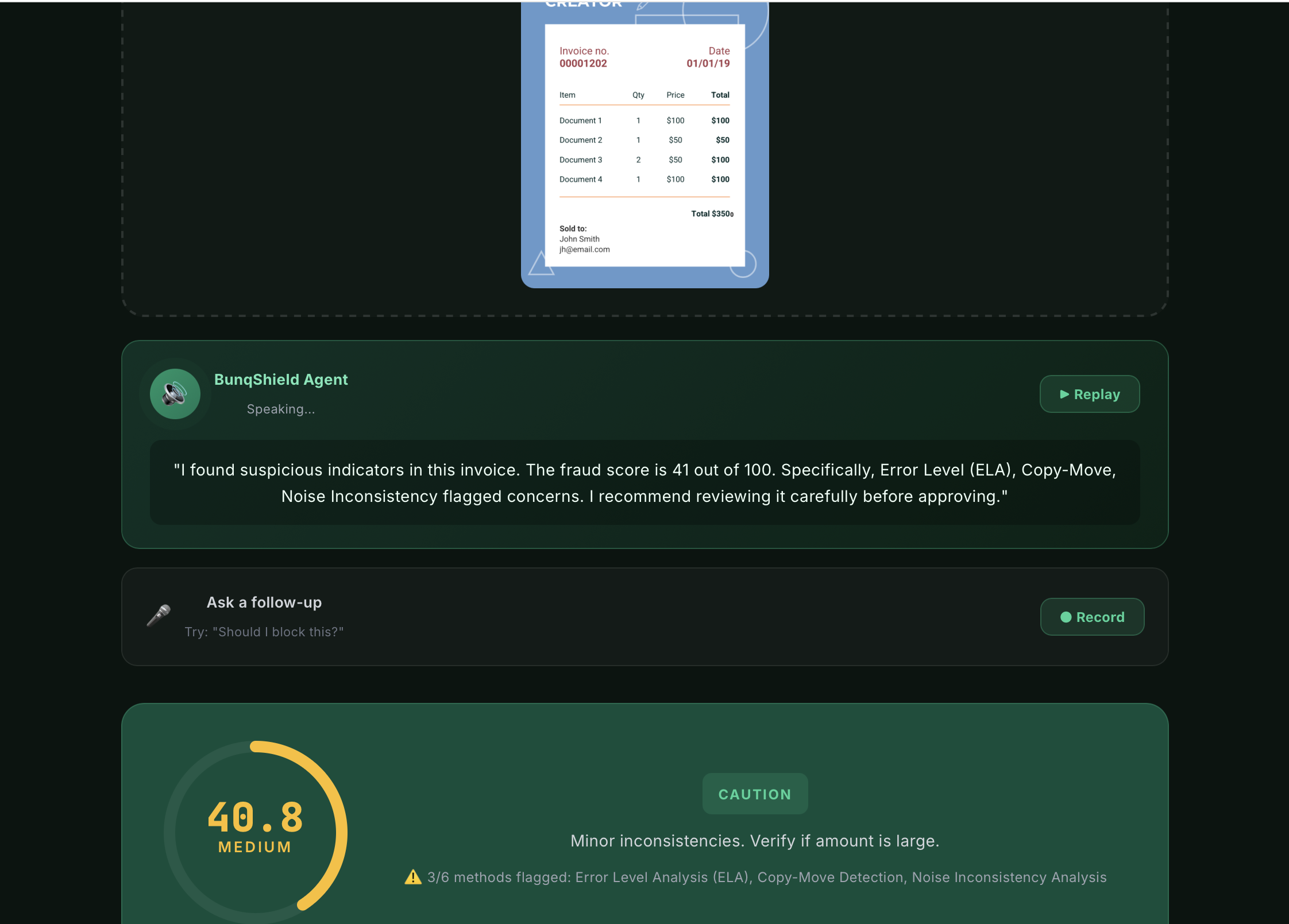
bunq already does an incredible job protecting users from fraud — transaction monitoring with NVIDIA RAPIDS, deepfake detection during KYC via DuckDuckGoose, and Sardine for rule-based fraud prevention. But while researching bunq's stack, we noticed something missing: nobody actually looks at the invoice image itself.
