-
-
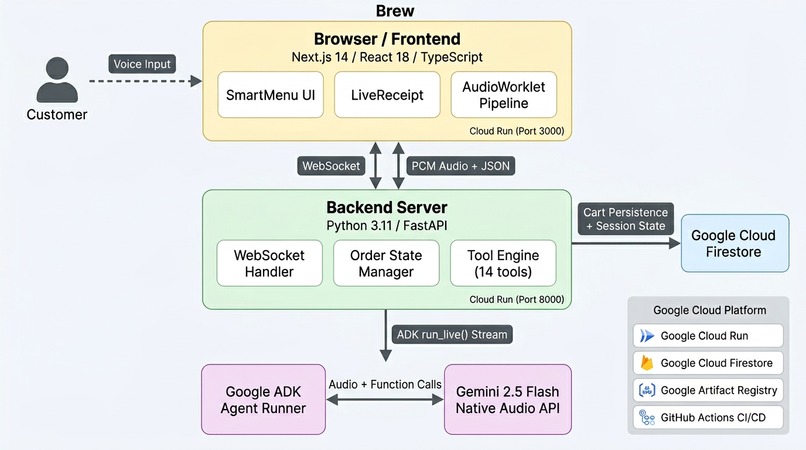
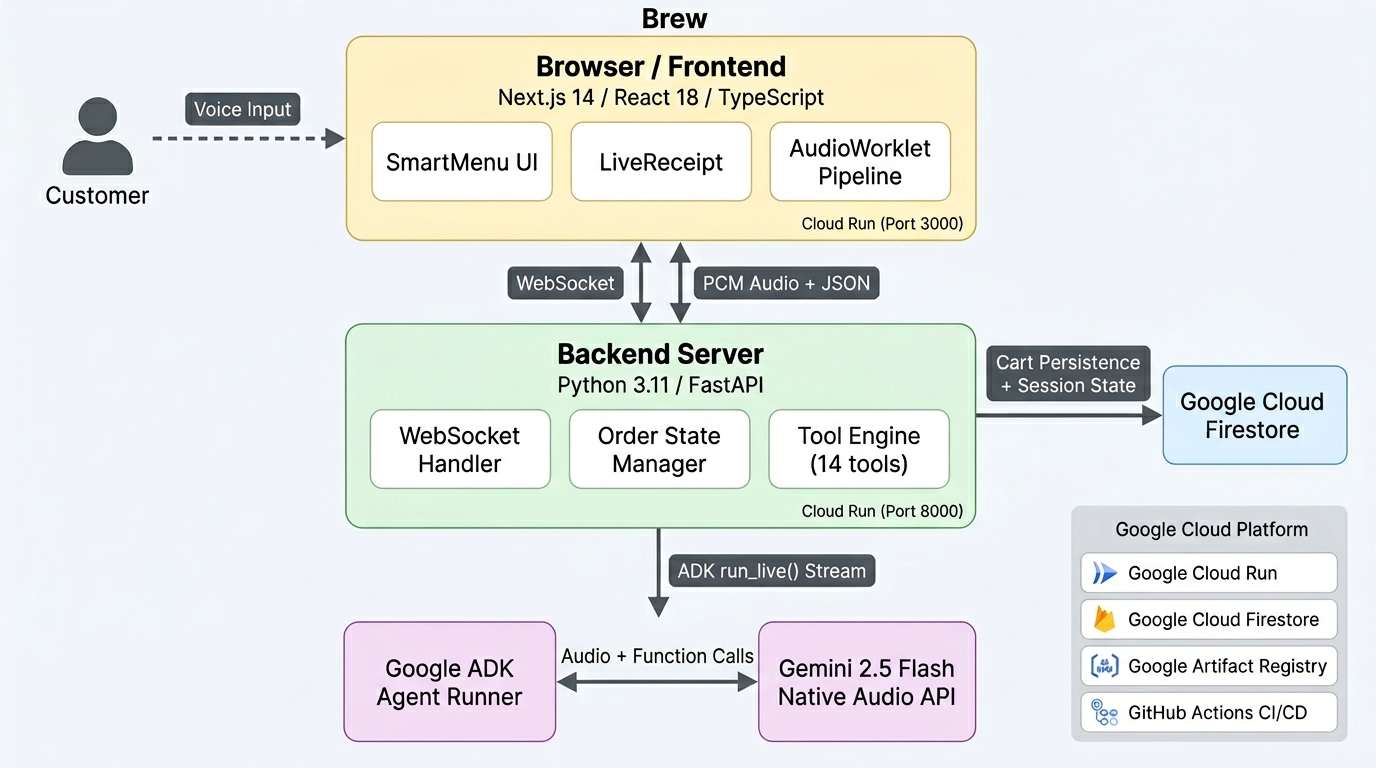
Architecture Diagram
Inspiration
Drive-thrus lose money every day to incorrect orders, staff shortages, and language barriers. I've always noticed that while the voice-first format is right, the execution is fundamentally broken—the industry error rate sits around 15%. During peak hours, mistakes pile up, lines slow down, and operational costs climb. You see places trying to fix this by having baristas walk between cars with tablets, but it doesn't scale. The more complex the order, the more likely something gets lost in translation.
