-
-
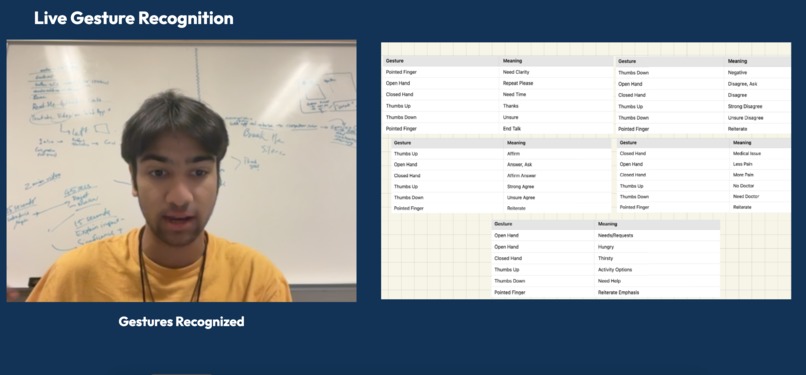
Demonstration of Camera Page
-
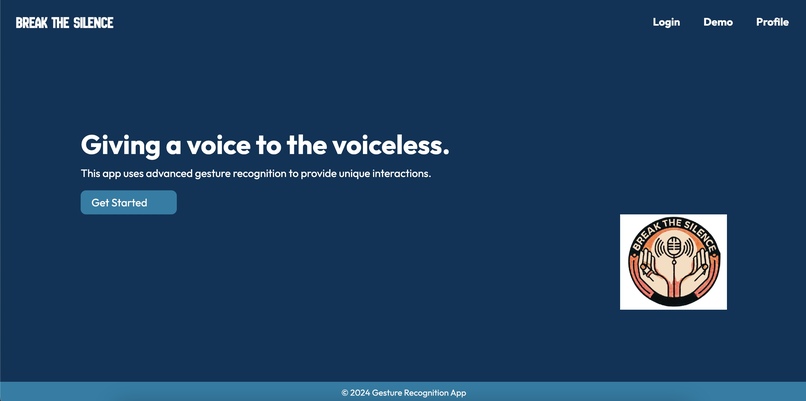
Website Homepage
-
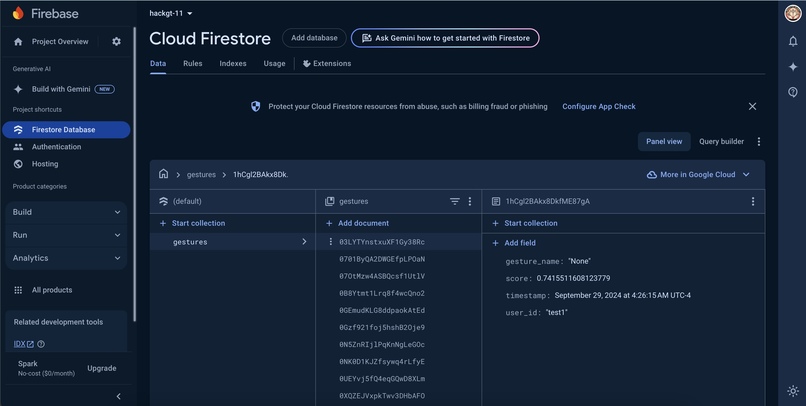
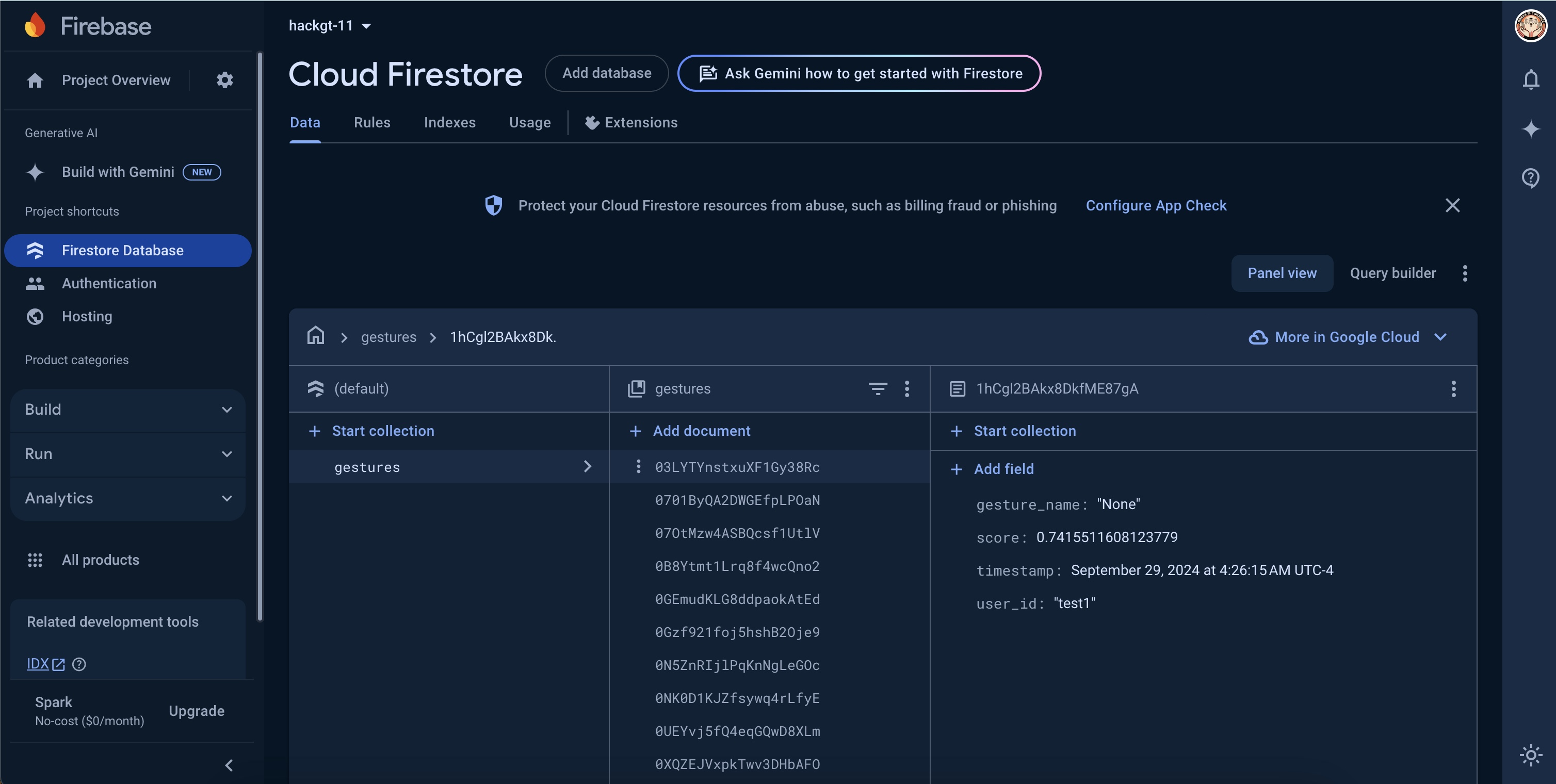
