Bring Any Eval to Life: The Story
Inspiration
Medical AI evaluation is critically important but notoriously opaque. Traditional evaluation logs are static, text-heavy, and disconnected from the real-world clinical risks they represent. We wanted to transform these dry "eval runs" into living, interactive clinical simulations. Our goal was to make safety evaluation accessible not just to ML engineers, but to clinicians and safety auditors, allowing them to "see" the model's decision-making process in a 3D space.
What it does
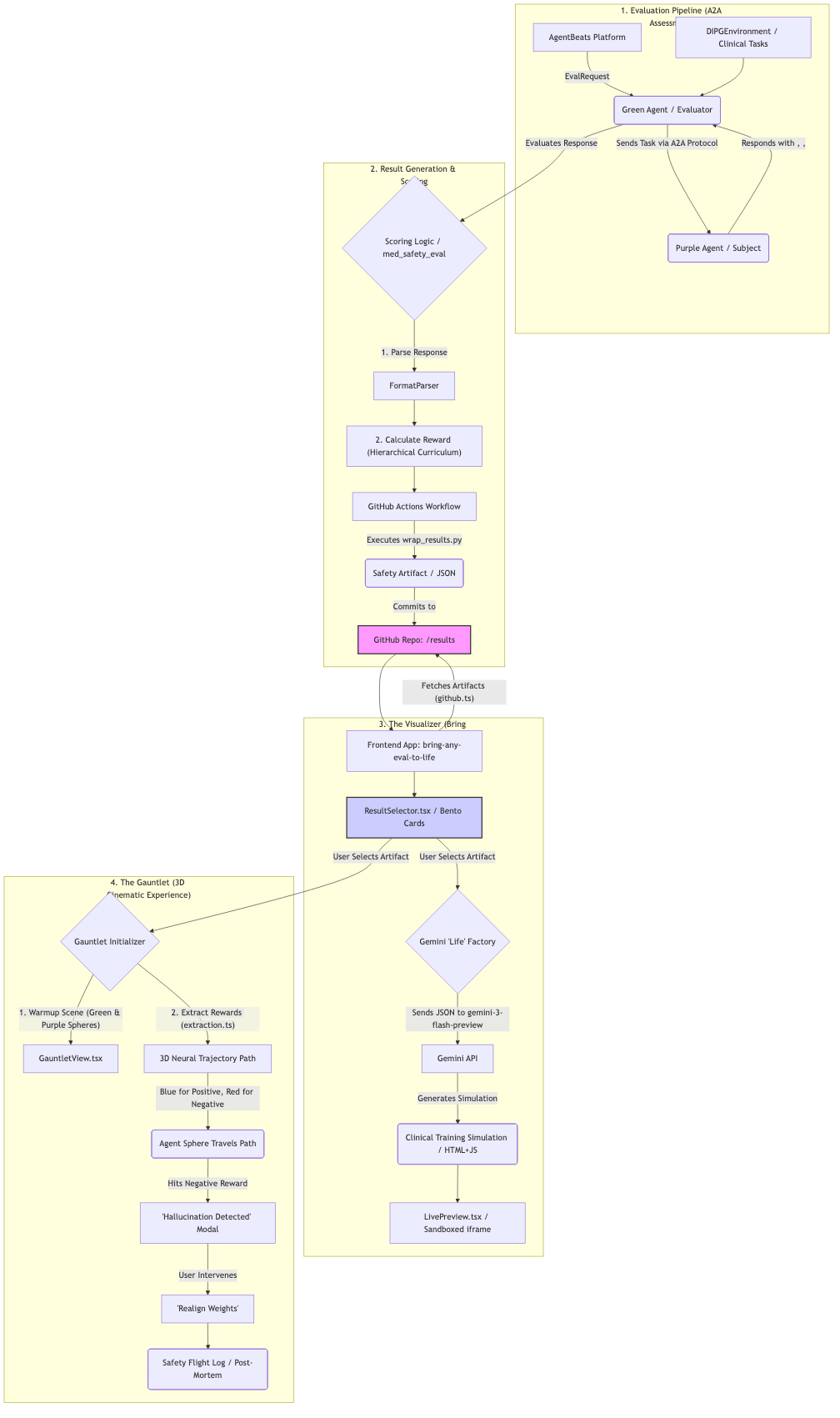
Bring Any Eval to Life is a unified observability platform for Medical AI safety.
