BunnyNotes
BunnyNotes is a platform developed to perform fast and reliable text analysis, in particular, generating text summaries. BunnyNotes is built entirely in VueJS and deployed on Vercel.
Emily Ong
Inspiration
Long chunks of text are too wordy and verbose. It is hard to find the gist of the text and we often spend too much time circling around a topic without understanding it.
User Interface
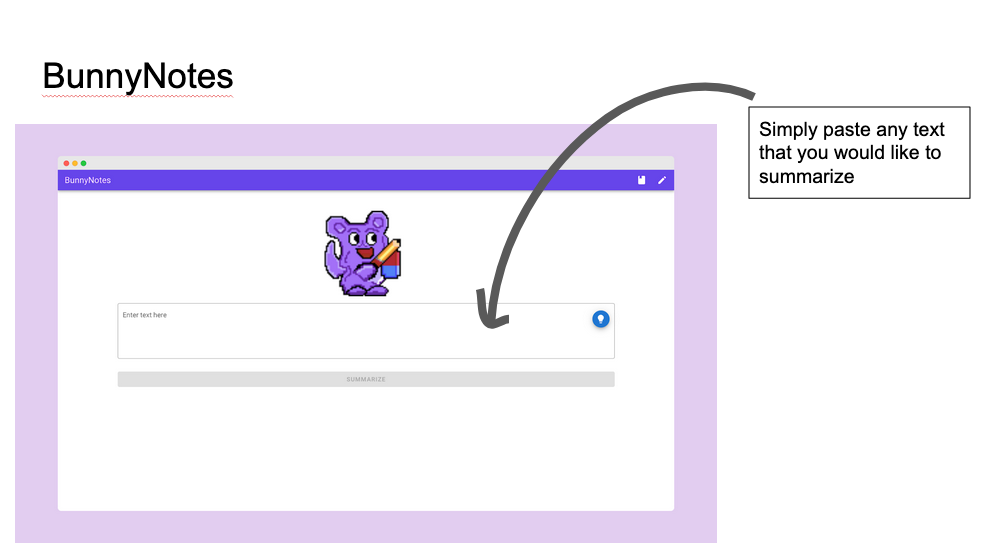
Thus, we propose BunnyNotes. It features a clean and intuitive interface. Users can simply paste any English-language text that they would like to summarise.
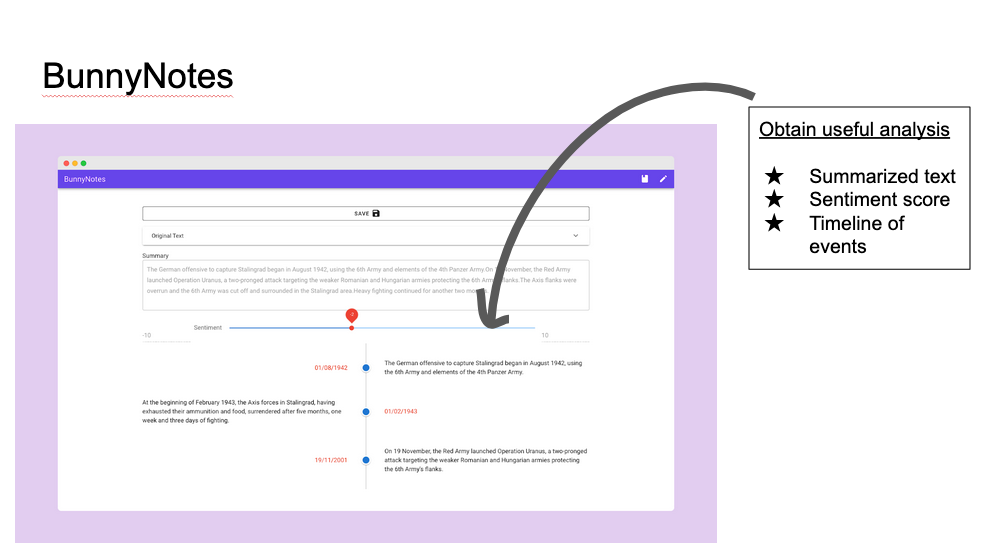
Within milliseconds, useful analysis is displayed on the screen, providing users with a summarised version of the text. A sentiment score ranging from -10 to 10, based on the positives and negatives statements within the text, is generated. Finally, a timeline is displayed, providing a high-level overview of events that has occured.
Within BunnyNotes, users can choose to save the summarised notes, which are stored in the local storage.
Extraction-based text summarization
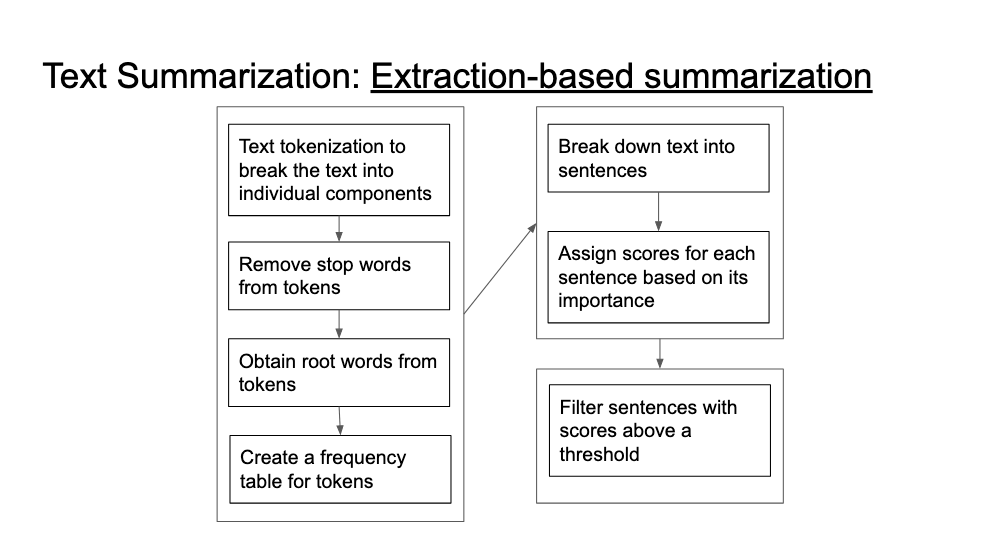
Moving on to the core algorithms underpinning the web application, we implemented an extraction-based summarisation for generating text summaries. First, we tokenise the text into individual building blocks, breaking up into core words that ease processing. Stop-words such as 'aside', 'up', 'down' are also removed, as they are commonly-used words in forming a sentence, with little value-add to the core meaning of the text itself. Then, we obtain the root words from tokens through a process known as stemming. For example, the root word of 'hacking' is 'hack'. We then create a frequency table for the tokens, allowing us to use it in our scoring mechanism, where sentences with tokens of higher occurring frequency are prioritised. However, we are also aware that this means very long sentences will be assigned a higher score, thus we divide the score with the length of the sentence.
We use a model from winkNLP, a Javascript natural language processing library, which offers fast performance, reducing lag and waiting time, as well as high accuracy, providing good reliability.
Future Plans
In view of the time constraints, there were nice-to-have features that could not be implemented in time. In the future, we would like to investigate abstraction-based text summarisation, which allows novel sentences from the text to be generated, that are possibly less verbose. Another feature would be topic modelling, to classify text into topics, providing an abstract overview of what the text is about.



Log in or sign up for Devpost to join the conversation.