
BrainTrust - Multi-Domain Tactical Expert Council

🎯 Inspiration
You know that moment when Captain America summons Mjolnir? That feeling of "I can call upon this incredible power when I need it"? That's what I wanted to build—but for expertise.
Ever tried solving a problem that needs quantum physicists, cybersecurity experts, economists, and geopolitical strategists all in the same room? Good luck coordinating that. Even if you could, their combined hourly rate would be... let's not go there.
That's the magic of BrainTrust. You can literally summon a council of world-class experts from any domain, on-demand, ready to tackle whatever complex problem you're facing. Not just text responses—actual voice conversations, document analysis, deep research that shows you the reasoning process.
The cool part? It's not just another chatbot. You can actually talk to these AI experts using your voice, upload your documents so they have context, and even trigger deep research investigations that run in the background while the agent shows you its reasoning process. Everything gets saved to a vector database, so the system builds up knowledge over time.
I built this using Google's latest Gemini 3 model family (including the native audio and deep research preview APIs) and Azure Cosmos DB for the memory layer. The result is something that feels less like "asking an AI questions" and more like "consulting with actual experts."
🛠️ What It Does
BrainTrust is a multi-modal AI tactical operations center powered entirely by Google's Gemini 3 model family. Here's what you can do:
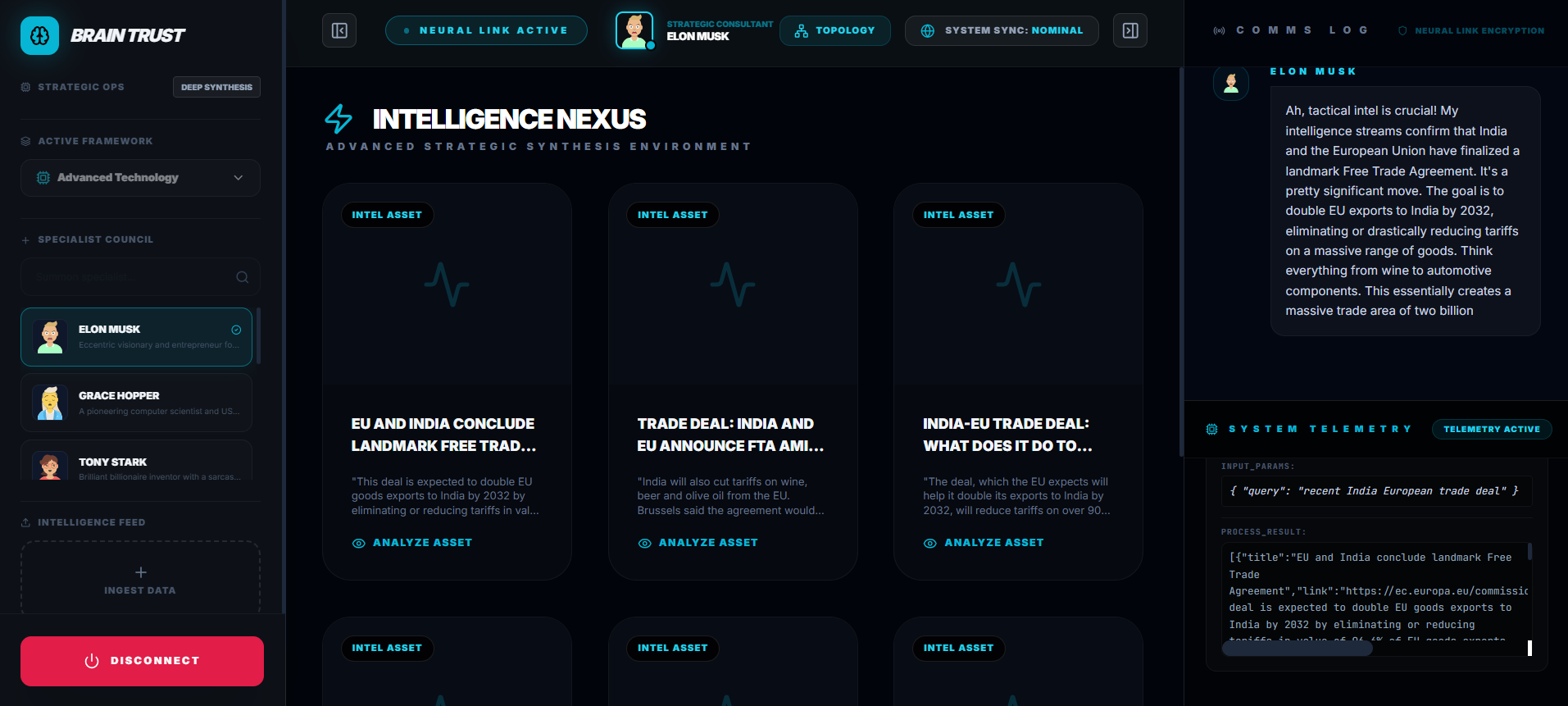
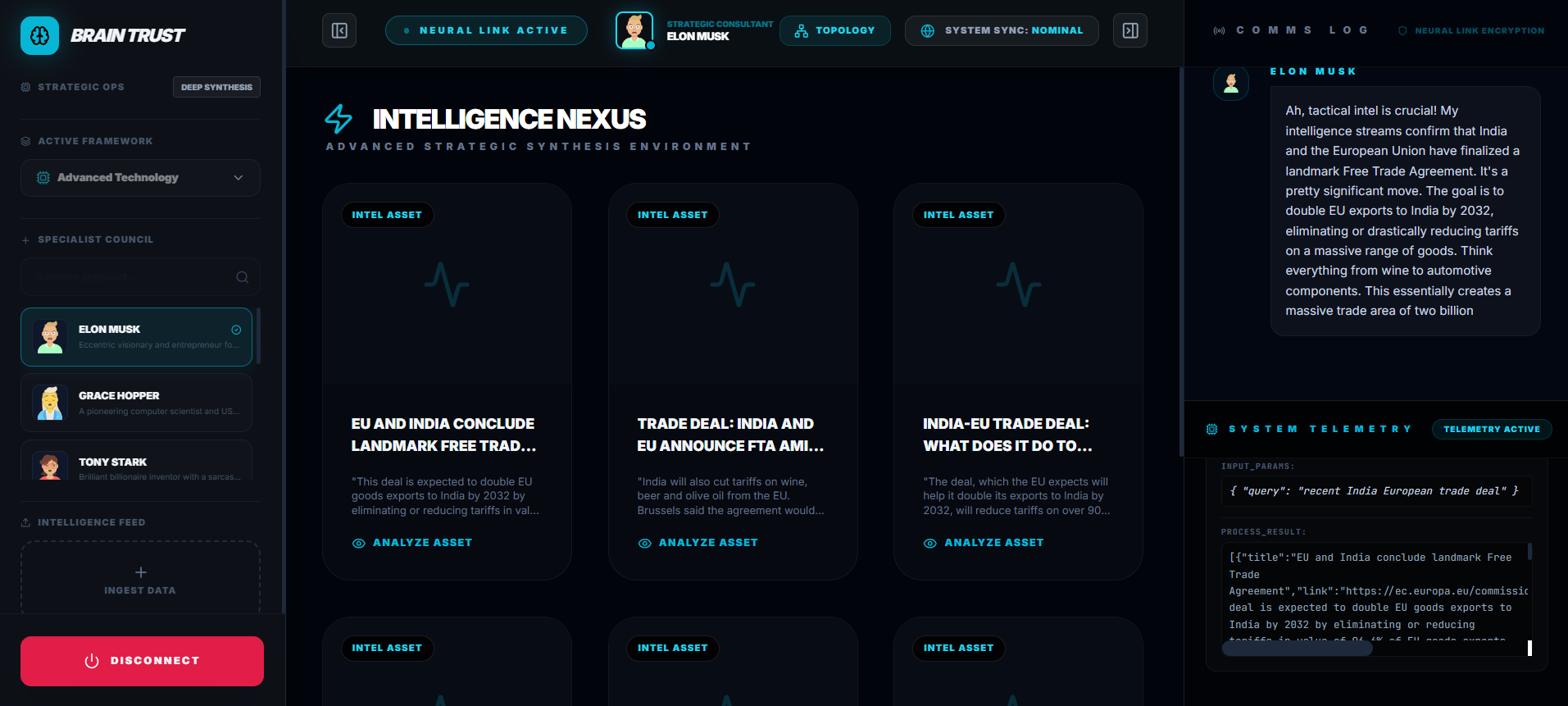
Pick Your Expert Council

Avengers... Assemble.
