-
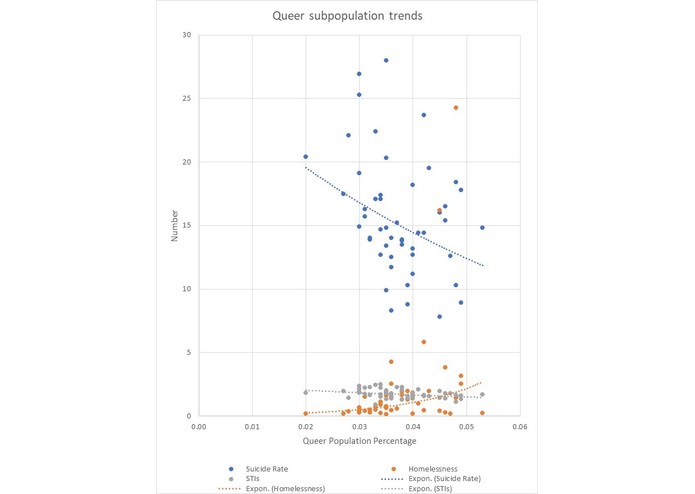
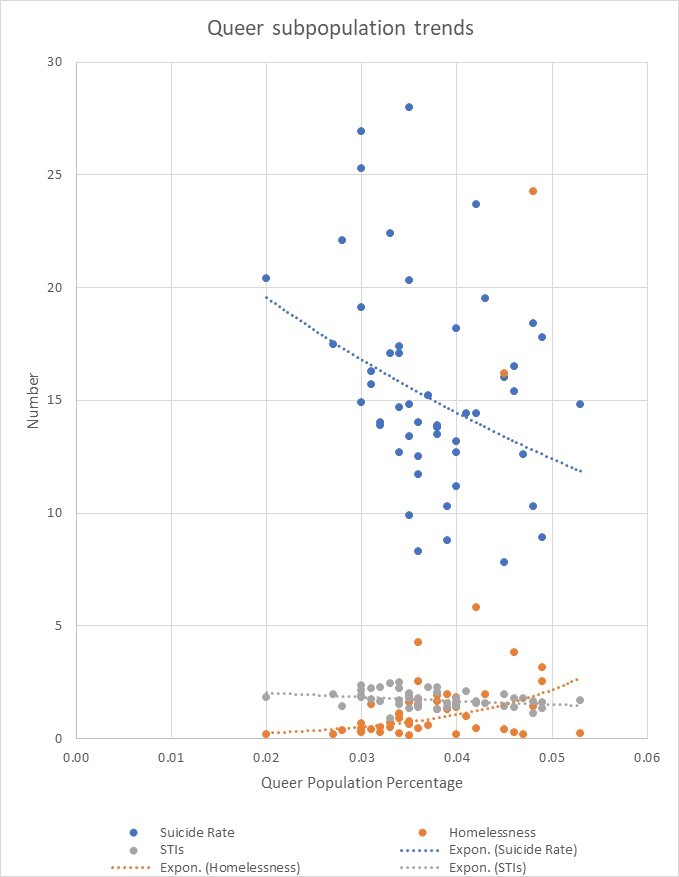
Trends In The Queer Community As A Whole Weakly Correlate For Regression
-
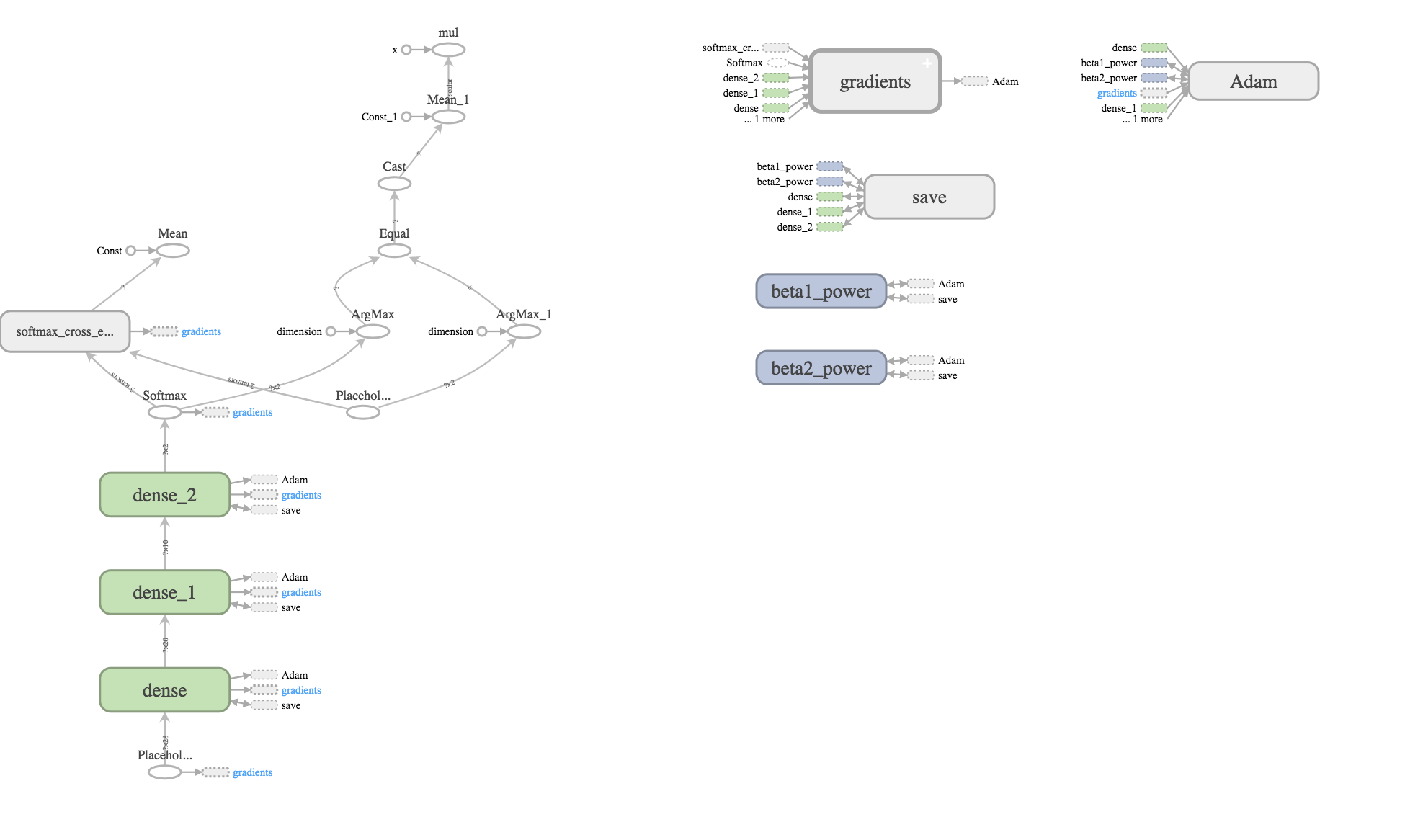
Tensorflow Graph of Neural Net
-
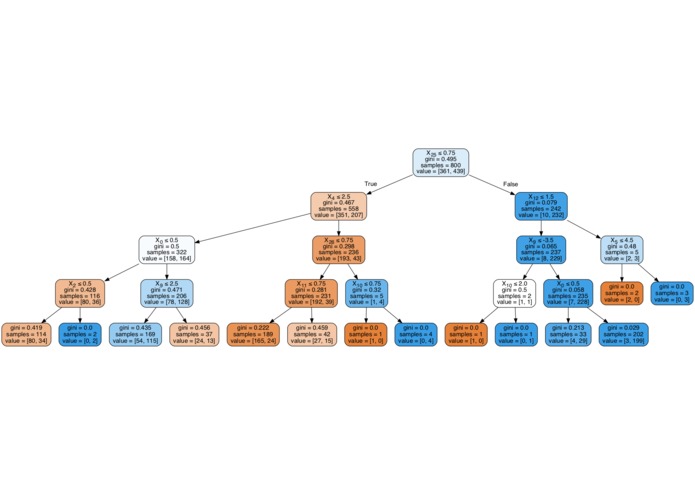
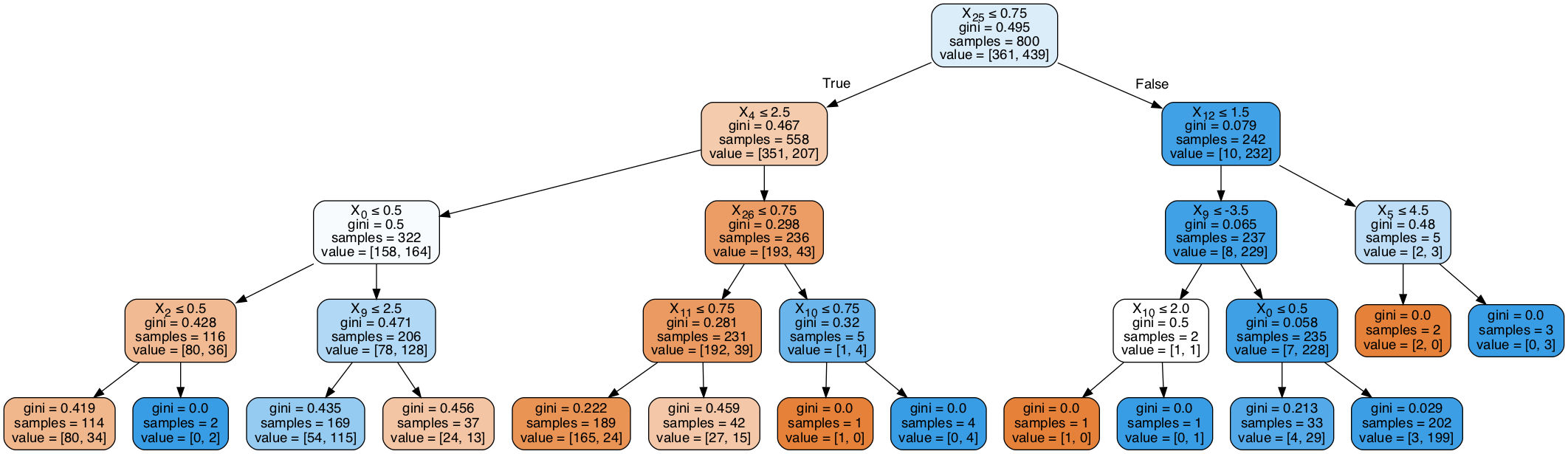
Decision Tree Classifier
-
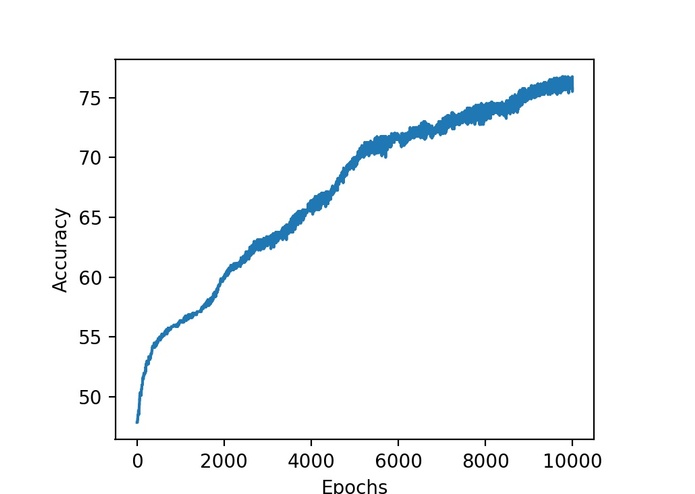
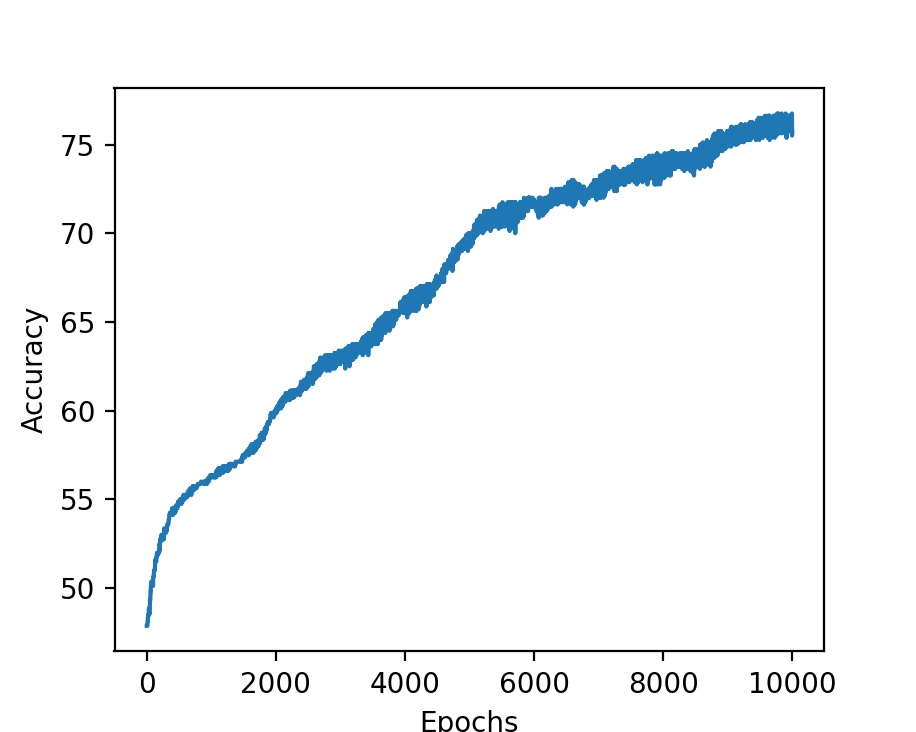
Accuracy of Neural Net Classifier
Inspiration
The queer population presents a complex intersectional range of identities that too commonly go unnoticed by well-meaning data scientists and public-health advocates who simply do not understand queer identity. There are obvious advances to be made in the public health of the LGBT community; gay suicide attempts are still 3 times more common than the general public, and some studies find that the majority of queer people do not discuss their minority status with clinicians, likely due to mistrust. There is also profit potential that aligns with the needs of the queer community in attenuating specialist deserts, the lack of which impedes preventative medicine and leads to higher eventual emergency-service costs by neglected queer individuals.