Fraudsters today routinely Photoshop amounts, splice fake totals onto real receipts, or generate entirely synthetic invoices using AI image generators. Once a tampered invoice gets uploaded, the existing rule engines have no visual evidence to flag it the fraud sneaks through.
That's the moment BunqShield was born. With Hackathon 7.0 explicitly asking for a multi-modal AI that doesn't just respond, but acts, the alignment was perfect: an autonomous agent that sees the document, hears the user, decides, and intervenes before money leaves the account.
What it does
BunqShield is an autonomous multi-modal AI agent that protects bunq users from invoice fraud in real time:
- Sees the invoice — runs six forensic computer vision methods (Error Level Analysis, Copy-Move Detection, Noise Inconsistency, Font Consistency, Metadata Forensics, Edge Coherence) plus a Dual-Stream Vision Transformer to score the document on a 0–100 scale
- Reasons about findings — Claude LLM interprets the forensic evidence in a ReAct loop, deciding the appropriate action
- Speaks the verdict — gTTS auto-explains the decision out loud, so the user understands why without reading anything
- Listens to follow-ups — Whisper transcribes microphone input for natural conversation
- Acts on the bank — autonomously converts suspicious payments to draft-payments via bunq's API, requiring manual approval before the money moves
The user experience: drop an invoice → hear the AI explain it → see the verdict → trust the decision. No manual review, no rule-writing, no waiting.
How we built it
Backend (Python):
- FastAPI server exposing 11+ endpoints for analysis, voice, and bunq integration
- OpenCV + scikit-image + NumPy for the 6 classical CV detection methods
- PyTorch + timm for the Dual-Stream Vision Transformer architecture (ViT-Tiny/16 backbone, RGB + ELA streams, cross-attention fusion, patch-level attention heatmaps)
- OpenAI Whisper for speech-to-text transcription
- Google Text-to-Speech (gTTS) for natural speech synthesis
- Anthropic Claude SDK powering the ReAct agent's reasoning loop
- Official bunq Python SDK for live sandbox connection (RSA signing, session management, draft-payment creation)
Frontend (React + Vite):
- Drag-and-drop invoice upload zone
- Inline microphone capture via Web Audio API
- Auto-playing voice responses with replay button
- Animated score ring + per-method breakdown
- Dark emerald theme inspired by bunq's brand
ML Pipeline:
- PDF → PNG conversion script using
pdf2imageand Poppler - Synthetic forgery generator with 4 attack types (copy-move, splice, amount overwrite, recompression)
- Authentic image augmentation (rotation, blur, color jitter) for class balancing
- Balanced training script with class weights, weighted random sampling, label smoothing, cosine annealing, and early stopping
Architecture pattern: The agent uses the ReAct (Reasoning + Acting) loop: it thinks about what to do, calls a tool, observes the result, and decides the next action all autonomously, without a human in the critical path.
Challenges we ran into
- ViT training on tiny data: We trained a Dual-Stream ViT-Tiny on ~150 synthetic images. The model achieved 89% balanced validation accuracy but didn't generalize well to held-out real invoices a known limitation of Vision Transformers on small datasets. We pivoted: kept the architecture and training pipeline production-ready in the repo, and focused our live demo on the classical CV pipeline that produces meaningful results without training data.