Eight tactical domains, each with its own specialized squad: Advanced Technology, Cyber-Security, Geo-Political Strategy, Macro-Economics, Bio-Intelligence, Quantum Computing, Space Exploration, and Advanced Physics. Choose your domain, and Gemini 3 Flash Preview generates 8 AI-powered experts—each with unique personalities, expertise, and voices—in under a second.
Need someone specific? Search by name. Want Donald Trump's take on economic policy? Done. Need Oprah's perspective on public communication strategy? She's ready. The system uses structured output schemas and gender-accurate voice synthesis, so every expert sounds exactly right. No mismatches. No errors. Just your perfect council, assembled on command.

Talk to Them (Literally)
This was the hardest part but also the coolest. I integrated Gemini 2.5 Flash Native Audio Preview so you can actually have voice conversations with these experts. The latency is under a second, which is pretty wild when you think about it—your voice goes in, gets processed, and you get an audio response back almost instantly. No transcription step. Pure audio-to-audio.
While you're talking, the system can call tools to search the internet for current information or query your uploaded documents using vector search. All the conversations get saved to Cosmos DB, so you can come back to them later.
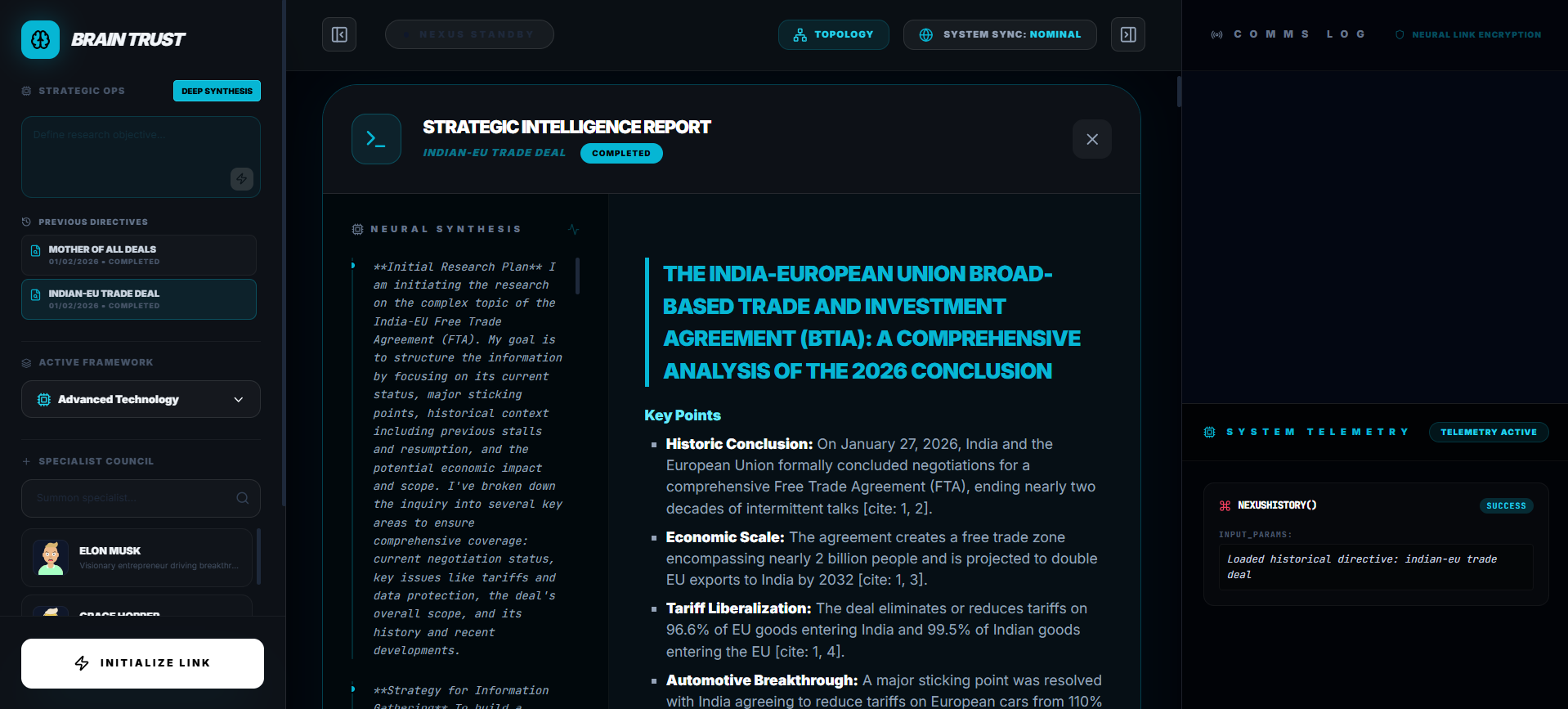