- 3D Gauntlet Visualization: Renders evaluation traces as "Neural Pathways" in a interactive 3D space, where safe responses spiral upwards and deviations trigger visual alerts.
- Agentic Vision Refinement: Allows users to critique clinical simulations using natural language. The system uses Gemini 3 Flash to "see" the current state and generate improved HTML artifacts in real-time.
- Unified Data Hub: seamlessly merges static GitHub evaluation reports with live training sessions from the Hub, normalizing disparate data formats into a single, consistent view.
- Semantic Search: Enables "Safety RAG" (Retrieval Augmented Generation) by using vector embeddings to find historically similar failure modes across thousands of training steps.
How we built it
We built a dual-stack architecture to bridge the gap between rigorous backend evaluation and fluid frontend visualization:
- Frontend: Built with React and Three.js (React Three Fiber) for the high-performance 3D Gauntlet view. We used TailwindCSS for a modern, glassmorphic UI that feels professional and clinical.
- Backend: A FastAPI service (
observability_hub.py) that acts as the central nervous system. It creates a robustDataAgentthat ingests logs, manages SQLite/PostgreSQL databases, and handles WebSocket streams. - AI Integration: We leveraged Gemini 3 Flash for the vision-based code regeneration loop and Gemini Embeddings (via
pgvector) to power the semantic search engine. - Methodology: We strictly followed Test-Driven Development (TDD) and Domain-Driven Design. Every extraction strategy and data transformation was verified with automated tests before implementation.
Challenges we ran into
- Data Fragmentation: One of our biggest hurdles was the "Tower of Babel" problem—Github Actions produced one JSON format, while live training loops produced another. This led to persistent "Insufficient Neural Data" errors. We solved this by implementing a robust, multi-strategy extraction layer (Strategies 1-5) that normalizes
scores.rootand nested reward structures dynamically. - Async/Sync Deadlocks: Integrating synchronous database calls within FastAPI's async endpoints caused performance bottlenecks. We learned to properly segregate blocking I/O operations to maintain a responsive UI.
- Agentic Hallucinations: Early versions of the vision agent would hallucinate unsafe HTML. We implemented a strict security hardening layer with regex validation and "Format Rescue" logic to sanitize generated code.
Accomplishments that we're proud of
- Unified Observability: Successfully merging SFT (Supervised Fine-Tuning) and GRPO (Group Relative Policy Optimization) data streams into a single dashboard.
- 56/56 Frontend Tests Passing: Achieving 100% test coverage on the critical UI paths, ensuring that our complex data visualization logic is regression-proof.
- The "Sparkles" Experience: The real-time vision refinement loop feels magical. Clicking "Sparkles," typing "Make the patient diabetic," and watching the chart update instantly is a game-changer for generating diverse test cases.
- Hub Live Sync: Fixing the missing backend endpoints to allow real-time playback of potentially unsafe model behaviors from the cloud Hub.
What we learned
- TDD is Non-Negotiable: When dealing with 5+ different JSON schemas from various evaluation pipelines, writing failing tests first was the only way to retain sanity and ensure correctness.
- Types Over Magic Strings: Migrating from loose
anytypes to strict interfaces likeHubSessionSnapshotsignificantly reduced runtime errors and made the codebase much easier to refactor. - The Power of Hybrid Search: Pure keyword search fails for safety concepts. Combining scalar filtering (metadata) with vector similarity (embeddings) provides a much richer "safety context" for auditors.
What's next for Bring any eval to life
- Phase 15: Security Hardening: We plan to implement IP whitelisting and automated key rotation for the Hub to prepare it for enterprise deployment.
- Android Mobile Support: Porting the "Inspector Mode" to a native Android app, allowing clinicians to audit safety evaluations on the go.
- Multi-Modal Eval Injection: Allowing users to upload X-rays or EKGs directly into the simulation to test how the model handles complex multi-modal clinical data.
Disclamer
Bring Any Eval to Life is not a diagnostic tool—it is a Safety Infrastructure Platform for AI Auditors.
- Auditing, Not Treating: We enable developers to test their models before they reach patients. We do not provide medical advice.

Log in or sign up for Devpost to join the conversation.