Cloud Firebase Database of Gestures
-
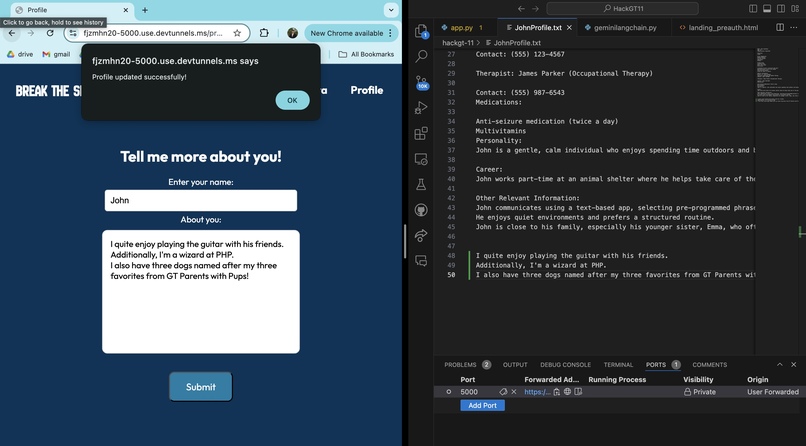
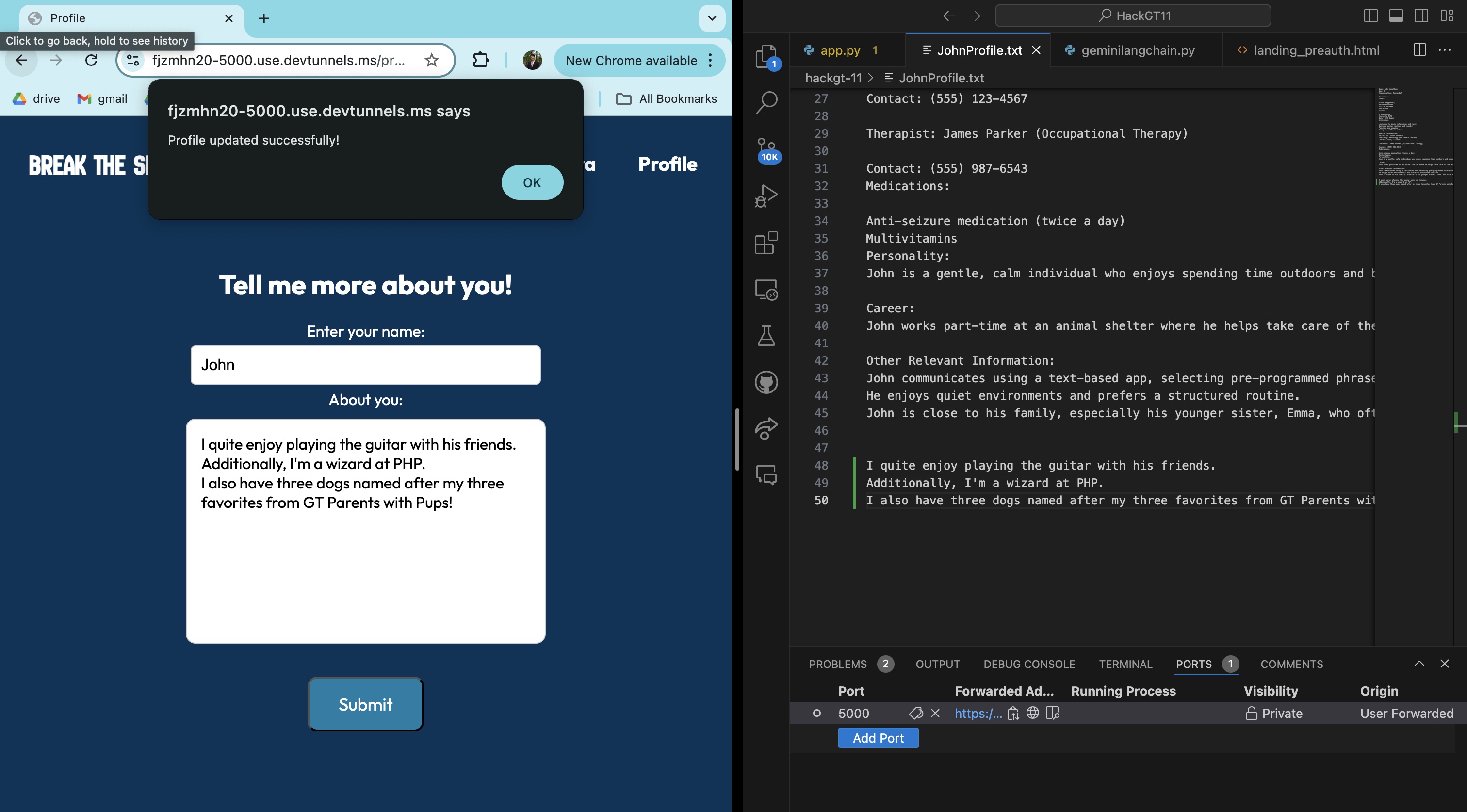
Demonstration of Personalization Profile

Inspiration
Our team was inspired by the communication difficulties we have witnessed in our healthcare system. We wanted to find a way to effectively close the communication gap for nonverbal children, students, and elderly individuals while minimizing their movement or effort.