- bunq API authentication: bunq's API requires RSA key pair signing, installation registration, device-server creation, and session tokens a non-trivial multi-step handshake. Our first attempt with a custom HTTP client returned
connectedstatus but withnulluser/account IDs because the RSA signing wasn't implemented correctly. We switched to the official bunq Python SDK, which solved it cleanly and gave us a real live connection (verifieduser_id=3629568, account_id=3621708). - Class imbalance after augmentation: Our first balanced run still had imbalance issues the model learned to always predict "forged" because that was the majority class. We added weighted sampling, class-weighted loss, and balanced accuracy as the early-stopping criterion to fix this.
- Browser autoplay restrictions: Modern browsers block auto-playing audio without user interaction. We solved it by triggering the audio playback inside the user's drag-and-drop event handler, which counts as a user gesture.
- Time pressure: Building a full multi-modal pipeline (vision + audio + agent + bunq integration + frontend) within hackathon hours required ruthless prioritization. We focused on what could be demonstrated end-to-end and what would survive a live demo without breaking.
Accomplishments that we're proud of
- Live bunq sandbox integration that actually works — not mocked, not simulated. The agent really connects, really fetches payments, really creates draft-payments.
- A genuinely multi-modal pipeline — vision (CV + ViT), text (Claude reasoning), and audio (Whisper + gTTS) all working together in a single autonomous loop. This isn't three separate features bolted on; it's one integrated system.
- Six classical CV methods that produce real, explainable results — every score is traceable back to a specific forensic technique, with confidence levels and supporting evidence.
- Production-grade ViT architecture — Dual-Stream design with cross-attention fusion is a research-paper-level architecture, not just a textbook model. Training pipeline includes class weights, weighted sampling, early stopping, and label smoothing.
- An autonomous agent with real authority — not a chatbot. The ReAct agent calls 6 tools and takes actions on the user's bank account.
- A frontend that feels finished — animated score rings, per-method bars with risk-color coding, microphone integration, auto-play voice responses, and a dark-emerald aesthetic that fits bunq's brand.
What we learned
- Architectural complexity can outpace data. Our Dual-Stream ViT design is sophisticated, but small datasets win architectures don't. We learned firsthand that ViTs need tens of thousands of images to generalize, and there's no shortcut. Knowing when to fall back to classical methods is a real engineering skill.
- Official SDKs save hours. Trying to implement bunq's RSA-signed API by hand was a rabbit hole. The moment we switched to the official Python SDK, everything worked. Lesson: trust the maintained tooling.
- Multi-modal isn't multi-feature. Anyone can add a microphone button to an app. True multi-modal AI is when the modalities reinforce each other in a single decision loop that's what makes BunqShield different from a chatbot with a voice gimmick.
- Honest limitations beat exaggerated claims. Documenting the ViT's training limitations upfront in the README is more credible than hiding them. Judges can verify code; they can't verify hype.
- The ReAct agent pattern is incredibly powerful. Giving an LLM a small set of well-defined tools and letting it orchestrate them produces emergent, useful behavior with surprisingly little code.
What's next for BunqShield
- Train the ViT on DocTamper — the 170k-image document tampering dataset. With proper data and GPU training, we expect 90%+ accuracy and meaningful patch-level heatmaps.
- Fine-tune on bunq-specific invoice patterns — partner with bunq to access anonymized real invoice/receipt data for domain-specific tampering detection.
- Production webhook deployment — register the
notification-filter-urlcallback in production so every new invoice upload triggers BunqShield automatically without user action. - Multi-language voice support — extend Whisper and gTTS to Dutch, German, French, and Spanish to match bunq's European user base.
- Active learning loop — when the agent flags an invoice and a human reviewer confirms or rejects it, that signal feeds back into model retraining.
- Native mobile integration — embed BunqShield directly in the bunq mobile app, so the security check happens on-device before the invoice is even uploaded to the cloud.
- AI-generated invoice detection — extend the pipeline specifically to detect invoices created by Stable Diffusion, DALL-E, and ChatGPT, the next frontier of fraud.
Built With
- amazon-web-services
- fastapi
- pycharm
- python
- react
- vision-transform


Log in or sign up for Devpost to join the conversation.