-
-
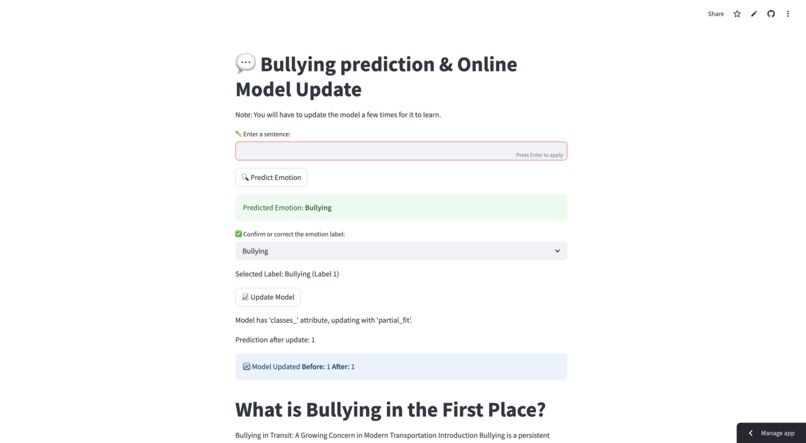
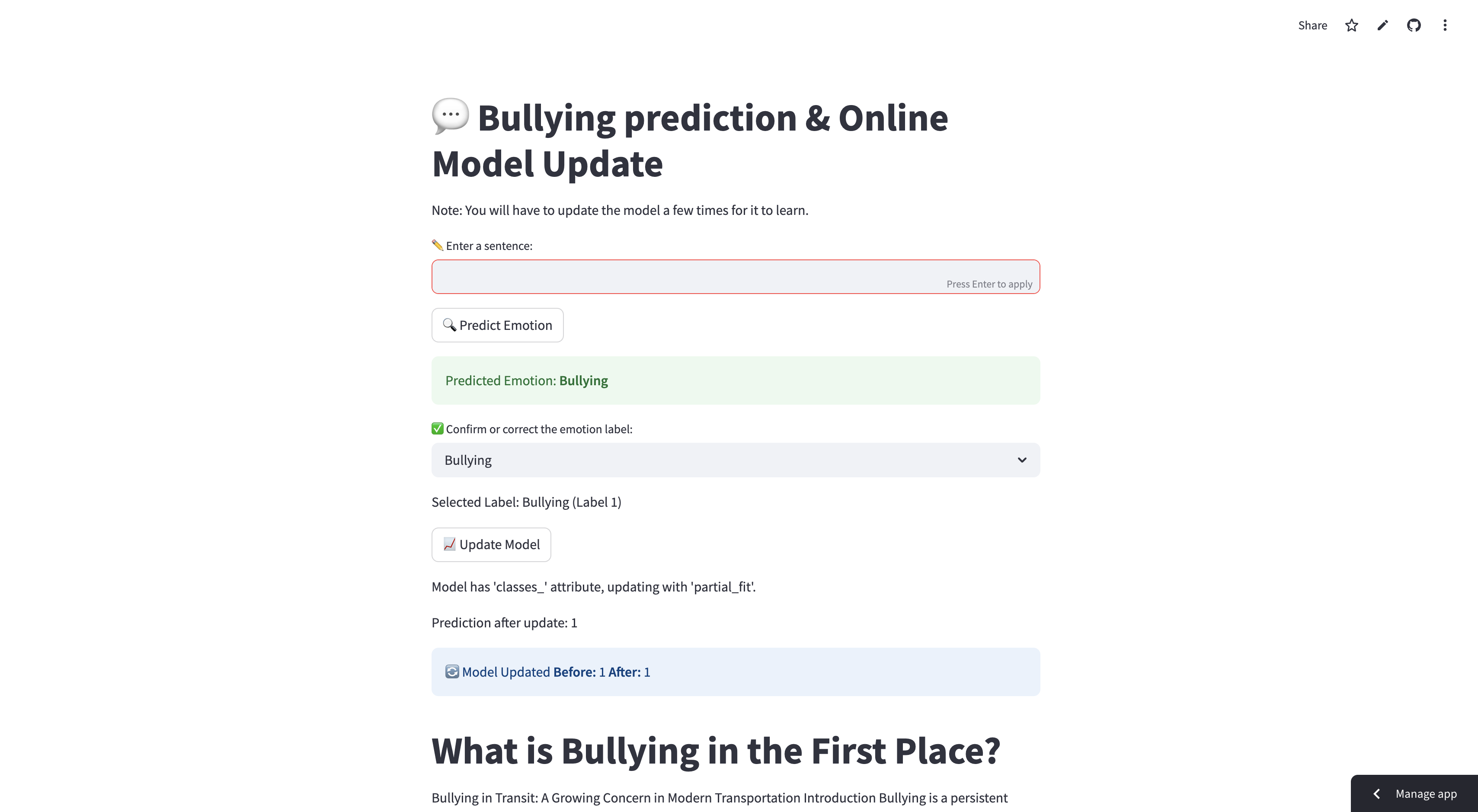
The Bullying Classifier
-

Article About Bullying Part 1
-

Article About Bullying Part 2
-
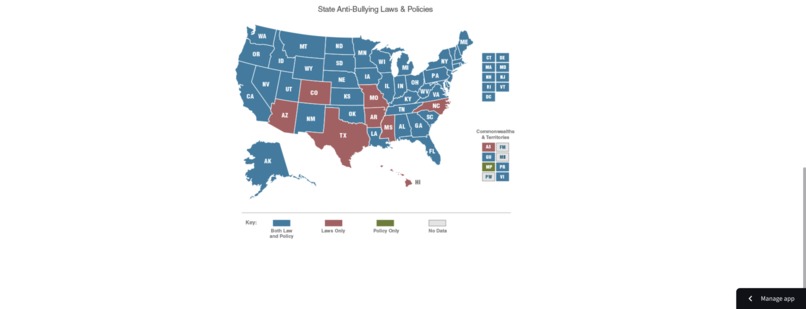
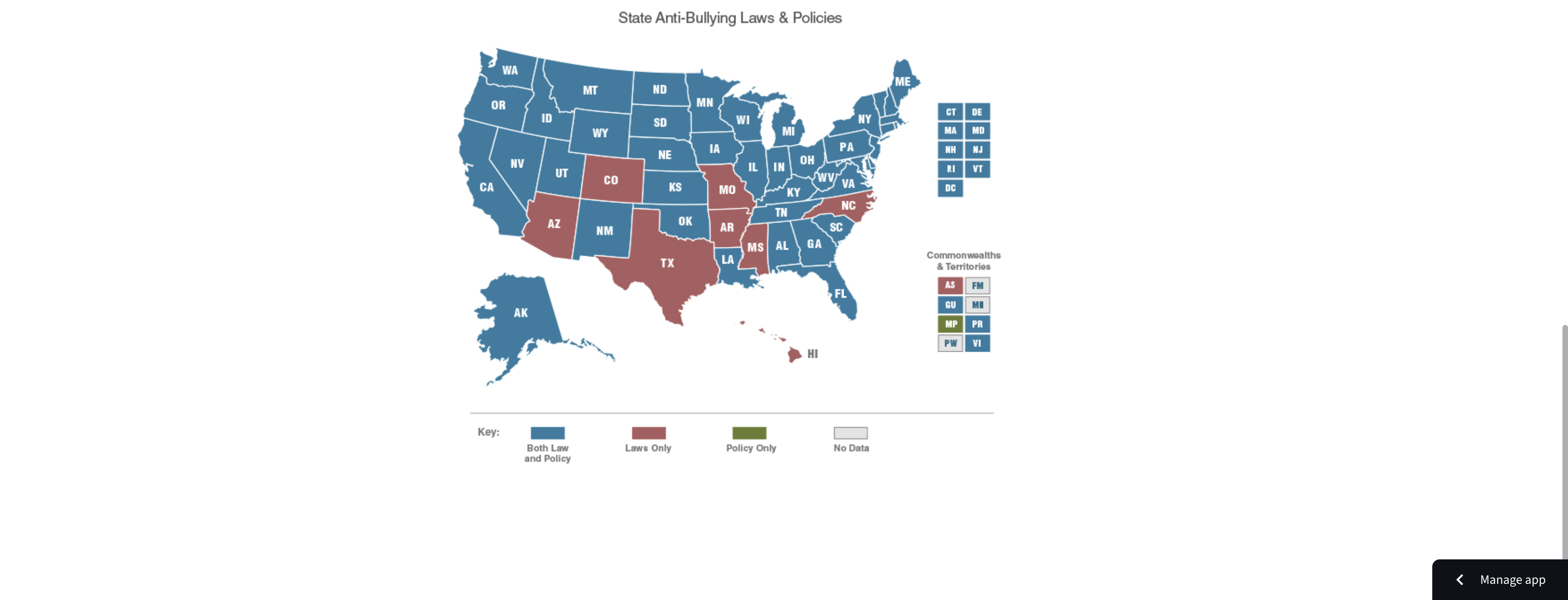
Graph About State Anti-Bullying Laws And Policies


Inspiration: I was inspired to create an AI that could identify bullying in text because, in various modes of transportation, people often say offensive things to each other. I specifically thought about school buses, as kids who are bullied frequently can become depressed, sometimes leading to suicidal thoughts. I wanted to solve a problem that many people, especially schoolchildren, face while traveling.
What it does: When you enter some text in the textbox and click "Predict," the classifier determines if the statement is bullying or not. If the prediction is wrong, you can select the correct label and click "Update Model." When updated, the model improves and will perform better the next time it encounters the same or similar sentences.
How we built it: We first gathered data for bullying and non-bullying sentences from Kaggle. After cleaning and preprocessing the data, we converted each word into numbers based on how frequently