-
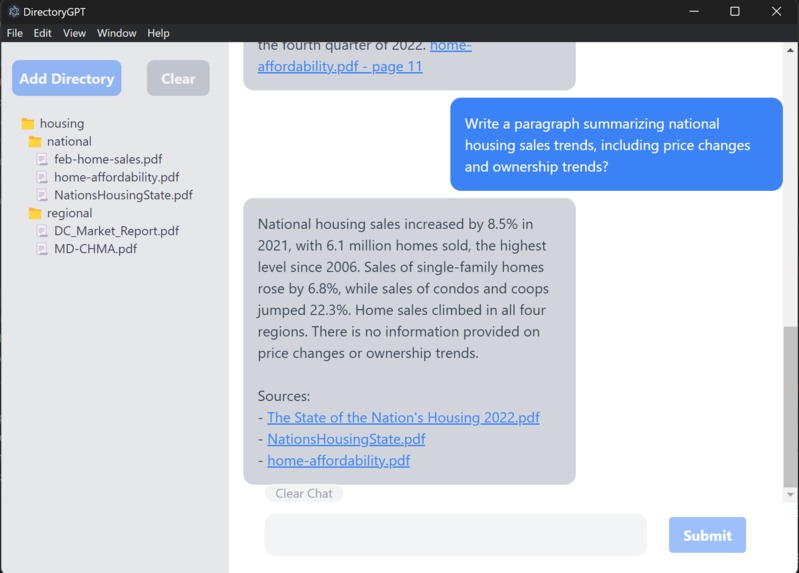
Brisbane summarizing national housing trends and other real estate information from an array of disorganized pdfs in a folder.
-
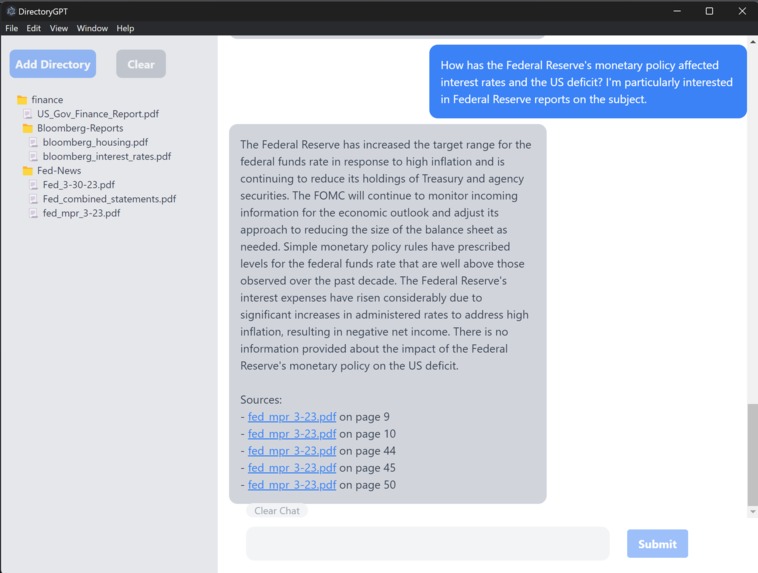
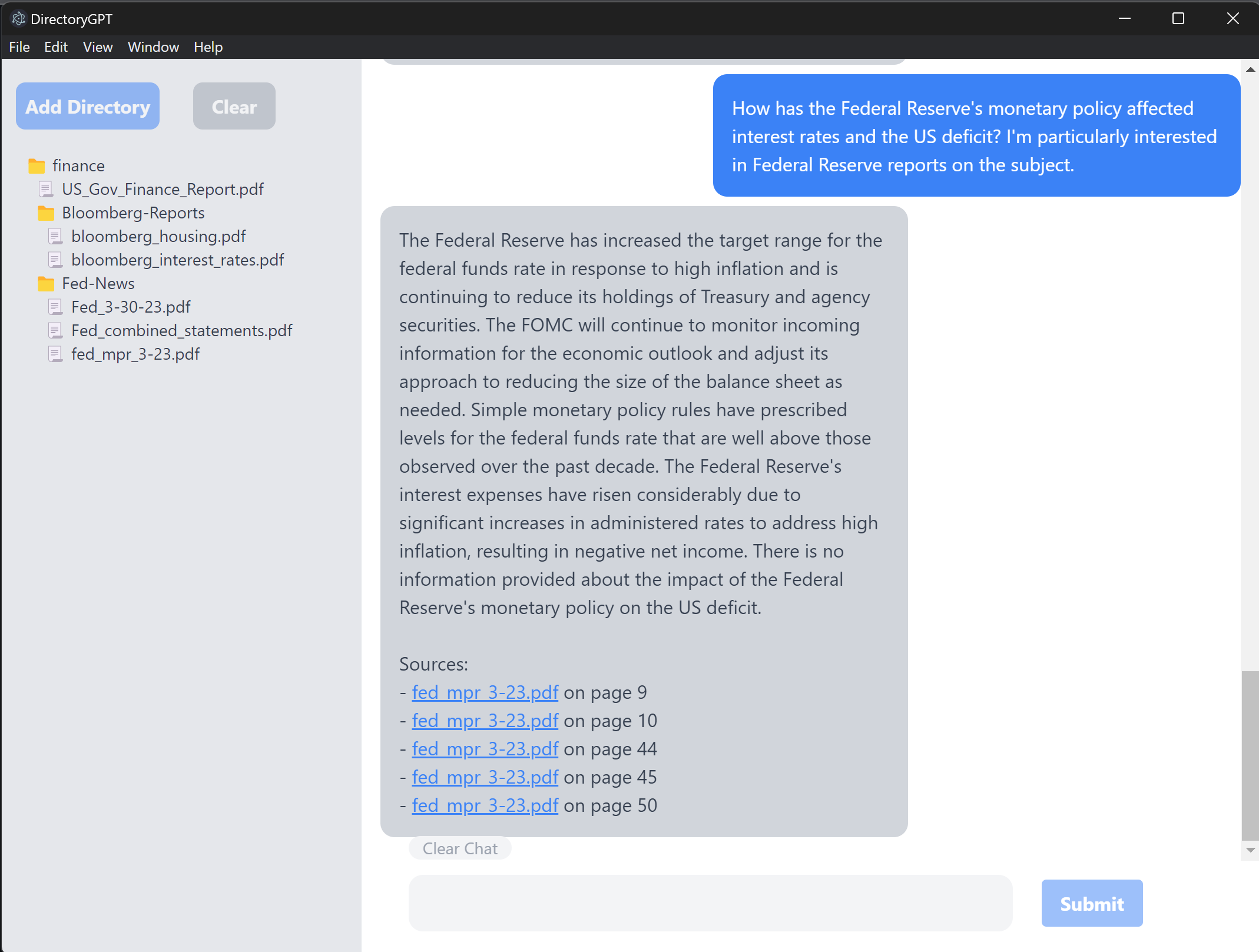
Brisbane inferring on the Federal Reserve's effects on the US interest rates and deficits using reports.
-
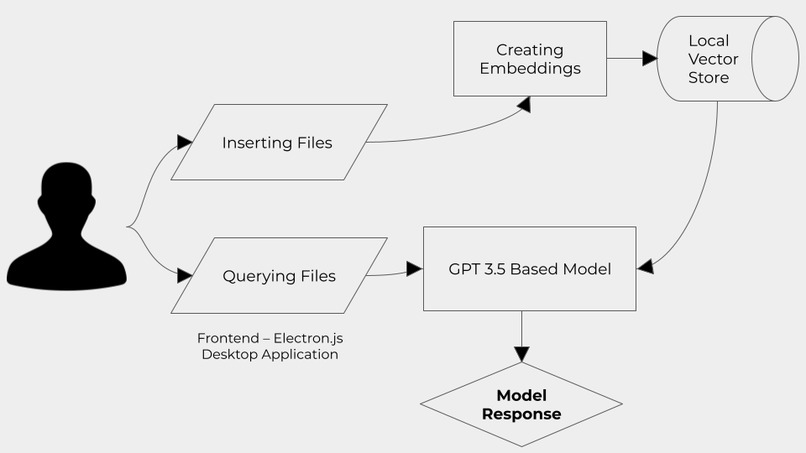
Inspiration
Currently, LLMs like ChatGPT seem to answer almost anything with great accuracy. However, what if you were working on a large project, and wanted help with something? What if you wanted to better understand a large amount of financial data in a more structured way? Thus, we were inspired to create a more smart way to harness the full power of LLMs for more specialized tasks
What it does
Brisbane is a desktop application that allows users to upload a variety of things, including text files, Word documents, PowerPoint slides, PDFs, and code repositories of any programming language. After uploading repositories, users can chat with our improved AI and learn things about their files. For example, one could ask about a certain method that is written in a large code base. Or patterns in a large amount of Form 10-K financial data. After a query, the AI will not only answer but give sources that users can click on to instantly access.
