-
-

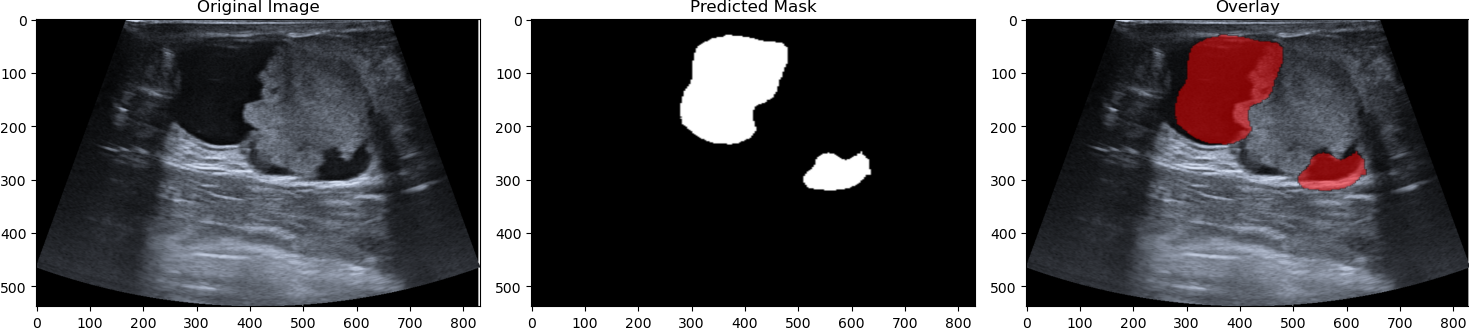
Demo segmentation 1. Singl tumor segmentation
-
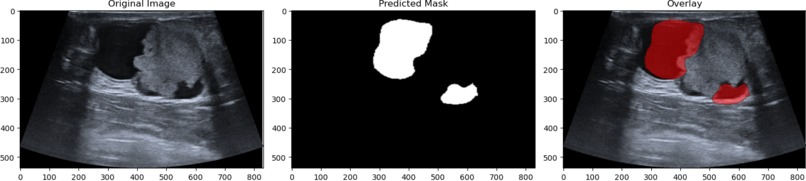
Demo segmentation 2. Multiple tumor identification and segmentation

Breast Cancer Tumor Segmentation
Breast Cancer Segmentation done with Pytorch.
Breast cancer is the 2nd most common type of cancer in women and had over 300k new cases estimated for 2025 in the US alone (1) (2). Breast cancer also has a mortality rate of 2.3%, making it critical that it is detected early and accurately (2). Breast cancer is often screened for with ultrasounds and it is critical for initial diagnosis (3). Our project is Computer Aided Diagnoses (CADe) which can assist doctors in performing quick and accurate diagnoses (4).
Our project leverages Deep-Learning techniques including semantic image segmentation and image classification to accurately identify, locate, and classify the risk of tumors in breast cancer ultrasounds. This project aims to help healthcare professionals produce accurate diagnoses more quickly and more cheaply in order to allow patients to move towards treatment at an earlier stage of the cancer.
Here is a demonstration of the segmentation:

A custom UNET was written to perform semantic segmentation on the datasets used. The model produces a Binary Cross Entropy Loss of 0.163. The model also produces a dice score of 0.88 This means the model has over an 80% confidence in each pixel's classification and overlaps with test data for 88% of all pixels. The activation function can be modified to increase the dice score and by default it is set to 0.45.
Additionally, the model can segment multiple separate tumors as shown below:

The model also uses image classification to categorize tumors as normal, benign, or malignant with over 70% accuracy. The model is designed to be slightly biased towards identifying tumors as malignant in order to increase false positives and reduce the risk of an aggressive tumor being identified as of lower urgency.
A lot was learned during the creation of this project. We had trouble getting the classification model to converge due to all tumors looking very similar and having a very small dataset. Some of the things we did to increase the model's accuracy was to augment the data and start a higher initial resolution for the UNET. We also learned a lot about the data processing pipeline, and how to combine different data sets as well as augment the data. The UNET was also a new project, and implementing one proved to be quite a challenge that required developing a greater understanding of computer vision and neural networks. Getting a multiplatform UI to work was difficult, and we sometimes had issues with merge conflicts while developing it.
Some next steps include expanding the classification to include different types of imaging including MRI images. Additionally, considering a patient's genome sequence could help evaluate the urgency of a tumor, or for patients with no tumor, potential future risk. Additionally, being able to differentiate the lesion for multiple tumors in 1 image would also be important.
Datasets used:
Pawłowska, A., Ćwierz-Pieńkowska, A., Domalik, A., Jaguś, D., Kasprzak, P., Matkowski, R., Fura, Ł., Nowicki, A., & Zolek, N. A Curated benchmark dataset for ultrasound based breast lesion analysis. Sci Data 11, 148 (2024). https://doi.org/10.1038/s41597-024-02984-z
Accessed Feb 22 2025
https://www.kaggle.com/datasets/aryashah2k/breast-ultrasound-images-dataset?resource=download
Accessed Feb 22 2025


Log in or sign up for Devpost to join the conversation.