


Inspiration
One of the things our team thought about going into this hackathon is “How could we find an underrepresented prevalent problem, and create an intelligent, valuable solution?” This guiding question, combined with our interest in upcoming and hot technology, is what lead to the innovative solution that is BountAI. Our team has first hand experienced the issues regarding ML accessibility, both on the data end, and the hardware restrictions. It was also a growing concern our team noticed, in which the grip and control over services that provide such assistance to training models have become ever more dangerous. It’s dangerous in the manner that monopolies over Ml, data accessibility, and computing power (we’re looking at you, Amazon) only drives out the jobs and businesses of independent data scientists, ML specialists, and other related service businesses. We were so surprised to see a literal multi-billion-dollar problem under the hood- most likely not a coincidence, that we felt compelled to create a better solution. Something that would support smaller businesses, independent data scientists, as well as other professionals, yet also provide better access to quality data and state of the art hardware, that is also cheaper than traditional options, while providing the same quality of both the cloud infrastructure and professional services.
What it does
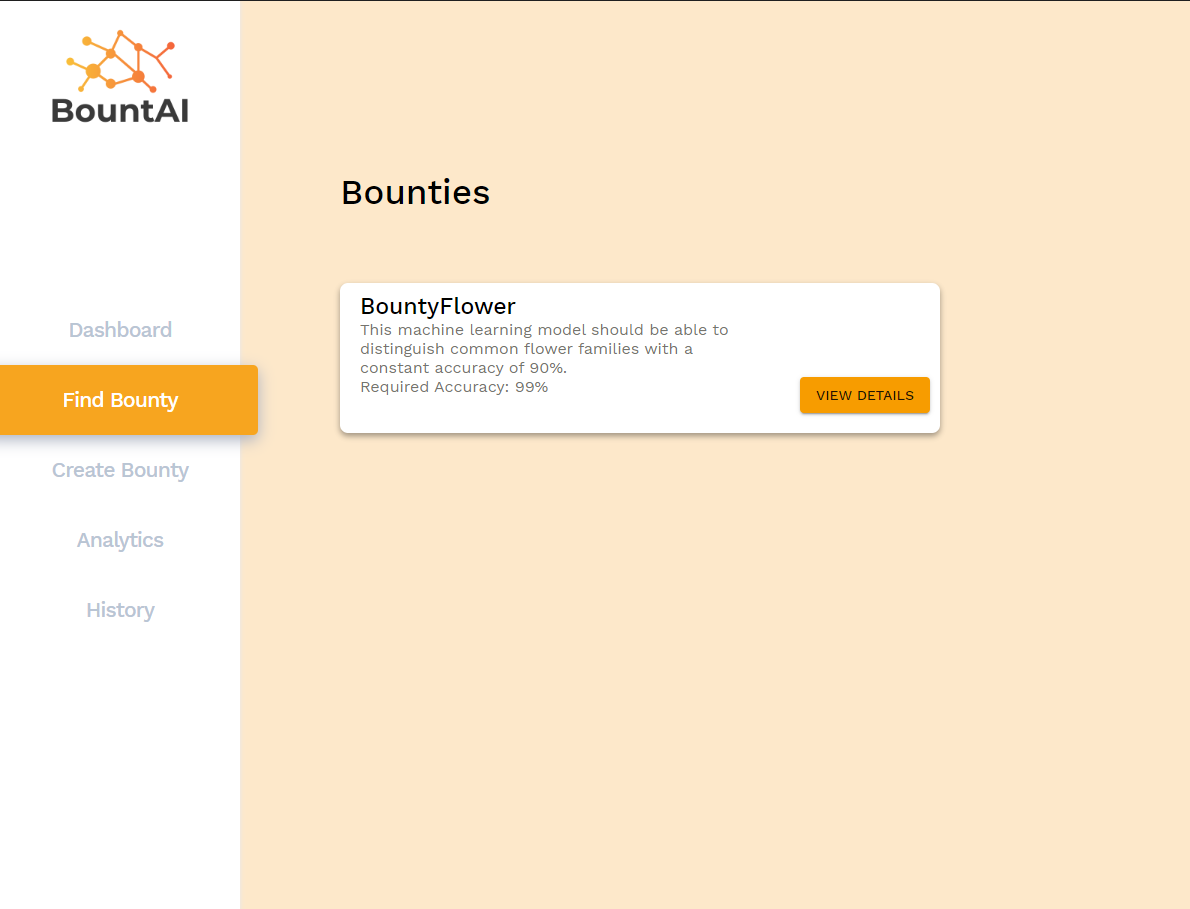
BountAI is a decentralized market place that brings users seeking to purchase fully-complete, state of the art machine learning models, to freelance data scientists, machine learning enthusiasts, or even small businesses that can get the job done. The way the system works is that a user places a Bounty (Thus, BountAI) on the platform. This bounty contains information such as Name, Description, price, and requirements. The requirements consist of details such as target accuracy. A user is also prompted to optionally upload a base model file that is part of the package associated with the Bounty. The buyer must also provide a set of test data to be used for grading. A user can monitor their bounties status and details, which we will cover on more in a moment. From a Freelancer’s perspective, a plethora of bounties is available on the platform in order to be taken on. A Freelancer can view any given Bounty, and download the base information, along with the requirements (accuracy) and the details. The Freelancer can then use their own data and hardware to train the model provided by the Buyer or train their own, as long as it fits the specifications. When a Freelancer is confident they have completed the job or improved the model, they can submit their model file, or otherwise known as “accepting” the bounty. The file they submitted is sent back to our backend for testing. The model is put against the hidden test cases that were initially provided by the Buyer. The accuracy results are then returned, and from here multiple things happen. The first thing is that the submission data ( accuracy, user, bounty) is stored in our blockchain infrastructure. The second thing that happens is the accuracy is placed against other submissions, as well as the requirements. If the user submits a model that beats all other models in terms of accuracy, they are entitled to a proportional amount of the total bounty. For example, if I submit a model that scores 70%, but the target is 80%, I could still gain a proportional percentage of the total bot/bounty price, sent automatically and trustlessly to my wallet. This only happens, however, if my model maintains the high score of accuracy for the given Bounty. Following this interaction, the “base model” initially provided by the Buyer is actually replaced by the most accurate current model. Other users can then download this model and attempt to help strengthen the accuracy through their own data and training. Users can only ever submit once, however. The idea behind this system is to help collaboratively build strong, useful models, while providing a valuable incentive to those who were close to meeting the bounty, but still nonetheless extremely useful. Once a model that finally meets the accuracy requirement is submitted, the bounty is closed, and the rest of the money remaining in the bounty pool is given to that user. In the event that it is the first submission, they would get the whole bounty payout. We also provide useful analytics that shows a user’s past submissions, a bounty creator’s bounty progress (the submission), among different things. This product operates fully autonomously and trustlessly due to the decentralized architecture, which does not even use a database at any point.
