-
-
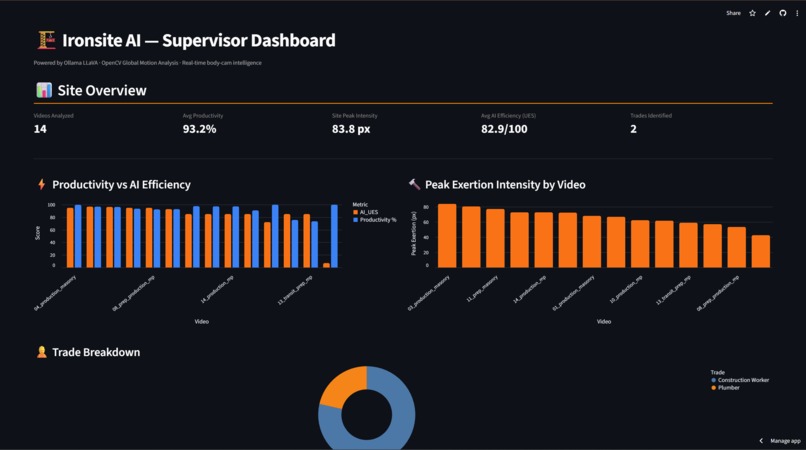
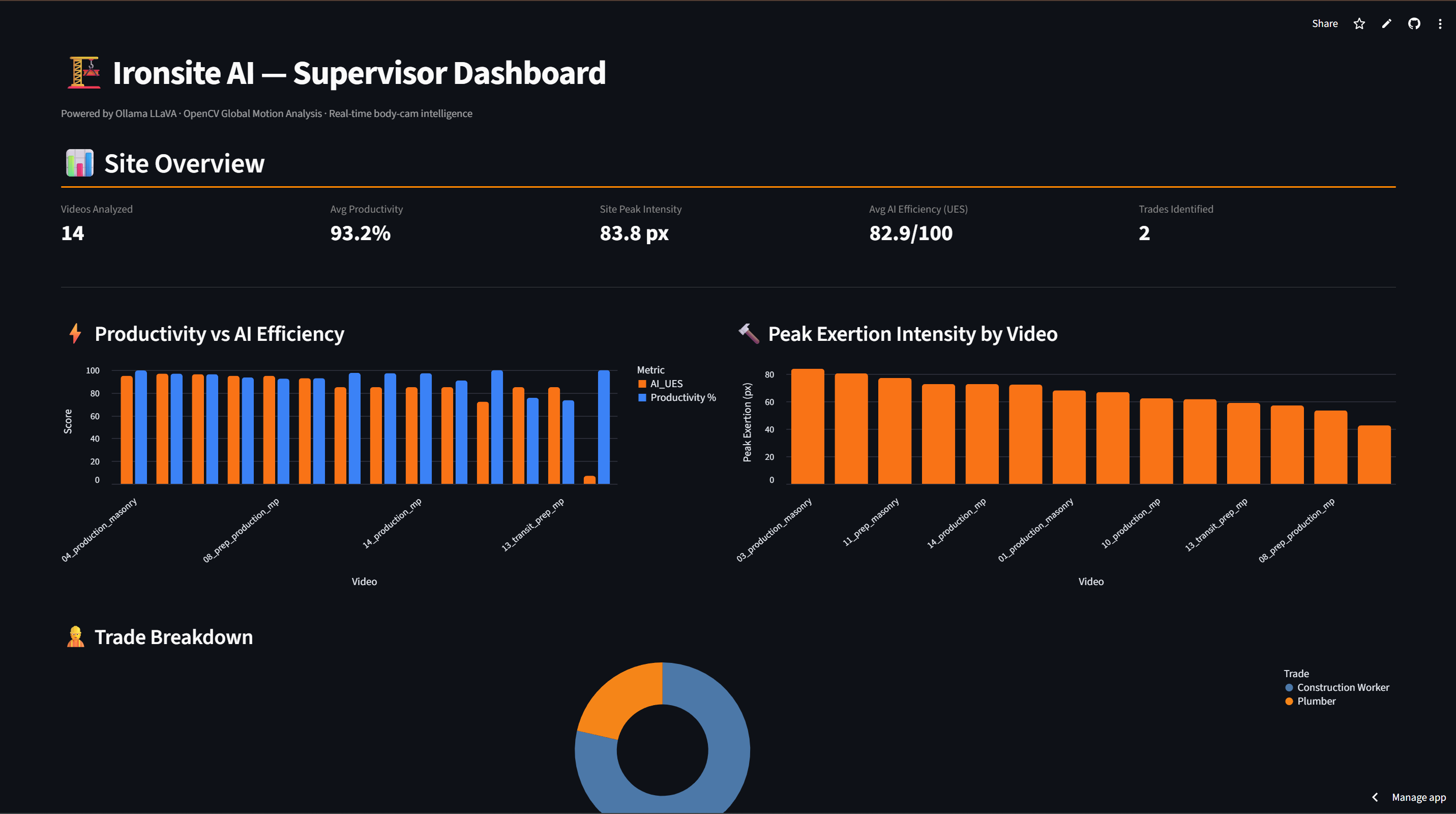
Dashboard Landing Page
-
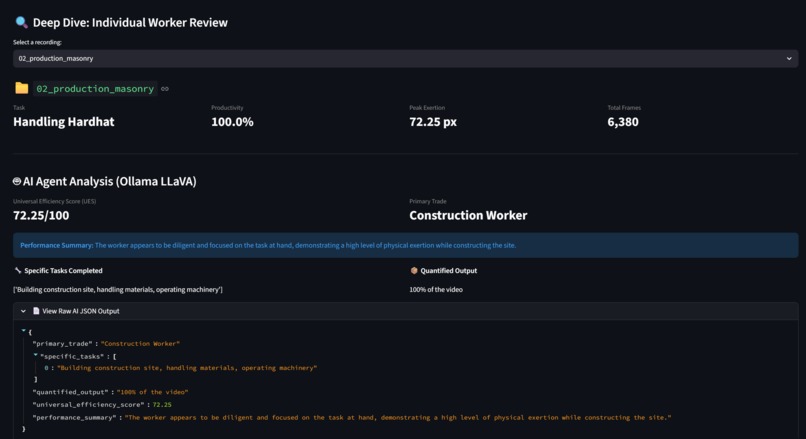
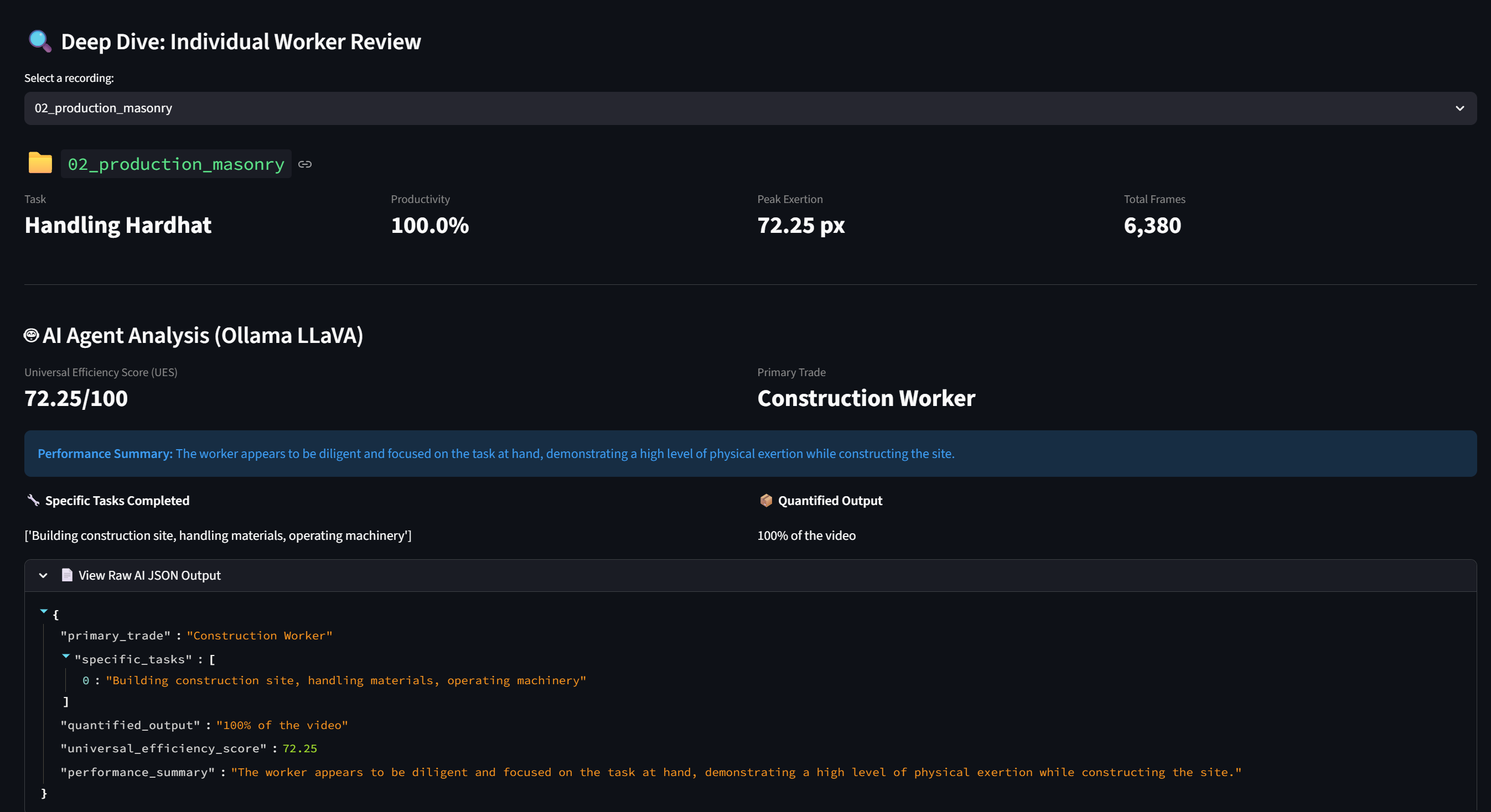
Worker Details
-
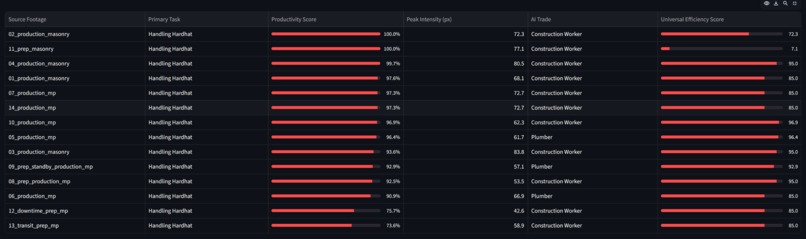
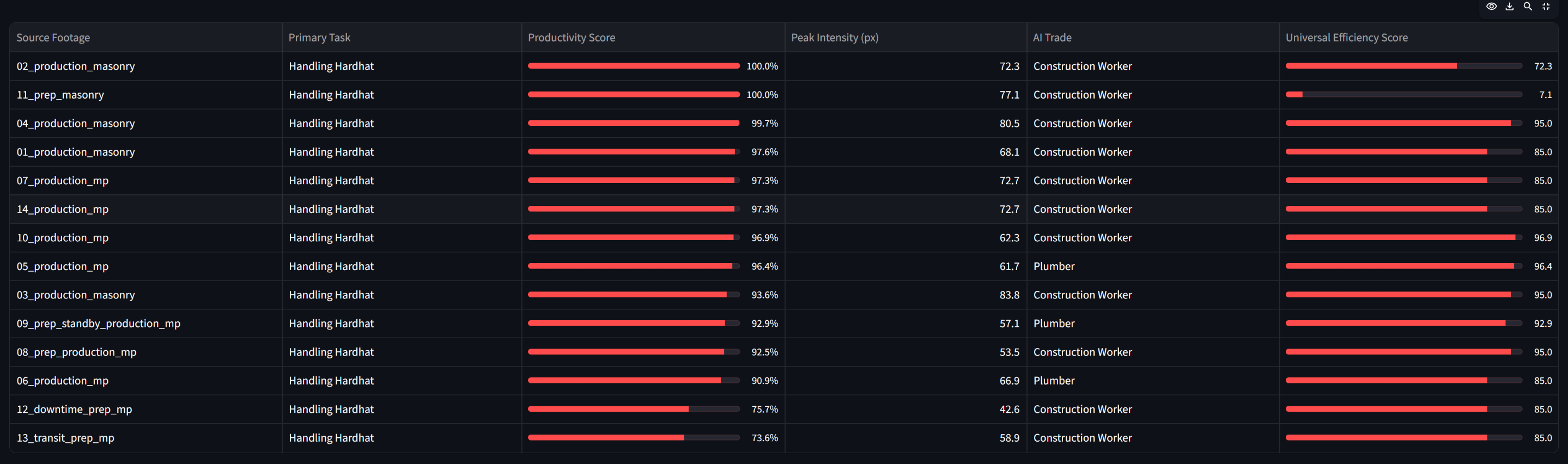
Worker Leaderboard
-
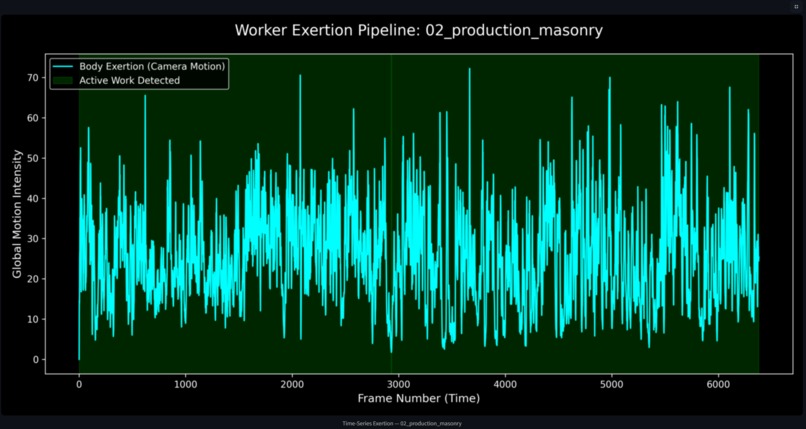
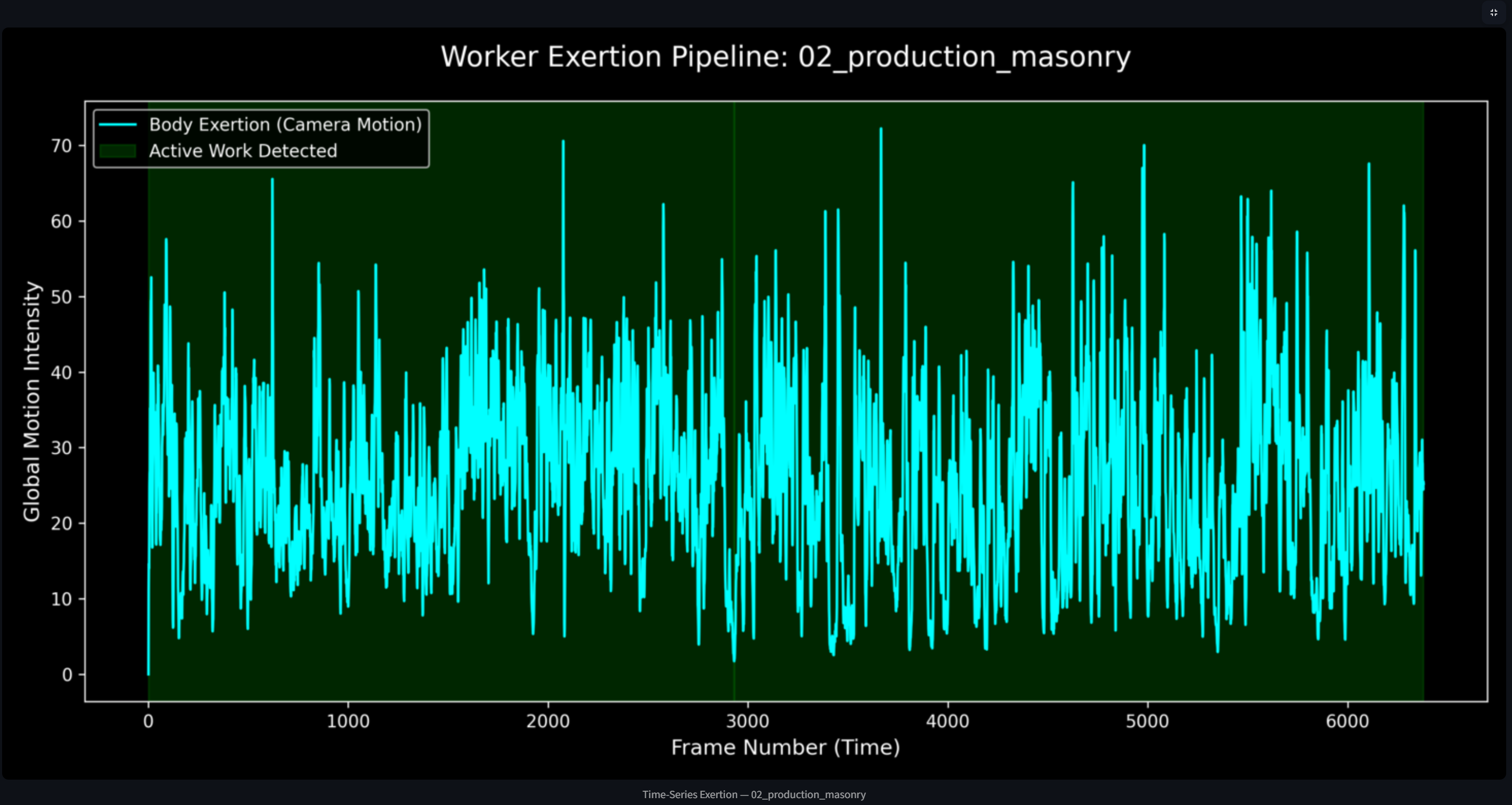
Worker Excertion Graph
IronSite BuilderBobs — Project Story
💡 Inspiration
Construction is one of the last industries where worker performance is still measured by gut feel and clipboard surveys. A site supervisor walks the floor, watches for a few