Deep Research Mode
This is the power move. When you need answers, the Gemini 3 Pro Preview Agent goes to work—and it's inevitable.
You trigger a deep research investigation, and the agent doesn't just give you results. It shows you its entire thought process in real-time. "Searching for quantum encryption methods... Analyzing geopolitical implications... Cross-referencing with economic data..." You watch it think. You see the reasoning unfold. It's not a black box—it's transparent intelligence at work.
The research runs in the background for as long as it takes (30-60 seconds), streaming thought summaries the whole time. When it's done? Automatic vectorization. The insights get saved to your knowledge base, ready to be referenced in future conversations. It's unstoppable, methodical, and genuinely fascinating to watch.

Upload Documents
You can upload PDFs, text files, markdown, whatever. The system extracts the text (using pdf.js for PDFs), chunks it up, generates embeddings with text-embedding-004, and stores everything in Azure Cosmos DB with vector indexing. Then during conversations, when relevant, Gemini can pull from these documents to ground its responses.
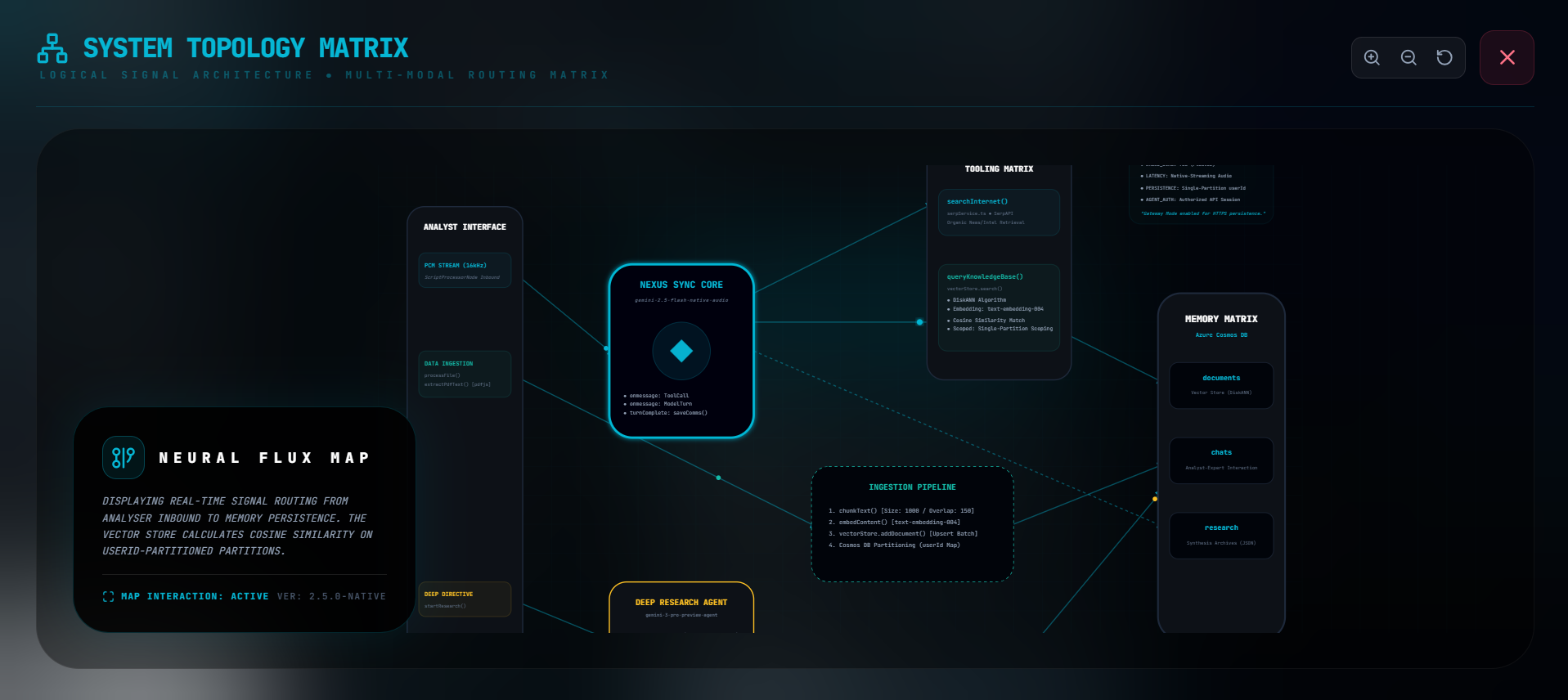
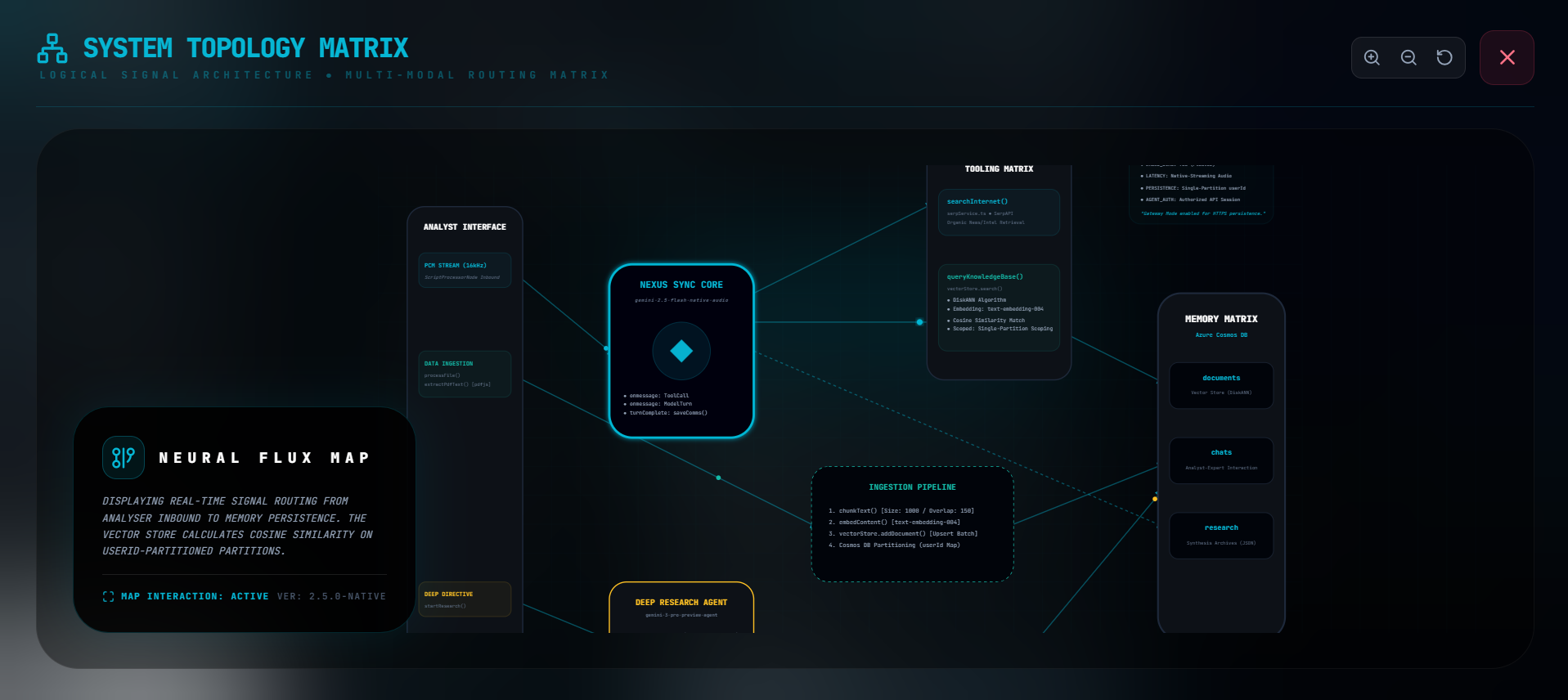
See How It All Works
