-
-

Break the Chain logo
-
Onboarding
-
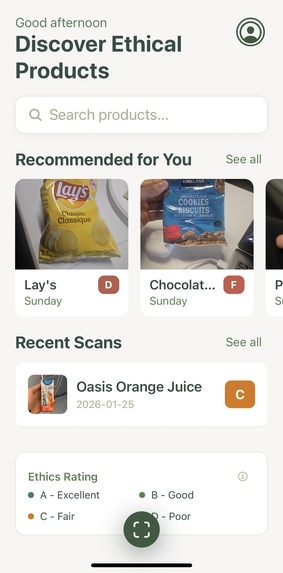
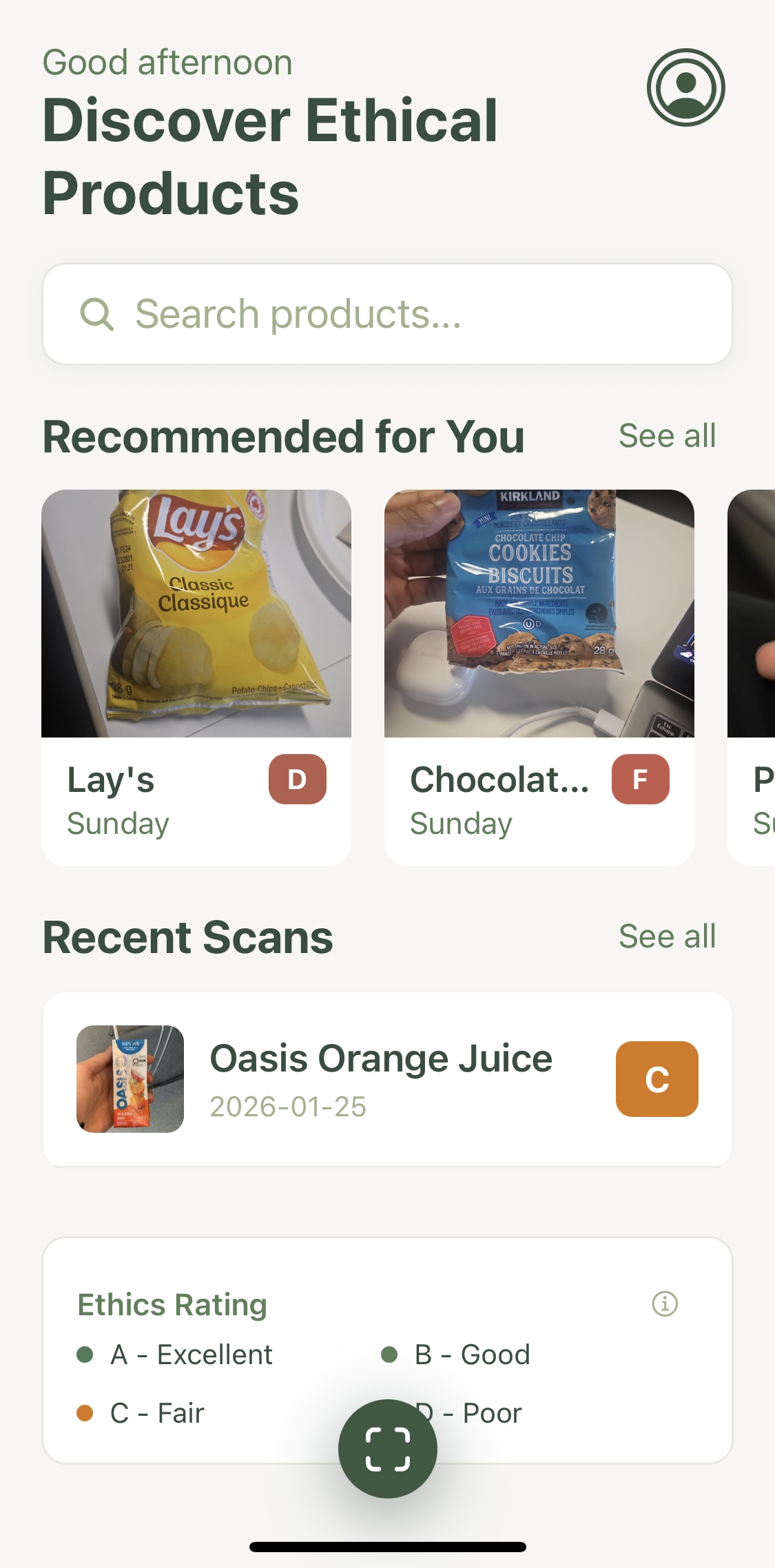
Main Page
-
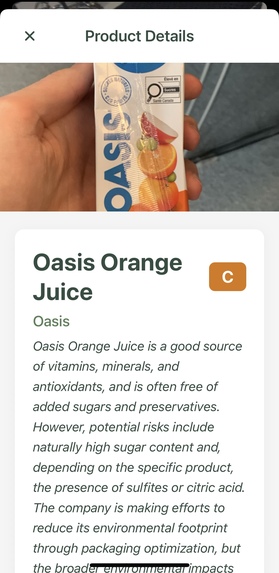
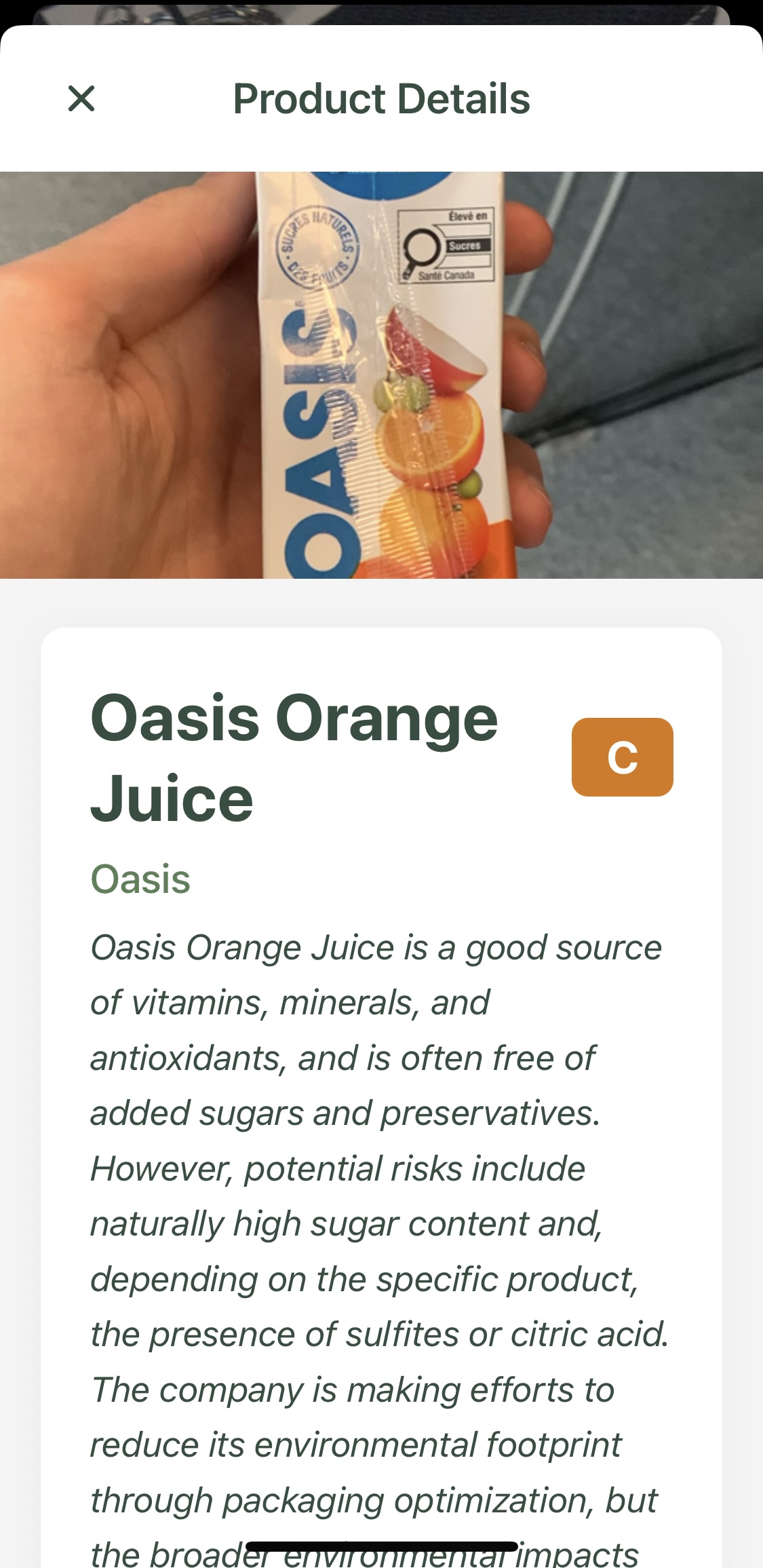
Scanned product report
-

AI chatbot


Project Origin: The Transparency Gap
We live in an era where consumers are more conscious than ever about fair trade, ethical sourcing, and organic standards. However, despite this awareness, the actual data available at the point of purchase remains remarkably opaque. We realized that while people want to make better choices, they lack a comprehensive view of a product’s entire lifecycle and production chain.
