-
-
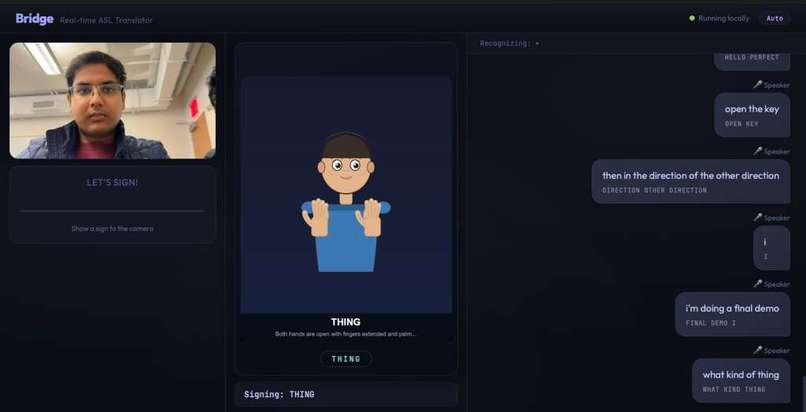
main website
-

avatar in google meet (bit creepy sorry)
-
model and json that took way too long to make
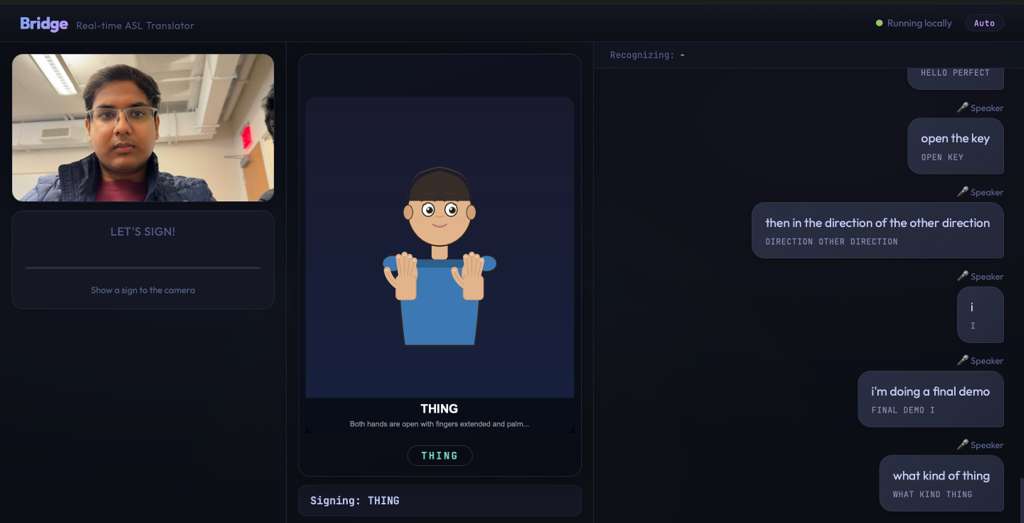

Inspiration
33 babies are born with permanent hearing loss every day in the US. The majority of deaf children are born to hearing parents who don't know sign language. These families spend the most important years of a child's life struggling to communicate with each other.
We asked a simple question: why does real-time translation exist for 100+ spoken languages but not for sign language?
Bridge exists so a deaf person can sign and be understood by anyone, and so anyone can speak and be understood by a deaf person. No interpreter needed. No special training required.
What it does
Bridge translates in both directions, in real time:
ASL → English speech: A deaf person signs into a camera. Bridge recognizes their signs (100 word-level signs via an I3D neural network trained on the WLASL dataset, plus full A-Z fingerspelling). The recognized signs get assembled into a sentence and converted from ASL grammar into natural English using an LLM through the Lava API — because ASL has its own grammar where "STORE I GO TOMORROW" means "I'm going to the store tomorrow." Then ElevenLabs speaks the English sentence aloud.
English speech → ASL: A hearing person speaks. Whisper transcribes their words. The English gets converted into ASL gloss order via the Lava API. An animated avatar built from chained SVG animations performs the signs on screen for the deaf user.
Bridge also includes a Google Meet agent that can join video calls, working toward a future where every meeting is accessible without a human interpreter.
How we built it
Five layers, all integrated into one real-time pipeline:
Sign recognition — MediaPipe extracts 21 hand landmarks at 30fps. A rule-based geometric classifier handles fingerspelling (A-Z) using finger extension ratios, thumb position, and spread patterns. An I3D model trained on WLASL handles word-level signs from 16-frame video sequences. A state machine routes between the two.
Grammar translation — ASL grammar is not English grammar. We use the Lava API gateway to convert between the two in both directions, preserving the signer's meaning rather than producing awkward word-for-word output.
Speech synthesis — ElevenLabs (eleven_flash_v2_5, voice: Sarah) speaks the translated English sentences. Pyttsx3 fallback for offline use.
Speech recognition — Whisper runs via faster-whisper with energy-based phrase detection in a background thread.
ASL avatar — We built an SVG animation system from scratch, chaining hand position keyframes and orientation transforms to render ~100 signs. Each sign is composed of individual animation sequences with timed transitions.
Challenges we ran into
Word-level sign recognition was brutally hard. The standard pretrained weights (WLASL I3D) are hosted on Google Drive and were rate-limited for the entire hackathon. We spent hours trying gdown, browser workarounds, alternative mirrors, a pretrained TFLite model from Kaggle (wrong input format), and nearly pivoted to training from scratch before finally downloading the weights through a direct browser session.
The ASL avatar had no off-the-shelf solution. No library exists for rendering sign language animations. We had to design an entire pipeline for chaining SVG keyframes into fluid sequences, handling between-sign transitions, and making 100 individual sign animations by hand.
ASL grammar conversion was a problem we didn't anticipate. Without it, the output sounds like broken English, which actually undermines the dignity of the person signing. Getting the LLM to reliably convert between ASL topic-comment structure and English syntax required careful prompt engineering.
Accomplishments we're proud of
This was our first hackathon. Ever.
We built a complete bidirectional translation system with five ML/AI components running simultaneously: MediaPipe, I3D, Whisper, LLM translation, and ElevenLabs.
Most ASL recognition projects only go one direction. Bridge goes both ways, which is the minimum viable requirement for an actual conversation.
The grammar translation layer is something we haven't seen in any other ASL project. It's the difference between "FOOD WANT I" appearing on screen and a voice naturally saying "I want food."
What we learned
Sign language is not English with hands. It has its own syntax, its own grammar, its own culture. Respecting that distinction shaped every design decision we made.
Real-time ML is a fundamentally different problem than batch inference. When you're trying to make a conversation feel natural, every millisecond of latency breaks the illusion.
Pretrained models are only useful if you can actually download them. We learned more about debugging Google Drive rate limits than we ever wanted to.
What's next for Bridge
We have pretrained weights for 1,000 and 2,000 sign vocabularies ready to plug in. Motion capture data from native signers would dramatically improve the avatar. Full Google Meet integration where Bridge actively translates during live calls. A mobile version. And a learning mode where hearing parents can practice signing with real-time feedback.
The long-term goal: Bridge should make itself obsolete. If it helps enough families learn sign language, they won't need a translator anymore. That's the win.

Log in or sign up for Devpost to join the conversation.