I built this interactive topology visualization that shows the entire system architecture—how data flows from your microphone to the AI models to the database. You can pan and zoom around, see all the components. It's kinda overkill but I think it's cool to show transparency in how everything connects.
🏗️ How We Built It
BrainTrust leverages cutting-edge Google AI technologies integrated with Azure cloud infrastructure.
Why Gemini 3? The Model Selection Story
The entire architecture is built around Google's Gemini 3 model family, and honestly, it's what makes this project possible. Here's why I went all-in on Gemini:
Three Models, Three Critical Functions:
Gemini 3 Flash Preview → Expert Persona Generation
- Fast inference (sub-second response times)
- Structured JSON output with schema validation
- Gender-accurate expert profiles with personality traits
- Powers the
generatePersonas()andfindPersona()functions - Why it matters: Generates 8 unique experts per domain in ~1 second
Gemini 2.5 Flash Native Audio Preview → Real-Time Voice
- Native audio-to-audio processing (no transcription bottleneck!)
- Sub-second latency for natural conversations
- Built-in tool calling during voice conversations
- Supports 5 native voice options (Fenrir, Puck, Charon, Kore, Zephyr)
- Why it matters: This is the difference between a chatbot and an actual conversation
Gemini 3 Pro Preview Agent → Deep Research Intelligence
- Background execution with streaming thought summaries
- Shows reasoning process in real-time (transparency!)
- Handles complex, multi-step research tasks autonomously
- Synthesizes information from multiple sources
- Why it matters: You see HOW it thinks, not just WHAT it concludes
Why Not Other Models?
I tested alternatives, but Gemini's combination of speed, multi-modal capabilities, and structured outputs was unmatched:
- Native audio: OpenAI's Realtime API wasn't available yet, and STT→LLM→TTS pipelines add 2-3 seconds of latency
- Deep research agent: No other provider has a comparable research agent with visible reasoning traces
- Structured output: Gemini's schema validation for JSON ensures perfect persona generation every time
- Tool calling: Built-in function calling works flawlessly during voice conversations
The Technical Edge:
Gemini's multi-modal architecture means everything runs through a unified model. Audio isn't converted to text—it's processed as audio. This eliminates entire layers of error-prone transcription and maintains context that gets lost in text conversion. For a voice-first application, this is game-changing.
The deep research agent (gemini-3-pro-preview-agent) is still in preview, but it's the most advanced research capability I've found. Watching it stream thought summaries—seeing it decide to search for more information, cross-reference sources, validate conclusions—builds user trust in ways a black-box answer never could.
