-
-
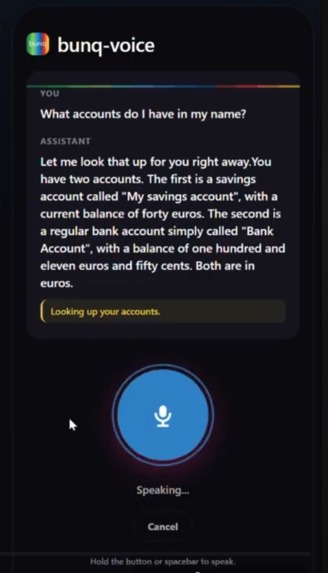
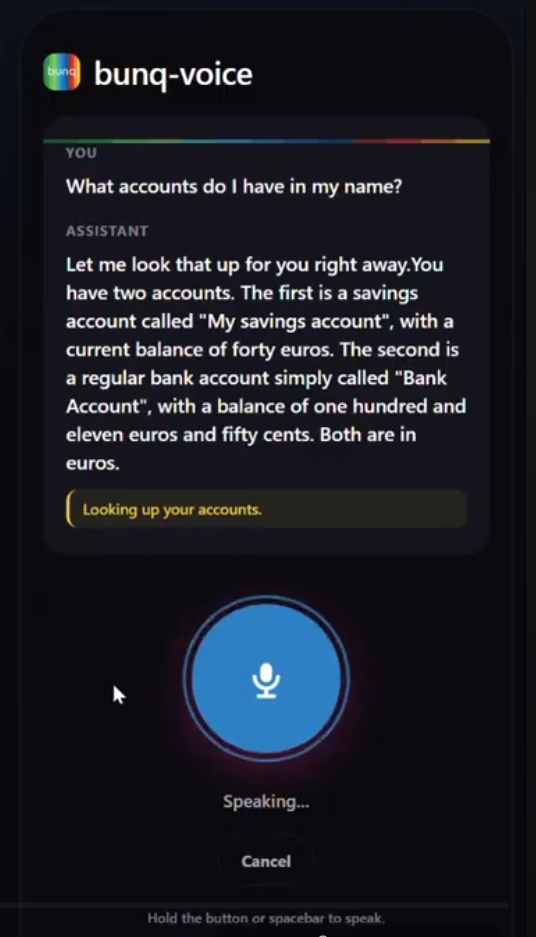
Checking Balance
-
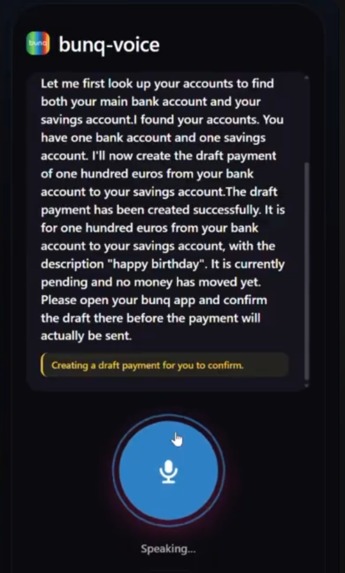
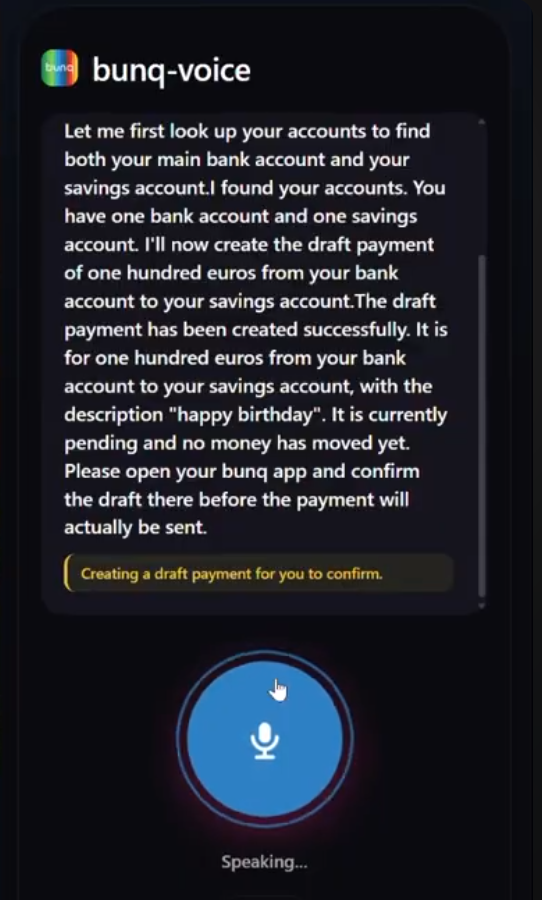
Transfer
Inspiration
bunq calls itself “the bank of the free.” That promise breaks down for users who can’t see or physically use the app. The same security measures that protect mobile banking — shielded UI surfaces — also block screen readers and assistive tools. A blind or motor-impaired user can have a bunq account, but can’t actually run their finances. That’s not freedom.
