Inspiration
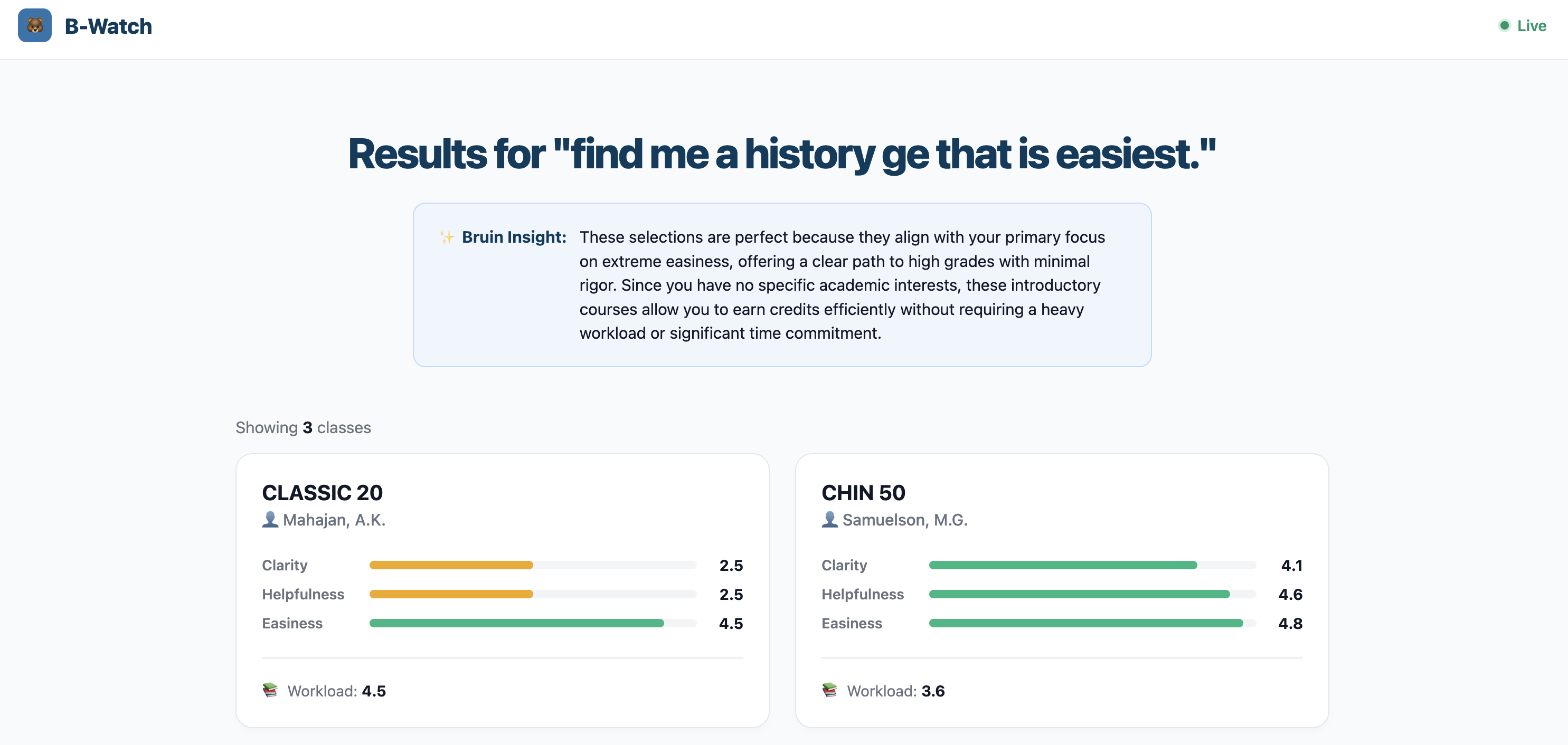
Some of us had to settle for GE classes that we're not interested in for our second pass. We spend literal hours on DAR looking through all classes offered, meticlously searching each vauge name up one by one and then checking if the professor is survivable.
How we built it
Bruin Watch is built on Python's flask backend, with HTML and CSS front end. We use beautifulsoup for webscraping on both the UCLA register and bruinwalk. We then store this information on our MongoDB server. Since the course register updates every hour, we make the scraping code run hourly as well, allowing for real time updates.
Challenges we ran into
Besides the usual challenges with database pulling and adding, a foolish challenge we ran into was that we were using the UCLA_WEB to host a webpage which the firewall was blocking. We spent a lot of time uselessly troubleshooting webpage issues when in reality it was working fine.
Accomplishments that we're proud of
We are extreamly proud of our web scrapers. UCLA has a lot of bot and webscraping protection, we had to utilize Selenium and other trickery to bypass these checks and get the required information.
What we learned
We are looking at increasing our AI model’s accuracy and overcome challenges such as null reviews or ratings for Professors on Bruinwalk, leading to no data being scraped for a certain class, that might actually be easy and exist. We plan to do so using surveys that are administered to students and this would greatly increase our probability of finding the perfect class for our students.
What's next for Bruin Watch
We hope to expand the capabilities of Bruin Watch to include an emailer that notifies users when spots open in "watchlisted" classes.


Log in or sign up for Devpost to join the conversation.