-
-
website UI
-

soulread

Inspiration
We’ve worked with kids in many different settings, from autism support programs to hands-on learning environments. Through that time, we’ve always recognized that play, from building robotic toys to playing chess, has been effective in creating progress in children, particularly in social contexts.
Modern therapies based in play for certain developmental disorders have been proven to be effective. For example, a digital therapeutic for children with ADHD is a racing video game that has the effects of longer sustained attention. However, current tech for autism therapy either treats therapy as rigid drills or creates games for pure entertainment.
Our goal was to fill the gap, creating an experience where emotional insight, movement, and play can teach real developmental skills. So we asked: what if a game could “feel” where a child is emotionally and use clinically validated frameworks to guide them through growth, playfully?
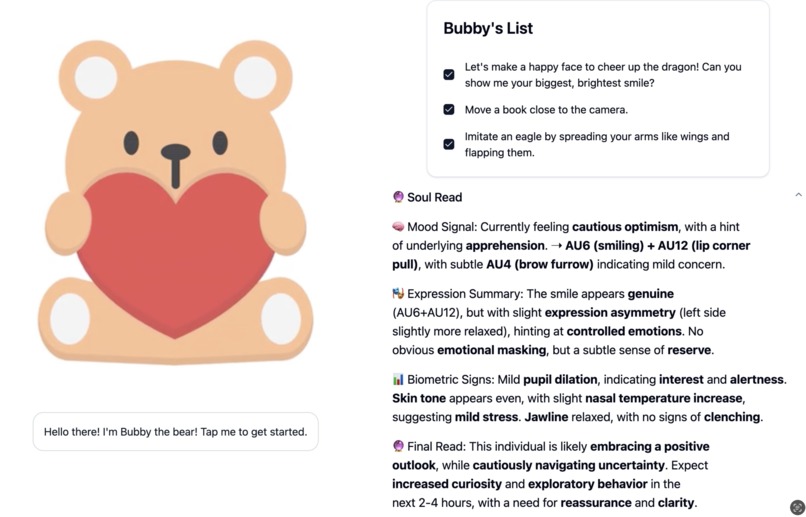
What it does
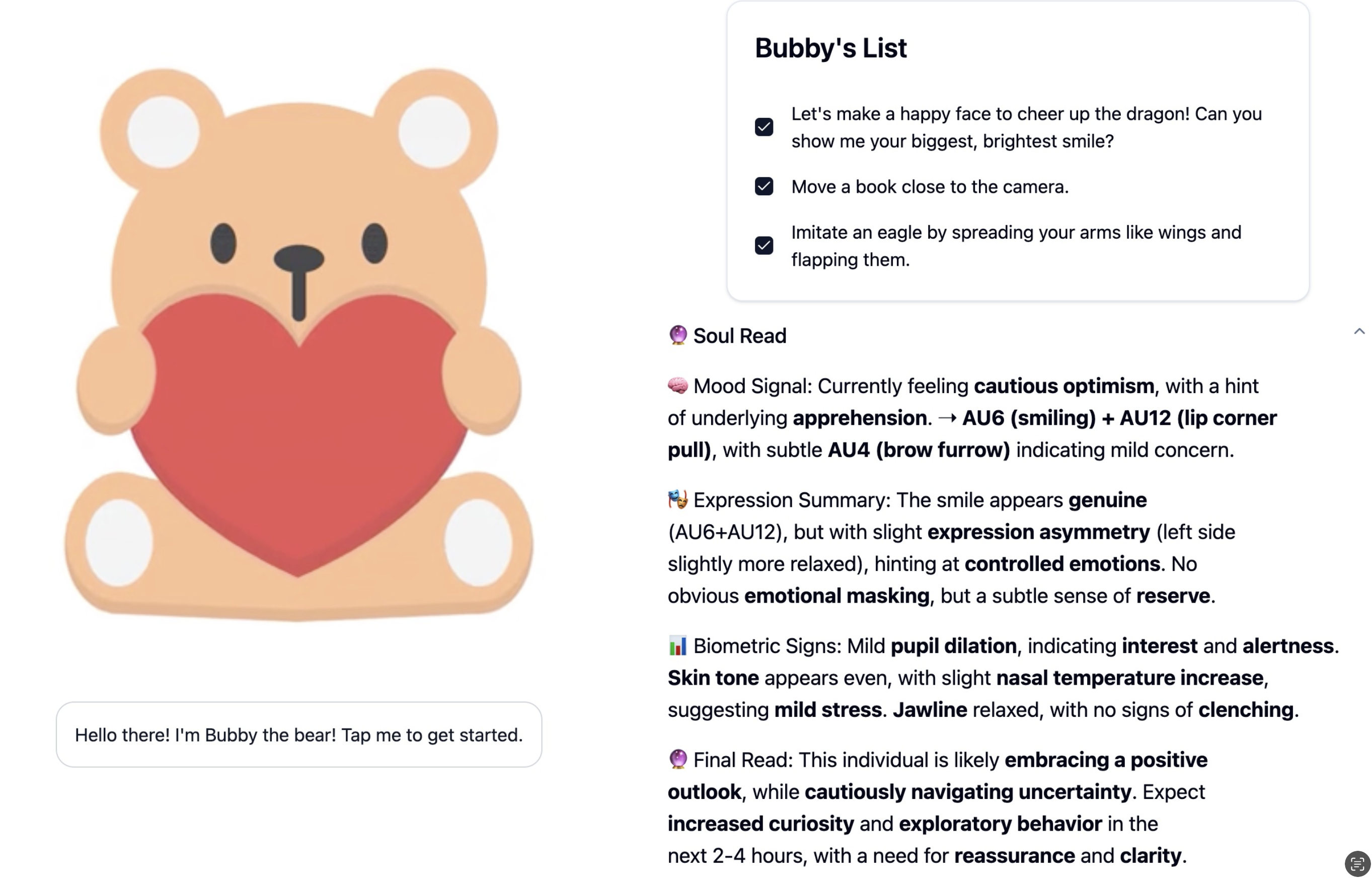
The foundation of our system is our innovative SoulReadAI. Analyzing 30 action units based on the Facial Action Coding System (FACS), our facial recognition software provides a uniquely in-depth analysis of a user’s current emotional state.
This analysis powers our story/game creation engine. Using the context of the surroundings, our system creates a fantasy world and a minigame tailored to kids with autism—building instruction following, social learning, and fine motor skills. A custom story is weaved around minigame challenges which require the child to locate an object (instruction following), express a certain emotion (social learning), and mimic an animal (fine motor).
How we built it
For SoulReadAI, we use LLaMA-4 Vision, accelerated by Groq, to run a comprehensive deep analysis of a child's facial expression and posture. Our system is prompt-engineered based on established autism intervention frameworks, including ABA, VB-MAPP, ABLLS-R, and RUBI-PT. The analysis targets key developmental goals such as listener responding (tacts, object/color identification), motor imitation, and emotional expression, while reinforcing engagement through game-based interactions and positive reinforcement strategies.
Based on the detected emotion and the objects in the scene, the model generates a personalized, multi-step interactive story using LLaMA-4. For example, if a user appears nervous, the story gently encourages bravery through playful tasks. The emotional nuance in each story is only possible because of SoulReadAI. Each narrative includes three real-world tasks involving physical interaction with nearby objects (ex. “Grab the snack to feed the dinosaur”).