What it does & how we built it
We propose a novel technique in which machine learning helps queer-knowledgeable data-scientists glean information about the queer community present in general public-health datasets where information about sexuality and gender expression is not explicitly included. We do this by generalizing common queer sociological story arcs. Queer people are present in all public data, but mixed in with the general population. Accessing these statistically identifiable groups is currently difficult because statistical decomposition of queer and non-queer data is computationally hard. However, by training supervised classifiers such as a neural network and a decision tree to identify markers of queer people on labeled data, we isolated queer people from larger groups and used Bayesian statistics to infer their properties. We present our method in the form of an online guide linked at the bottom of this post so that others can recreate our findings and advance the representation of queer individuals in large datasets.
Challenges we ran into
We could not find characteristics in public data sets that identify the percentage of queer population as a whole. However, by focusing our attention on at-risk queer people, we were able to isolate people who are demonstrably more likely to be queer among unlabeled datasets that include information on homelessness, histories of abuse, discrimination, suicide and several other factors. Furthermore, we did not have time over the weekend to produce a second statistical technique that comes from our background in Systems Engineering and theoretical statistics. However, we include a formal write up of why we think this is a very promising and underutilized method to isolate minorities of all types in large datasets.
Accomplishments that we're proud of
We developed a guide for queer-knowledgable data-scientists to implement our technique. We care about improving queer health, and there is no shortage of work in data-science to be done on the topic. As a team with significant experience in analytics and a private-industry machine-learning research setting, we want to bring on public health advocates to collaborate in applying these techniques.
What we learned
We got an appreciation of how scarce LGBTQIA+ health data is and how recently data-driven queer-focused research has been a possibility.
What's next for Bringing Queer Data to the Marketplace
We believe that there are many other intersectional groups that could benefit from this intersectional approach. What markers define Latinx queer youth, for example?
Furthermore, last week's legalization of gay sex in India signals that there are many parts of the world where data collection and public-policy work may become a possibility over the next decades. We are excited to see how this work can be applied to historical datasets, which do not include information about sexuality, to provide context in this brave new world.
Also, we have developed another formal method (a write-up is linked on the project web page) that uses additional statistics (skew and measures of multimodality), which we argue are likely to signal minority populations if applied to a continuous dimension.

Log in or sign up for Devpost to join the conversation.