that word appeared in the dataset (using a technique called vectorization). Each sentence was labeled as either bullying or non-bullying. We passed these numerical representations into an SGDClassifier, which learned patterns in the data—identifying which words were more common in bullying statements and which were not. During training, the loss was calculated based on how far off the model's predictions were from the true labels. The model's weights were updated based on this loss, and this process repeated for up to 1,000 iterations. We saved the trained model and the vectorizer using pickle files. For the user interface, we used Streamlit, a Python library that makes building web apps easy. We also created a training loop: if a user corrects a wrong prediction on the website, the model updates itself, improving its accuracy over time.
Challenges we ran into: We faced difficulties finding good-quality data for training our classifier. In machine learning, good data is essential for accurate models. We also ran into issues while saving and loading the pickle files, as sometimes the files became corrupted. Despite facing many other challenges, we didn't give up and kept trying until the project worked as we expected.
Accomplishments we're proud of: We are proud of building an AI that tackles a real-world problem affecting many people worldwide. We are especially proud of implementing an online update loop, allowing the classifier to learn continuously as users interact with it.
What we learned: We learned that perseverance is key—no matter how many obstacles we encounter, we can achieve anything we put our minds to if we don't give up. We also learned the importance of teamwork and good communication. Building strong relationships with teammates made the work faster, smoother, and more efficient.
What's next for our project: We plan to introduce voice input to our classifier so that microphones can be installed on school buses to detect bullying conversations between students. By identifying and addressing bullying early, we hope to create a safer environment for children, helping to eliminate the use of insults and swearing.
Built With
- css3
- github
- google-colab
- html5
- huggingface
- kaggle
- machine-learning
- modelevaluation
- natural-language-processing
- numpy
- onlinemodelupdateloop
- opendatasets
- pandas
- pickle
- python
- scikit-learn
- streamlit
- streamlit-cloud
- textvectorization
- vscode

Log in or sign up for Devpost to join the conversation.