To verify task completion, we generate a text-based visual criterion for each step. (ex. “The snack is being held in front of the camera”). These are passed back into the LLaMA vision model along with the live camera frame to determine if the task has been completed.
Challenges we ran into
Perfecting the prompt engineering for our tasks was unexpectedly difficult. We needed the language model to generate instructions that were not only thematically relevant to the story, but also simple and concrete enough for a child to understand and complete. Getting that balance required multiple rounds of iteration.
Facial emotion recognition posed another challenge. While using Groq accelerated inference overall, the actual frame-by-frame analysis could still feel laggy in a real-time interaction setting — especially when paired with LLM-generated text responses.
We also ran into issues with object recognition. The model often responded better to specific prompts (e.g., "red ball" instead of "something red"), so we adjusted our task templates to encourage more accurate computer vision matches.
Finally, coordinating multiple concurrent API calls (CV, LLM, voice output) led to slowdowns and race conditions. We resolved this by implementing a lock mechanism to ensure smoother sequential execution without sacrificing interactivity.
Accomplishments that we're proud of
We’re proud of how well SoulReadAI performed in reading emotional nuance. During live testing, it accurately detected subtle expressions like nervousness or joy — creating a truly personalized interaction.
We’re also proud of our story generation engine, which blends emotional input and visual scene data to craft minigames that feel both magical and clinically meaningful. Building a system that merges fantasy and developmental therapy in real time is something we hadn’t seen done before.
What we learned
We learned how to work with multi-modal inputs by integrating visual data (facial expressions, posture) with large language models to generate meaningful behavioral insights. We also gained experience in prompt-engineering LLMs for sensitive, research-aligned outputs, and optimizing inference with high-speed systems like Groq.
What's next for BubbyBear
We plan to expand BubbyBear into a family of emotion-aware companions, each with distinct personalities and therapeutic goals. For instance, a “Timid Tiger” might focus on anxiety and social confidence, while “Brave Bunny” could encourage physical play and risk-taking.
We’re also exploring ways to integrate agentic AI, allowing each plush to evolve over time — remembering prior interactions, adapting lesson plans, and forming emotional continuity. Ultimately, we aim to pilot BubbyBear with clinicians and families, turning playful, emotionally responsive interactions into real developmental progress.


Log in or sign up for Devpost to join the conversation.