Brew fixes this. It’s a real-time voice AI barista built for how drive-thrus should work. You pull up and speak naturally—change your mind mid-sentence, interrupt to correct yourself, or add items—and Brew updates the order live. It natively handles multiple languages, eliminates order errors, and runs without staffing constraints, cutting operational costs while keeping the line moving.
I chose a coffee shop deliberately because it's arguably the hardest ordering environment in food service. A single drink can have a size, a milk type, multiple syrups, and an ice level, creating thousands of valid combinations. If Brew can handle this extreme level of complexity—with interruptions, batch orders, and real-time modifier management—it can handle virtually any ordering scenario.
What it does
Brew is a real-time voice AI agent that takes coffee orders through natural conversation. A customer directly orders entirely by voice, talking to the AI barista just like a human—no buttons to push and no menus to navigate. The AI listens, processes the order, calls the appropriate tools, and responds with spoken audio, all while the order and receipt update in real time. Plus, it's natively multilingual, seamlessly switching languages on the fly to match whatever the customer is speaking.
It handles the things that make live voice ordering hard:
- Interruptions (barge-in): The customer can cut the AI off mid-sentence. It stops talking immediately and listens.
- Batch orders: "A grande iced latte, a cake pop, and a blueberry muffin" is processed in a single tool call with one natural confirmation.
- Mid-order corrections: "Actually, make that a venti" or "swap the milk to oat on both drinks" works without starting over.
- Complex modifiers: Syrups, milk swaps, toppings, ice levels, warming -- across 22 menu items with thousands of valid combinations.
- Context awareness: The AI remembers item IDs from earlier in the conversation, so "add oat milk to the first drink" just works.
- Undo and clear: "Go back" reverts the last change. "Cancel everything" clears the order.
The menu panel auto-switches categories based on what the customer orders (say "cake pop" and it flips to Desserts), and the receipt panel shows a running total with full modifier breakdowns -- all updating live as the conversation flows.
How I built it
The system has three layers:
Frontend: A Next.js 14 app captures microphone audio via the Web Audio API (AudioWorklet) and streams raw PCM at 16kHz to the backend over a WebSocket. It receives audio responses for playback and JSON state updates that drive the menu and receipt UI. Three components handle the experience: SmartMenu for the dynamic tabbed menu, LiveReceipt for the real-time order panel, and AudioVisualizer for visual feedback during the conversation.
Backend: A Python/FastAPI server on Google Cloud Run manages the WebSocket connection and orchestrates the agent lifecycle using Google's Agent Development Kit (ADK). The ADK Runner calls run_live() to establish a persistent bidirectional stream with the Gemini Live API. The agent has 14 tools for order management -- adding/removing items (single and batch), applying modifiers (single and batch), undo, clear, menu view switching, and order summaries. Cart state is synced to Google Cloud Firestore so orders survive instance restarts and horizontal scaling.
AI Model: Gemini 2.5 Flash with native audio (gemini-2.5-flash-native-audio-preview-12-2025) handles speech recognition, intent understanding, tool selection, and spoken response generation in a single streaming session. The system prompt injects the full menu with prices, sizes, and every valid modifier so the model is grounded in real data and cannot hallucinate items that don't exist.
Deployment is fully automated: every push to main triggers a GitHub Actions workflow that builds Docker images, pushes them to Google Artifact Registry, and deploys both services to Cloud Run using Workload Identity Federation for keyless authentication.