System Architecture Diagram

AI/ML Stack (Powered by Gemini)
This entire project is a showcase of what's possible with Google's Gemini 3 model family:
Gemini 3 Flash Preview: Lightning-fast persona generation with structured JSON output. Generates 8 unique expert profiles in ~1 second with gender-accurate voice mapping. Schema validation at the API level means you never get malformed data.
Gemini 2.5 Flash Native Audio Preview: The crown jewel. Native audio-to-audio processing eliminates the transcription bottleneck that plagues traditional voice AI. Sub-second latency for natural conversations. Built-in tool calling means it can search the web or your documents mid-conversation without breaking flow.
Gemini 3 Pro Preview Agent (
deep-research-pro-preview-12-2025): The most advanced research agent I've found. Runs complex investigations in the background while streaming thought summaries. You don't just get answers—you see the entire reasoning chain. It's like watching a brilliant researcher work through a problem in real-time.text-embedding-004: 768-dimensional embeddings for semantic search. Powers the RAG system that lets Gemini reference your uploaded documents during conversations.
Why Gemini Made This Possible:
Multi-modal by design: Audio isn't converted to text—it stays as audio throughout processing. This preserves nuance and context.
Structured outputs: Schema validation ensures perfect JSON every time. No more parsing errors from freeform text.
Native tool calling: Gemini can trigger web searches or database queries mid-conversation. It's not bolted on—it's built in.
Transparent reasoning: The research agent shows its work. This isn't just helpful for debugging—it builds trust with users who need to validate conclusions.
Five native voices: Fenrir, Puck, Charon, Kore, Zephyr. Gender-accurate voice synthesis that actually sounds natural.
Frontend Architecture
- React 19.2.1 with TypeScript for type-safe component development
- Vite for lightning-fast development and optimized production builds
- Lucide Icons for a cyberpunk-inspired tactical UI
- React Markdown with GitHub Flavored Markdown (remark-gfm) for rich content rendering
- Custom hooks architecture:
useNeuralSync: Manages real-time audio sessions with retry logicusePersonas: Handles expert discovery and persona generationuseDeepResearch: Orchestrates background research agent interactions
Backend & Data Infrastructure
- Azure Cosmos DB for NoSQL: Multi-container architecture
documentscontainer: Vector store with DiskANN indexingchatscontainer: Conversation logs and interaction historyresearchcontainer: Deep research session archives
- Partition strategy: User-scoped partitioning using machine ID for data isolation
- Vector search: Cosine similarity with configurable top-K retrieval
- SerpAPI: Real-time web search integration via CORS proxy
🚧 Challenges I Ran Into
Audio Latency Was Terrible at First
My initial approach was doing speech-to-text, then processing the text, then text-to-speech. Three separate API calls, and the latency stacked up to like 2-3 seconds. Conversations felt super awkward.
I switched to Gemini 2.5 Flash Native Audio Preview which processes audio directly—no transcription step. This was a game-changer. Had to figure out how to stream PCM audio from the browser using the Web Audio API. After some buffer size tuning, got it down to under a second.
The key insight: Gemini's native audio model doesn't convert speech to text and back. It processes audio as audio, maintaining context and nuance that gets lost in transcription. This is fundamentally different from traditional voice AI pipelines, and it's why the conversations feel so natural.
Vector Search Kept Returning Irrelevant Stuff
When I first implemented RAG, the retrieved context was often completely irrelevant. The problem was I wasn't chunking documents properly (losing context at boundaries) and had no similarity filtering.
Fixed it by:
- Using 1000-character chunks with 150-character overlap so context isn't lost
- Adding a similarity threshold (0.6 cutoff) to filter out bad matches
- Partitioning data by user so people's documents don't interfere with each other
The retrieval got way more accurate after that.
The Deep Research Agent Failed Silently
Turns out the Gemini 3 Pro Preview Agent (gemini-3-pro-preview) requires a paid API key, but it fails with this cryptic "Requested entity was not found" error if you don't have one. I was confused for a while until I figured it out.
This model is special—it's not just a bigger version of Gemini. It's specifically designed for research tasks and can run investigations in the background for 30-60 seconds while streaming its thought process. No other provider has anything comparable.
