-
-
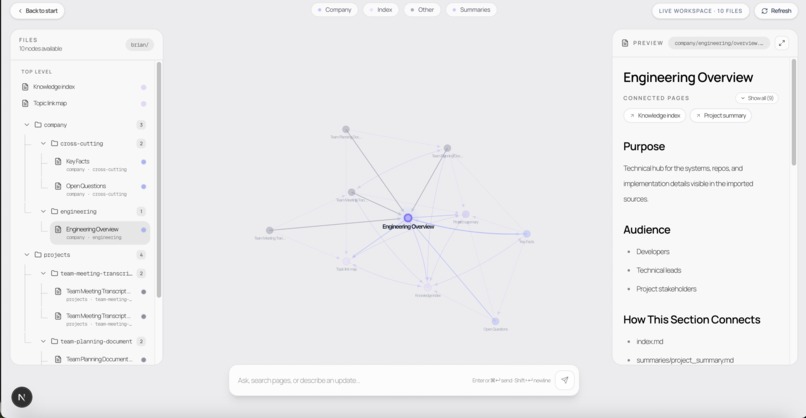
Brian Brain Map
-
Brian Landing Page
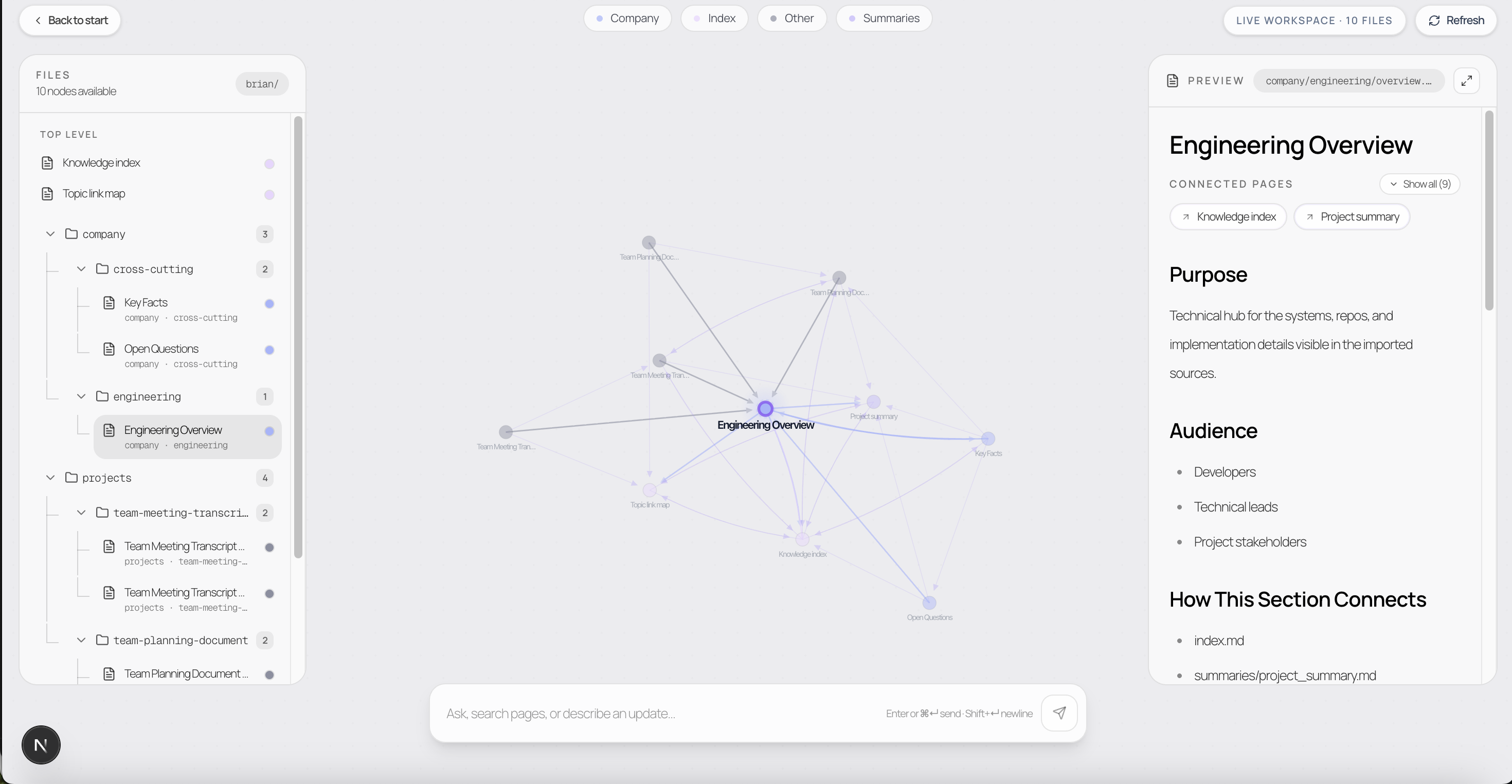

Inspiration
We were inspired by Cognition's talk on the current pitfalls of agentic AI. The takeaway that stuck with us: powerful agents still break down when they don't share the same context as the humans guiding them. We got hooked on the human-in-the-loop problem — even an AI that can read code and documents still needs a structured, editable "brain" that humans can inspect, correct, and steer. So we built Brian, a system that aims to give humans and AI agents a mutual understanding of context, at enterprise scale.
What it does
Brian takes your company's real context — GitHub repositories, Slack conversations, meeting notes, and uploaded documents — and turns it into a shared knowledge brain that both humans and AI agents can read from and write to. Incoming context is normalized, embedded for semantic search, and stored as a structured Markdown knowledge base that acts as the agent's long-term memory of the organization.