How we built it
The infrastructure of our program is incredibly complex. We had to use numerous libraries, systems, as well as clever problem solving to create a fashionable solution to the problem. Our main backend was written in node.js & express, and we had numerous endpoints that were used to serve the client. We also had a Flask server that connected to the python script to connect to our ml file parser. We are using the Tensorflow board as well as Tensorflow Summary to deconstruct the community trained models so we can see if the said model is up to specifications. We also run the submitted model files though the original users testing data set in order to determine the model's accuracy, loss and any other user-defined specifications. We used ipfs to keep track of test data reference and model files. We used our own custom ipfs-db library solution to create a key pair value storage that was used to handle a majority of the other user data and references. We used Solidity and Remix to develop and debug our smart contract which is quite extensive. We used the experimental abi-encoder that allowed us to use advanced features to automate the entire payment processing system in the trustless system. We used ethers.js in our node.js backend to interact with the smart contract, which we deployed using truffle.js onto our Ganache local RPC network. We would call the smart contract functions from endpoints that would be used to administrative further data. We used metamask as our web3 injector and provider for the project. Web3 was our way of obtaining all the accounts from the provider to be used in the Dapp. Take a look at the source code and specifically the smart contract (which is commented) to get more details about the inner workings. Our front end was built by the very talented Daniel Yu, who designed and implementing everything in React, where all our endpoints were called from.
Challenges we ran into
There was one particular problem Markos in our group faced. His entire smart contract that he wrote in Remix was deleted when his browser crashed. He had to write the entire smart contract twice, and that was very frustrating to deal with. Other than that, debugging this super complicated system, given all the components to keep track of, was a big pain. It took probably 80% of our actual dev time debugging and testing the systems. We had to use multiple debuggers and testing platforms like postman to play find the bug.
Accomplishments that we are proud of
Our team is very proud of our ability to persevere through some very tough problems. As 3 grade 10s and 1 grade 11, we can positively look back upon what we made, and be satisfied with the effectiveness of our solution to a prominent issue, as well as the pure technicality that we managed to organize and execute.
What we learned
I think I will keep this short- since the last few parts are long, but our learning can be summed up in the idea of the planning fallacy. For those who are not familiar with the concept, it says humans always underestimate the amount of time something will take, and we are no exception. For us, it was 100% the underestimation of debugging time. Luckily, going forward, we will assure we allocate more time to picking out these tough to find bugs.
What's next for BountAI
The next steps for BountyAI is to help share the cause, and demonstrate the power of decentralization through the story-telling and pitching hopefully, as well as continuing to optimize the codebase for better production scalability and performance.





Log in or sign up for Devpost to join the conversation.