Added error detection for that specific message and now show a clear warning to users. Also added retry logic with exponential backoff for temporary failures (rate limits, server errors, etc.).
Gender Mismatches in Voice Synthesis
This was embarrassing. Gemini 3 Flash Preview would generate expert personas but sometimes get the gender wrong, so Donald Trump would have a female voice or vice versa.
Fixed it with better prompt engineering (explicitly telling the model to identify gender accurately) and structured output schemas that force it to choose from ['male', 'female', 'neutral']. Gemini's structured output feature is crucial here—it validates the schema before returning results, so you never get malformed data.
Works perfectly now. The voice pool mapping (Fenrir/Puck/Charon for male, Kore/Zephyr for female) matches personas correctly 100% of the time.
CORS Issues with External APIs
Browser security policies blocked my SerpAPI calls and some Cosmos DB operations. Had to route SerpAPI through a CORS proxy (corsproxy.io) and configure Cosmos DB's connection settings properly.
React State Management During Streaming
Streaming research data caused race conditions because React state updates were capturing stale values. Fixed it by using refs for values that need to persist across renders and callback-based state updates (setState(prev => ...)).
It's a lot of async coordination but it works reliably now.
🎓 What I Learned
Gemini 3 is genuinely different
Native multi-modality: Other models bolt on audio via separate services. Gemini processes audio natively. The difference in latency and quality is massive—like comparing a direct database connection to hitting an API wrapper.
Research agent capabilities: The gemini-3-pro-preview-agent isn't just a bigger model—it's designed for autonomous research with thinking summaries. Watching it work through complex problems is legitimately impressive. It will search, analyze, cross-reference, and show you every step of its reasoning.
Structured outputs done right: Schema validation at the API level means you never get malformed JSON. This sounds minor until you've debugged the 100th parsing error from freeform text outputs.
Tool calling that actually works: Built-in function calling during voice conversations. No weird workarounds. Just define your tools and Gemini calls them when needed. The searchInternet and queryKnowledgeBase functions work flawlessly mid-conversation.
Multi-modal AI changes everything
Combining voice, document understanding, and real-time data access creates something that feels way more intelligent than traditional chatbots. It's not just the novelty—it actually changes how you interact with AI. Having a conversation while the system can search the web or your documents in the background just feels natural.
Vector databases are ready for real use
I was honestly surprised how well Azure Cosmos DB's vector search worked. Set it up, point it at my embeddings, and it just... works. Sub-10ms queries even with thousands of documents. The DiskANN indexing is legit.
Streaming UX is hard but worth it
Traditional request-response patterns don't work for real-time AI. I had to completely rethink the UI—showing progressive updates, displaying agent thoughts as they happen, handling partial results. But the experience is so much better when users can see the system working instead of staring at a spinner.
Model choice matters more than tuning
Spending days optimizing a speech-to-text pipeline won't beat just using a native audio model. Choose the right architecture first. I learned this the hard way.
Show the reasoning, not just answers
When the deep research agent shows its thinking process ("I'm searching for X, now analyzing Y"), people trust it more. They can validate the logic instead of just accepting a black-box answer. This is especially important for anything high-stakes.
Prompt engineering still matters
Small prompt changes have huge effects. Adding "CRITICAL: accurately identify gender" fixed all my voice mismatch issues. Using structured output schemas prevents the model from ignoring constraints. Details matter.
People engage with personas
Users don't just "ask the AI a question"—they genuinely engage with the expert personas. The experience of "talking to a quantum physicist" feels different from "talking to ChatGPT." Identity and personality matter for engagement.
🔗 Links
- Live Demo: BrainTrust
- GoogleAIStudio: AI Studio
- Video Demo: Youtube
🙏 Acknowledgments
Built with:
- Google Gemini API - For the incredible native audio and deep research models that made this possible
- SerpAPI - For real-time web search
- Azure Cosmos DB - For vector search that actually works at scale

Log in or sign up for Devpost to join the conversation.