The insight: bunq already has the right security primitive — draft payments. Proposing a payment is separate from authorizing it. An AI can handle intent and create drafts, while the existing bunq app keeps full control of authorization via biometrics. No new attack surface, no weakened security — just accessibility where it was missing.
What it does
Bunq Voice is a voice-first banking interface. Hold-to-talk, speak naturally —
“What’s my balance?” · “Send €50 to Lanita for her birthday.” · “Did Mom’s payment go through?”
The system transcribes speech, reasons over bunq accounts, calls the correct APIs, and speaks results back. Every payment is created as a PENDING draft and must be approved in the bunq app using the same biometric flow users already trust. The AI talks; bunq authorizes.
It works end-to-end against a real bunq sandbox: speech → bunq API → speech back. Seven voice-optimized tools cover the demo flow (accounts, balances, transactions, counterparties, draft payments, and draft status). Audio playback is continuous and natural, without gaps or sentence clipping.
How we built it
Five-package monorepo, spec-driven from day one:
packages/shared → Pydantic models (single source of truth)
packages/bunq-client → Thin wrapper over bunq_sdk
packages/mcp-server → FastMCP server exposing 7 tools
apps/voice-agent → FastAPI WebSocket server (STT → LLM → TTS)
apps/web → React mic UI + custom audio player
All interfaces were defined before code. Pydantic models in packages/shared drive everything — including generated TypeScript types — so contracts never drift.
Voice uses xAI Grok for both STT and TTS, Claude Sonnet 4.6 for reasoning with native tool use, and the official MCP Python SDK over stdio. LLM streaming and TTS streaming run concurrently via asyncio, so the next sentence is generated while the current one plays — no dead air.
Key challenges
- bunq-sdk broke backward compatibility by renaming all generated classes and removing fields without documentation. We fixed this with aliases and defensive access.
- MP3 streaming caused audio artifacts due to per-chunk decoder priming in browsers. Fix: buffer per sentence server-side and decode once client-side.
- LLM output and TTS originally blocked each other, causing pauses. Fix: decouple them with concurrent tasks and a sentence queue.
- Voice users can’t recite IBANs. We added name-based recipient lookup via transaction history.
- Midway pivot from ElevenLabs + Groq to xAI Grok simplified the entire audio stack.
- Demo-day issues (schema mismatch, React StrictMode, missing env vars) were all fast fixes — but only after painful discovery.
What we’re proud of
- True end-to-end demo against a real bunq sandbox — no mocked flows.
- Draft-only write access by design: the AI cannot move money. Humans approve everything.
- Voice-native tools: no numeric IDs, no IBANs, no UI assumptions.
- Natural, uninterrupted audio playback that sounds human, not robotic.
- Spec-first teamwork: three engineers, parallel branches, zero contract fires.
What we learned
- MP3 isn’t stream-friendly without buffering.
- LLM and TTS concurrency matters as much as model quality.
- bunq’s draft-payment flow is exactly the right boundary for AI banking.
- One audio provider beats stitching multiple APIs together.
- Spec-driven development pays off fast under hackathon pressure.
- Audio defects are instantly noticeable — there’s no hiding latency or silence.
What’s next
- Production bunq integration
- More tools (cancel drafts, transfers, recurring payments)
- Multilingual voice support
- Native bunq app integration
- Learned user context (“send my usual to Mom”)
- Audio cues for blind users
- Safe, explicit conversation memory across turns
Built With
- anthropic
- fastapi
- fastmcp
- mcp
- pydantic
- react
- uv
- uvicorn
- vite
- xai

Log in or sign up for Devpost to join the conversation.