The Solution: Traceability at Your Fingertips
Our project is a mobile platform designed to bridge the information gap. It allows users to instantly discover the origin, journey, and impact of any product they purchase. By scanning an item, users can analyze its footprint across three critical pillars:
- Human Health: Potential risks or benefits of ingredients and materials.
- Ecology: The environmental cost of production.
- Pollution: The waste legacy and carbon footprint left behind.
The Tech Stack
To build a responsive and scalable MVP, we utilized a modern, decoupled architecture:
| Component | Technology |
|---|---|
| Mobile Frontend | React Native |
| Backend API | Node.js with TypeScript |
| Database | MongoDB |
| Intelligence | Gemini API (Multi-Agent Orchestration) |
| Hosting | Render and Vultr |
How It Works: Technical Workflow
The application operates through a coordinated pipeline between the client and our AI-enhanced backend.
- Data Capture: The React Native frontend captures a product image and identifies it via the Gemini API. This identification is sent to our Node.js REST API.
- Parallel Agent Orchestration: To analyze the product, the backend triggers three specialized Gemini agents simultaneously. Each agent focuses exclusively on one category: Health, Ecology, or Pollution.
- Data Synthesis: Once the parallel processing is complete, the API compiles the findings into a global rating, a comprehensive review, and a list of verified sources.
- Delivery & Persistence: The detailed report and grade are served back to the frontend for the user. Simultaneously, the result is indexed in MongoDB to populate the user's scan history.
The Development Journey
Our team of four divided into specialized roles to maximize efficiency:
- Frontend (2 Members): Leveraged React Native modules to build a seamless UI and integrated the camera-to-API workflow.
- Backend & Data (1 Member): Architected the REST API and managed the MongoDB schema to handle complex product lifecycles and user history.
- AI Implementation (1 Member): Focused on prompt engineering and managing the parallel execution of AI agents to ensure accurate, structured data.
Overcoming Hurdles
The path wasn't entirely smooth. We faced significant challenges with prompt engineering to prevent "hallucinations" and ensure structured JSON outputs. Additionally, infrastructure bottlenecks forced a mid-hackathon to partially migrate from Vultr to Render to ensure a stable, high-speed connection for our API.
Final Features and Impact
What began as a simple idea evolved into a robust consumer ecosystem:
- Comprehensive Lifecycles: Detailed "step-by-step" breakdowns of a product's journey from conception to shelf.
- Ethical AI Advisor: An integrated chatbot that provides personalized advice and recommendations based on your scan history, helping you navigate complex ethical dilemmas.
- Sustainable Alternatives: The app suggests local, more sustainable alternatives to the scanned product in real-time.
- History & Social Feed: A personalized log of past scans and a community feed to discover popular, high-rated items.
Future Roadmap: Semantic Discovery
Our next milestone is to transition from keyword-based lookups to a more intelligent discovery system. We plan to implement Vector Space Search within our MongoDB database.
By generating and storing vector embeddings for every product in our system, we will be able to perform semantic searches. This means the app will understand the "context" of a product—allowing the AI Advisor to suggest alternatives based on deep similarities in production methods and ethical scores, rather than just matching category names.
We already started to integrate this new database schema and search process, however, we did not have the time to finely tune it, so the code is there, it just needs some tweaks ! We opted to refine the prompts we gave the AI to have more reliable responses.


Log in or sign up for Devpost to join the conversation.