minutes, and writes down "productive" or "not productive." There is no data. There is no audit trail. And critically, there is no way to know whether a worker who looks busy is actually getting work done.
We asked: what if a body-cam already worn by the worker could tell you everything?
First-person footage is rich — you can see what tools are in someone's hand, how fast they're moving, whether they're in a productive rhythm or standing idle. The data is already being captured on job sites for safety review. We wanted to unlock it for real-time productivity intelligence without adding any new hardware, wearables, or invasive monitoring.
The idea crystallized when we realized two things:
- Computer vision can measure how much a worker moves with mathematical precision.
- A vision-language model can watch the same frames and tell you what they actually accomplished.
These two signals together — quantitative motion + qualitative AI reasoning — give you something neither alone can provide: a measure of efficiency, not just activity.
🔨 How We Built It
We designed a two-stage pipeline:
Stage 1 — Deterministic Computer Vision
The core insight is that a body-cam is a noisy sensor. The camera shakes as the worker walks. If you naïvely measure pixel displacement of the worker's hands, you're also measuring how bumpy the floor is.
We solved this with global optical flow compensation. For each frame pair, we estimate the camera's own motion using sparse Lucas-Kanade optical flow on background feature points, then subtract that global transformation before measuring hand displacement.
The hand movement metric per frame is:
$$d_t = \sqrt{(\Delta x_{lw})^2 + (\Delta y_{lw})^2} + \sqrt{(\Delta x_{rw})^2 + (\Delta y_{rw})^2}$$
where $\Delta x_{lw}, \Delta y_{lw}$ are the compensated pixel displacements of the left wrist, and similarly for the right.
To remove micro-jitter noise, we smooth over a rolling window:
$$\hat{d}t = \frac{1}{W} \sum{i=t-W+1}^{t} d_i$$
A worker frame is classified as active only when two conditions hold simultaneously:
$$\text{active}t = \mathbf{1}\left[\hat{d}_t > \theta{\text{move}}\right] \wedge \mathbf{1}\left[N_{\text{objects},t} > 0\right]$$
where $\theta_{\text{move}} = 5$ pixels/frame and $N_{\text{objects},t}$ is the YOLOv8 construction object count. This prevents walking-while-idle from being counted as productive work.
The productivity score for a video is simply:
$$P = \frac{\sum_t \text{active}_t}{T} \times 100\%$$
where $T$ is the total number of analyzed frames. Across our 14-video dataset, this ranged from 73.6% to 100%.