We visualize that knowledge as a graph of connected nodes so humans can see how the system is organizing context. The platform includes a workspace for browsing the brain, semantic search, and an agent interface for reading from and updating the knowledge base. Most importantly, we expose the brain through an MCP server so tools like Windsurf and Cursor can query prior knowledge, code with active contextual understanding, and write back new learnings and updates to the brain, closing the loop between coding agents and organizational memory.
How we built it
We built Brian as a full-stack system with two major layers.
On the product side, we used Next.js, React, and TypeScript for the UI: dashboard, semantic search, brain viewer, and graph visualization. We used Postgres + pgvector for storage and HNSW indexing for fast vector lookup. We also built normalized webhook ingestion endpoints for GitHub, Slack, GitLab, Discord, and meeting transcripts.
For the memory and agent side, we built a Python service using FastAPI, LangGraph, and an MCP (FastMCP) server. The brain is operated by a two-node React graph: a Reader agent that retrieves grounded context and a Writer agent that modifies the working brain, both streamed live to the UI over Server-Sent Events.
Retrieval runs as a two-stage pipeline. Stage 1 is dense semantic recall using BAAI/bge-small-en-v1.5, which encodes the query $q$ and each chunk $d_i$ into L2-normalized vectors in $\mathbb{R}^{384}$. Because both vectors have unit length, cosine similarity reduces to a dot product:
$$
\text{sim}(q, d_i) = \frac{\mathbf{q} \cdot \mathbf{d}_i}{\lVert \mathbf{q} \rVert \, \lVert \mathbf{d}_i \rVert} = \mathbf{q}^\top \mathbf{d}_i
$$
When the dense encoder isn't available (offline demo, no model cache), we transparently fall back to BM25 keyword scoring so retrieval never fails. Stage 2 is a cross-encoder reranker that re-scores the top-$k$ candidates jointly with the query and blends in a source-authority weight: $$ \text{score}(d_i) = \alpha \cdot s^{\text{rerank}}_i + \beta \cdot s^{\text{dense}}_i + \gamma \cdot w^{\text{auth}}_i $$
This gave us a good tradeoff between speed and context retrieval quality.
Challenges we ran into
Funnily enough, our biggest challenge was mixing up files named "brian" and "brain". An initial slip-up we thought was funny turned out to be a nightmare to fix when our program would error out from a file path being named "brian/brain" instead of "brain/brian". This comedic recurrence would inspire our project name 'Brian'!
Another challenge was figuring out how much freedom to give the LLM when it builds the brain. At first, we let the model design everything itself including folder names, file names, how documents link to each other. The result was a brain that looks different every single run. The same fact would get filed in a different place/section every time, which made it almost impossible to have some sort of structure. Swinging the other way and hard-coding the structure was another problem, as the brain couldn't grow with new kinds of context. Our solution was a middle ground: we fix the top-level shape (folders like architecture/, decisions/, context/, goals/) and require a consistent metadata header on every file, but the model is free to choose whatever is inside each folder: section titles, filenames, how things link together. This solution gave us a brain that is predictable enough to search reliably while being flexible enough to absorb new topics.
Another challenge was efficiently traversing the brain during retrieval. The naive approach, compare every query against every section, gets slow fast once the knowledge base grows to the size of a real enterprise. Our fix was a two-step traversal: first, a cheap vector search over an HNSW index to grab a handful of candidate sections; second, a cross-encoder reranker that re-scores only those candidates against the query. We then expand outward to a candidate's linked neighbors only if its rerank score clears a threshold, so a typical query touches tens of nodes instead of thousands.
Accomplishments that we're proud of
We're proud that in a weekend we built a full end-to-end context pipeline with ingestion, embedding, structured storage, retrieval, and live agent execution, and exposed it through both a polished product UI and most importantly, an MCP server that plugs straight into coding tools like Windsurf and Cursor. The MCP integration is what we're proudest of: it means the brain we built won't just be a demo, but something a developer can actually use today.
What we learned
On the engineering side, we learned that efficiency and accuracy are often tradeoffs, but still can both be optimized by thinking outside of the box. It took us a while to realize that simply optimizing structuring of context files properly before retrieval helped to enhance performance more than any algorithm could.
Throughout testing, we also developed an understanding of graceful degredation. We learned that agent systems need useful fallback behavior when models, quota, or external services fail, otherwise one dependency outage takes down the entire system.
Most importantly, we learned that just like humans, failures are the most valuable learning signals for agents. If an agent can extract lessons from its failed attempts and persist them into memory, it stops repeating the same mistakes. That is when it really starts behaving like a system that actually learns.
What's next for Brian
Our demo for this hackathon focused on integrating the MCP into coding tools like Windsurf. Next, we want to take the same pipeline beyond engineering. The brain's structure isn't limited to software, so the same ingestion to embedding to MCP loop can capture finance, operations, customer context, etc. Our goal is to have every team in a company share one brain that humans and agents can both read from and contribute back to.
Built With
- bash
- css
- drizzle
- fastapi
- git
- github
- github-rest-api
- google-workspace
- hatchling
- langchain
- langgraph
- markdown
- mcp
- mermaid
- next.js
- node.js
- octokit
- openai-api
- openai-node-sdk
- postgresql
- pydantic
- python
- rank-bm25
- react
- rest
- sentence-transformers
- tailwind
- typescript
- uv
- uvicorn
- websocket


Log in or sign up for Devpost to join the conversation.