What it does
Break the Silence is a web application that acts as a virtual chatbot with a nonverbal individual by leveraging computer vision through gesture recognition through Mediapipe and a Gemini Large Language Model to communicate personalized responses to the user. The app starts on a landing page that allows users to register, log into an existing account, or set profile preferences. User log-ins and authentications are stored in a Firebase database using Google Cloud Platform integration, as well as user-specific text files containing personalized descriptions. After logging in, the user can open the main part of the application in the camera section. On the front end, the user sees a camera and a key to what gestures correspond to what thoughts or responses to a stimulus. There are two options once this page has been reached. The first choice is for the user to make two gestures to the camera, which are picked up by a constant live video stream, parsed, and then categorized into one of 5 gestures by the Mediapipe-based computer vision model. As the user makes a gesture, our system interprets it in real time. Then, thanks to our memory language chain, the platform builds a contextualized conversation. The language model produces an audio clip of its response to the user's gesture input, which triggers a conversation loop between the user and those around them through the model as a proxy. The second choice is for the user to press the record button, which will record another person speaking in a conversation. Using WebRTC Voice Activity Detection, our application will recognize when the other person stops speaking and immediately send the audio to the language model to further personalize responses with the added context. This allows outside conversationalists to ask questions and provide context to the user through a live listening capability.
How we built it
We separated our project into five main subsections: Computer Vision (Mediapipe), Audio (WebRTC Voice Activity Detection), LLM (Gemini), Frontend, and Backend (Firebase). Although each one of us primarily worked on a different subsection, we all collaborated effectively with one another to have the parts complement each other. For example, we built in a chat memory functionality into the LLM so that it could remember certain contexts from the conversations provided by the audio inputs. We also added functionality to include a user-bio through firebase, which acts as a document for a custom-built RAG for our LLM, providing even more context and more descriptive chat responses. For the LLM portion, it was built using Lang Chain and Lang Graph for the memory and RAG functionalities. We decided on using the Gemini-1.5-Flash API given its free tier with generous rate and token limits. As for the audio, we used WebRTC Voice Activity Detection to detect whether a person was speaking or not, then subsequently saved the file of them speaking as a .mp3 file in order to pass it along to the LLM. Using Flask, we created our web app that integrates all of the components together, creating a streamlined flow from frontend (landing page etc.) to user auth (firebase) then gesture recognition, and finally to an LLM API call to create the user's desired natural language message. The audio processing of the speech-to-text utilizes the Whisper model to parse through the text and pass it on as context.
Challenges we ran into
We primarily ran into challenges combining all of our separate portions together. One especially large challenge was bringing in audio, computer vision, and the LLM portions together as we had to determine what order and what type of loop conditions should exist in order for a seamless conversation. Yet another was the front-end, where certain decisions would affect the integration of various factors like our backend and computer vision.
Accomplishments that we're proud of
We’re proud to have developed a high-complexity platform by effectively combining multiple technologies. Our biggest achievement was creating a robust memory system using Retrieval-Augmented Generation (RAG), which allows context-aware responses to gestures. We successfully integrated real-time gesture recognition with seamless audio input/output, enabling intuitive bi-directional communication through the camera. Each component—from gesture recognition to contextual memory—came together smoothly, and we were truly excited about what we were able to create.
We are proud of the fact that we were able to collaborate together and build such a high
What we learned
We learned how to integrate complex components like gesture recognition, memory chains, and audio processing into a seamless platform. Building context-aware responses using RAG taught us the importance of robust memory systems for natural interactions. Collaborating across different technologies enhanced our skills in real-time data processing and user-centered design.
What's next for Break The Silence
We plan to enhance the gesture recognition model to support a wider range of movements and refine audio responses for improved accuracy. Our goal is to incorporate multilingual support and explore more sophisticated AI for better context interpretation, ultimately creating a more inclusive and adaptable platform for non-verbal communication.



Log in or sign up for Devpost to join the conversation.