-
-
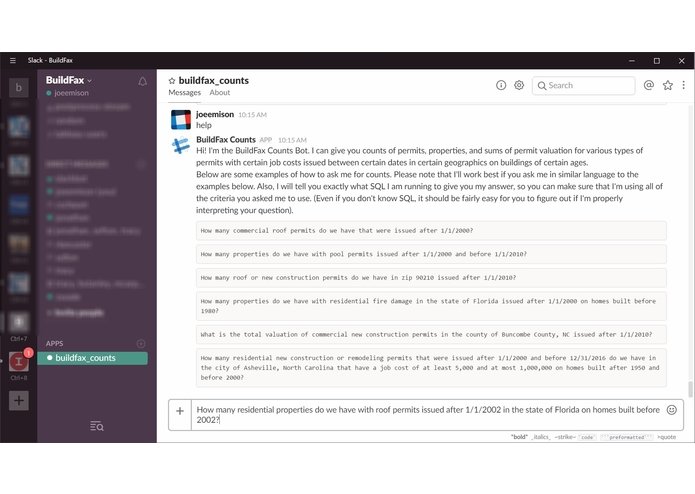
Screenshot from the BuildFax Counts Bot
Inspiration
At BuildFax, we have the only national database of building permits, updated monthly. We have run our infrastructure on AWS since we started in 2008, but our database is structured to deliver single-address building-permit reports quickly and easily, as opposed to facilitating whole-database queries.
As we have grown, our sales and marketing teams increasingly have wanted to know what's in our database, but those questions have had to be referred to an internal sales support team that has written SQL that has to be run across our various sharded databases in order to get answers--and given the number of requests, and the time it takes to set up the queries, getting answers always takes at least several days, and sometimes more than a week.
Growing frustration with the delays in getting the answers was the inspiration for the BuildFax Counts Bot in Slack.
What it does
With the BuildFax Counts Bot, most of the questions that would have had to be sent as tickets to the sales support team can now just be typed into Slack, and they get their answer in seconds. The phrasing that the BuildFax Counts Bot supports is based upon the specific language that the sales and marketing teams have used in their internal tickets to BuildFax, so that the actual workflow for a member of the sales and marketing team is essentially the same, just now in Slack--no one needs to learn anything new.
How I built it
First, I set up a nightly export of our data from our MySQL RDS instances to CSVs, which I put on S3 and then created an AWS Athena table from those files. Without Athena, the queries wouldn't execute quickly enough.
Second, I set up a Lex bot to handle the common types of questions and criteria that the sales and marketing teams have about our national permit database. I used (as closely as possible) the language from our ticketing system so that Lex would be as natural an interface as possible. It was somewhat tricky to get Lex to understand the wide variety of criteria that needed to be supported (e.g., what type of count: a count of properties, a count of permits, a sum of permit valuations; which geography: supporting zip codes, cities, counties, and states; what date ranges on the permits; year range on the age of the building; job cost range on the permits; what types of permits). However, by adding many different sample utterances with slot types embedded, and a few custom slot types, I was able to parse correctly every different type of question and combination of criteria I set out to support.
Finally, I wrote a Lambda function in JavaScript that takes the incoming Lex intent, uses it to build a SQL statement, runs that statement against Athena using the aws-sdk library, and returns both the SQL and the count/sum.
Challenges I ran into
The first big challenge I ran into was in training Lex with sample utterances. Even when I replicated the exact utterance I put in as training, sometimes it would fail to properly parse the request. For example, I wanted to support saying something like "with a job cost between 500 and 5000 on homes built between 1950 and 2000", but then when I submitted "with a job cost between 500 and 5000" on its own, sometimes the 5000 would end up in the maximum-year-built slot. I ended up having to change some language around here to be unique to each slot, so it needs the request to be something like "with a job cost of at least 500 and at most 5000 on homes built after 1950 and before 2000".
The second big challenge I ran into was communicating with Athena from Lambda, because I used Google and StackOverflow searches to find the best way to do this, and the recommendations out there were to use Node's JDBC package with the custom Athena JDBC driver. This was a nightmare to deal with, and when I brought this up on Twitter, several people came to my aid (in particular, @EwanToo and @rahulpathak) and pointed out that the latest aws-sdk package has Athena support. That worked fairly well (although it was a bit annoying to handle the somewhat-complicated flow of query-then-check-status-repeatedly-then-get-results).
Finally, it was a bit challenging to figure out how to handle the US_State Slot Type, since Lex doesn't send a nicely-formatted State object (which I was hoping would always be the US State abbreviation), but instead can send either the full name of the state or the abbreviation... And, in my attempts to handle geographic parsing within Lex, I realized that if I'm getting a City or a County, I needed to make the slot send both the city/county and the state in a single slot (it just didn't work properly to get them in separate slots--too hard for Lex to parse). So I had to built a somewhat hackish function to extract out the City or County (if supplied) and State, but it seems to work quite well now that it's built.
Accomplishments that I'm proud of
I'm quite proud of the whole setup I have built here: the exports to Athena (which are very easy, simple to maintain, and are a ridiculously small number of lines of code); the Lex bot (which is also quite simple and compact); and the Lambda function (at just over 400 lines, by far the biggest part of the project, but that's still very small in the grand scheme of things, and also quite easy to support).
And the bot is just cool--it's amazing to have this wonderful database, and to ask clear questions in English to a bot that can give answers in seconds instead of waiting more than a week for sales support!
What I learned
I learned a lot about the capabilities of Athena and Lex. I learned how to train Lex, and what Lex is good at (effortlessly) and what is somewhat complicated in Lex. (For example, it would have been easier to make Lex prompt for the slots, but the Bot works a lot better when you can ignore almost all of the criteria to get a higher-level answer, without having to do anything but ask a single question).
What's next for BuildFax Counts
The sales and marketing teams are already issuing a lot of queries to the BuildFax Counts bot, and they have a number of different requests. The two most common are (a) being able to ask a question that returns a table (instead of a single number) as a CSV that previews in Slack and can be downloaded; and (b) being able to get address-specific BuildFax Reports (which can be PDFs or interactive web pages) through the bot. And I anticipate more and more requests coming in the future.
Built With
- athena
- javascript
- lambda
- lex








Log in or sign up for Devpost to join the conversation.