How we built it
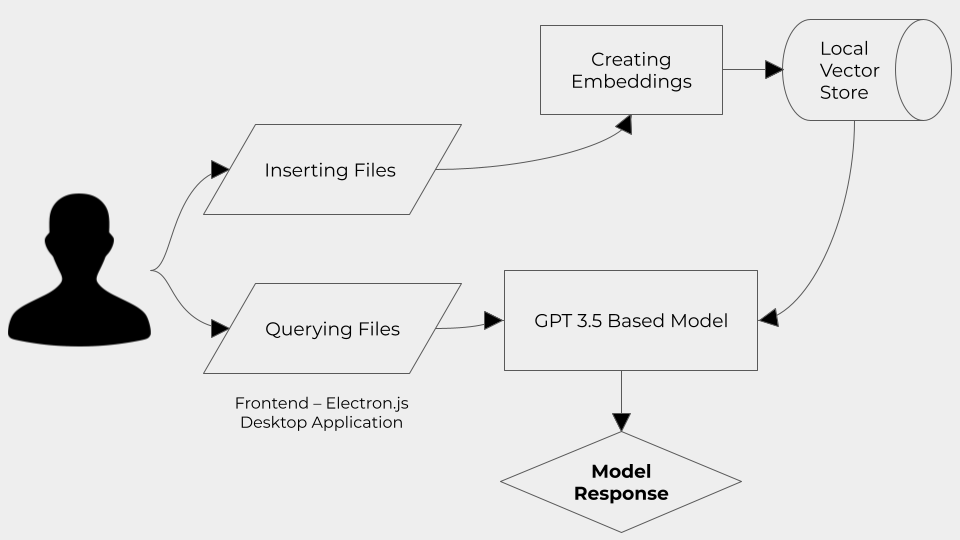
We first vector embeddings of entire directories, which are stored in a database. These embeddings can be fed to LLMs, such as OpenAI's GPT-3.5, to teach them to better understand information from these files. Smart use of prompt engineering also allowed us to teach GPT to keep track of what file and even page it was extracting information from when answering. This solves another huge problem of current GPT interfaces: it can be hard to validate and contextualize the answers it gives.
We built the front end for our desktop application using Electron. We created a Rest API in Python using Flask and used it to serve outputs from our language processing modules. The use of these technologies allows us to easily incorporate sharing and user collaboration in the future.
Challenges we ran into
As a group of first and second-year students, this was our first time working with each other on a project from start to end. None of us had significant experience building desktop applications or designing effective user interfaces. This project involved a lot of hours googling to learn more about vector embeddings, implementing APIs, frontend development, and more. Though it was tough, we found satisfaction in tackling small goals and eventually ended up with an application we are all proud of and plan to continue to use and develop more even after Bitcamp.
Accomplishments that we're proud of
We were able to create embeddings for a variety of different file types and platforms, more than we initially thought during the planning stage. In addition, the use of prompt engineering to better teach the model allowed us to shape its output and utility even more.
What we learned
We have collectively learned a lot through this hackathon. By attending workshops, we learned a lot about research opportunities, machine learning, and more. Through intensive googling, we have learned a lot about front-end development, natural language processing, and desktop application development. Above all, we learned that AI is incredibly capable, and it is possible to shape it for a plethora of applications.
What's next for Brisbane: Discover Your Data
We want to distribute this technology as a desktop app to allow others to use it. Also, we hope to implement collaboration and integration with Google Drive or OneDrive. This will allow Brisbane to be used by small organizations and companies to keep track of their file systems.
Applications
Advanced file search with citations has several notable applications:
Finance
Lots of financial applications require implicit or conventional knowledge - Brisbane can access large amounts of conventional or market knowledge and cross-apply them to help users figure out what new social, political, and financial events have happened, or how those events might affect markets. Also, since finance applications require transparency, Brisbane’s ability to cite where it got its knowledge will increase the number of ways in which it can be used.
Real Estate
Brisbane can analyze housing markets or even particular properties to find useful trends in housing and real estate for individual buyers. Giving Brisbane access to public national data reports lets it provide even more informed advice to users, and turns it into an industry tool to produce housing/real estate market data.
Code Bases
Code Navigation: Brisbane can help developers navigate complex codebases by providing semantic search capabilities, making it easier to locate specific functions, classes, or variables. It could be a fantastic pair programmer, with deep useful knowledge of how the codebase is structured.
Built With
- chatgpt
- electron
- flask
- gpt
- javascript
- openai
- python








Log in or sign up for Devpost to join the conversation.