-
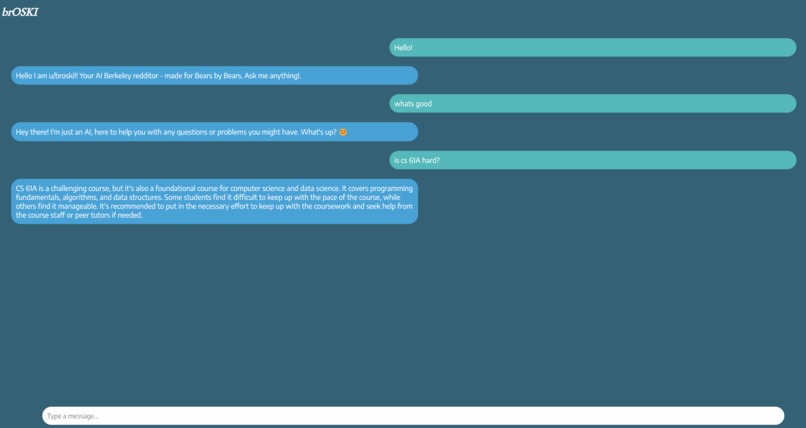
Our chatbot in action!

Inspiration
In the midst of Cal Enrollment and Berkeley college life in general, getting advice on what classes we should take, what spots in Berkeley to explore and what cafe's are the best, are sometimes hard information to come by. Thankfully, the Berkeley Subreddit has tons of Berkeley students just like us, who have their own unique ideas and opinions. The best way to represent all of this information is through language models! This is why we created brOSKI, a chat bot who can be your friend and advisor about all things Berkeley.
How We Built it
- Scrape Reddit.
With recent updates Reddit's API no longer permits data scraping, so collecting data from reddit on the scale needed required a unique approach. There is only one comprehensive archive of Reddit's database, "Pushshift." The problem is the archive has been removed from the public by Reddit, so to get the data from Pushshift we had to find an old copy of the database and download it in fragments. Bear in mind, the Pushshift Reddit database contains a recorded history of all of reddit, not just the Berkeley subreddit, meaning we had to grapple with over 20 terabytes of text data, to get the data we needed from the Berkeley subreddit. The smallest fragments the database can be downloaded in is 450GBs. By selectively only downloading posts, not comments we trimmed down the downloaded fragment size to 150GBs. We then filtered the downloaded posts to contain only r/Berkeley posts. Now we also needed the comments for each post, so we queried the API by post ID to collect the comments for the r/Berkeley posts we downloaded. Repeated a few times we managed to download months worth of r/Berkeley data (posts and comments) for usage by our LLM algorithms.
- Finetune LLM
The next step in the process, is to take the scraped and formatted data fine-tune our model of choice. For this project, we decided to use LLaMA 2 13b. We first tested smaller data samples, using both a small amount of epochs and high amount to see the difference in model "sound". We noticed that the model when overfit to the small dataset, became biased and uncensored, answering questions it probably shouldn't. Once we had all our data scraped and formatted correctly, we passed the 3500 lines of Q&A style training data, and chose 2, 4, 6, 8, and 10 epochs. We discovered that mid to low epoch range seems to give the best results for our use case.
- Front End
Initially, we planned to have an opening web page - quite similar to Chat GPT and bing AI with some example inputs along with few animations to make it seem more like iMessages or Instagram Direct Messages. However, due to time constraints, we are leaving that as future work. We designed our front end on Figma and primarily used HTML and CSS for our front end to put things in motion. At the end, we developed an API to connect our back end to the front end.



Log in or sign up for Devpost to join the conversation.