Challenges I ran into
The 1008 WebSocket error during tool calls. This was the hardest problem to solve. The Gemini Live API would intermittently throw 1008 errors and kill the session, but only while the model was executing tool calls. After extensive debugging, I traced the root cause: while the model was processing a function call, the user's microphone was still streaming audio. The model would pick up background noise or even its own spoken confirmation being played back through the speakers, interpret it as new user input, and enter a confused state that triggered the disconnect.
The fix was a tool gate mechanism. When the backend detects a function call event from Gemini, it immediately blocks all incoming audio from the microphone until the corresponding function response comes back. I also added automatic reconnection with exponential backoff and order context injection after reconnects, so even when errors do occur, the conversation resumes seamlessly -- the AI doesn't lose track of the order or re-greet the customer.
Repeated confirmations on multi-item orders. When a customer said "a grande iced latte and a cake pop," the agent would call add_item twice with a separate spoken confirmation each time -- "Got it, one iced latte!" ... pause ... "And a cake pop!" This felt slow and robotic, nothing like how a real barista responds.
I solved this by building batch tool variants (add_items, remove_items, add_modifiers). The model now sends a single JSON array with all items, gets one combined result, and gives one natural confirmation: "Got it, a grande iced latte and a cake pop. Anything else?" This cut the response time roughly in half for multi-item orders and made the conversation feel significantly more fluid.
Session staleness from the 10-minute limit. The Gemini Live API has a hard 10-minute session limit. If a customer takes a while browsing the menu or asking questions, the session would die mid-conversation with no warning. I implemented a proactive reconnection timer that silently tears down the old session at the 8-minute mark and spins up a new one, injecting the current order state as context with a system message telling the model it's mid-conversation and should not greet the customer again. From the customer's perspective, nothing happens -- the conversation just continues.
Accomplishments that I'm proud of
The moment that validated the whole project was ordering "a grande iced oat milk latte, two cake pops warmed up, and actually make that latte a venti instead" -- and the agent handled the entire thing in one fluid exchange. The batch add, the warming modifier, the size correction, all processed correctly with a single natural confirmation. That's the kind of interaction that proves this isn't a toy demo -- it's a system that handles the real complexity of voice ordering.
I'm also proud of the resilience engineering. The tool gate, the proactive reconnects, the Firestore persistence, the idempotency guards -- none of these are visible to the user, but they're what make the difference between a demo that works when conditions are perfect and a system that works reliably under real-world conditions.
What I learned
The biggest lesson was that tool design matters more than prompt engineering for live voice agents. I spent days tuning the system prompt, but the real breakthroughs came from changing how tools work -- batch operations instead of sequential calls, idempotency guards to prevent duplicate modifiers, sequential integer IDs instead of UUIDs (which the native audio model would hallucinate). The tools are the interface between the model and your application, and getting that interface right is what determines whether the agent is reliable or unpredictable.
I also learned that building for real-time audio is a fundamentally different discipline than building for text. In a text chatbot, a two-second delay is fine. In a live voice conversation, two seconds of silence makes the customer think the AI didn't hear them, so they repeat their order, which creates a feedback loop. Every architectural decision I made -- the tool gate, the proactive reconnects, the batch operations -- was driven by a single constraint: silence is failure.
What's next for Brew
The menu is loaded from a JSON file. Swap it out, and Brew becomes a taco shop, a pizza place, or a pharmacy pickup counter. The next step is building a pipeline that takes any restaurant's menu and automatically generates a ready-to-deploy voice ordering agent -- menu data, system prompt, and item images included.
The hard part was proving that a live voice agent can handle complex, modifier-heavy ordering with interruptions, corrections, and batch operations -- correctly and reliably. That's done. Now it's about making it work for anyone, in any language.
Cloud Deployment Proof https://youtu.be/HD2pyrYQiaM
Built With
- docker
- fastapi
- github-actions
- google-agent-development-kit-(adk)
- google-artifact-registry
- google-cloud-firestore
- google-cloud-run
- google-gemini-live-api
- google-genai-sdk
- next.js
- python
- react
- typescript
- web-audio-api
- websockets
- workload-identity-federation



Log in or sign up for Devpost to join the conversation.