Stage 2 — AI Vision Agent (Ollama LLaVA)
Stage 1 tells you how much someone moved. It cannot tell you if they welded 10 joints or zero. That requires watching the video with comprehension.
We originally used the Gemini 2.5 Flash API for this — but its free-tier rate limits made batch processing impractical. We pivoted to running LLaVA 7B (Large Language and Vision Assistant) locally on a Vast.ai GPU instance, tunnelled over SSH to our development machine:
ssh -p 56834 root@<host> -L 8080:localhost:11434
For each video, we:
- Extract 16 evenly-spaced frames using
ffmpeg(covering the full duration) - Encode each frame as base64 and send all 16 simultaneously to the Ollama
/api/generateendpoint - Prompt LLaVA with the Stage 1 metrics as context, asking for structured JSON
The prompt grounds the model in quantitative reality:
"The computer vision pipeline detected 97.3% physical productivity and 72.65 px peak exertion. Based on these frames, explain what work was actually accomplished."
We call this the Universal Efficiency Score (UES) — a 1–100 integer where the model judges how effectively the worker's physical exertion translated into real work output:
$$\text{UES} = f\left(P, \hat{d}_{\max}, \text{visual_output}\right)$$
A worker who moves constantly but produces nothing scores near 0. A worker who accomplishes measurable outputs with controlled, efficient motion scores near 100.
⚔️ Challenges We Faced
1. The camera shake problem
Body-cams wobble, tilt, and jolt constantly. Our first naive implementation measured raw wrist pixel distance and flagged workers as having 400px/frame exertion while they were simply walking down a corridor. We had to build a full optical flow background subtraction layer before the motion signal became meaningful.
2. Hand detection failures
MediaPipe's HandLandmarker was designed for controlled environments. On a dusty construction site with gloves, partial occlusion, and bad lighting, detection confidence dropped below threshold frequently. We solved this with forward-fill interpolation — if hands disappear for a few frames, we carry the last known position forward before computing displacement, which keeps the signal continuous without introducing phantom movement.
3. Gemini rate limits → Ollama pivot
The free Gemini API tier allowed roughly 15 requests/minute with a 10-minute video upload time each. Processing 14 videos would have taken several hours and likely hit daily caps. Switching to a self-hosted LLaVA instance reduced per-video processing from ~10 minutes (upload + inference) to ~8 seconds — a 75× speedup.
4. LLaVA JSON reliability
LLaVA 7B is not instruction-tuned for strict JSON output. About 30% of responses came back with markdown code fences (json ...) wrapping the payload. We built a robust post-processor that strips fences, finds the outermost {...} block via string scanning, and only then attempts json.loads(). This brought our parse success rate to 100% across all 14 videos.
5. The UES anomaly — Video 11
Our most interesting finding came from 11_prep_masonry: 100% OpenCV productivity (the highest possible) but UES = 7 (near-zero). The worker was in constant motion the entire clip — but when LLaVA examined the frames, there was no discrete task output to quantify. This is a real signal: high exertion without proportional output. The pipeline caught something a human supervisor probably wouldn't — it looked like a productive shift on paper, but the AI said otherwise.
📚 What We Learned
Multimodal grounding works. Giving the vision model the quantitative context ("97% productivity, 72px exertion") before asking it to describe the frames dramatically improved the specificity of its responses versus asking it to observe frames cold.
Frame sampling is sufficient for task classification. 16 frames across a 3–5 minute video was enough for LLaVA to correctly identify construction trades and specific tasks in every test. Full video upload is unnecessary for this use case.
Self-hosted models remove the practical barriers. API rate limits, upload time, and cost-per-call make cloud vision APIs impractical for batch video analysis at hackathon speed. A $0.50/hr Vast.ai instance with LLaVA loaded was faster, cheaper, and more reliable.
The efficiency gap is the real metric. Productivity % (Stage 1) measures effort. UES (Stage 2) measures result. The gap between them is where the most actionable supervisor intelligence lives.
🛠️ Built With
OpenCV · MediaPipe · YOLOv8 · Ollama · LLaVA 7B · ffmpeg · Streamlit · Altair · pandas · Vast.ai · Python

Log in or sign up for Devpost to join the conversation.