Inspiration
Tools like Cognition's Devin and Ona made agentic coding real, but they made a hard architectural bet which is stateless ephemerality. Every task runs in a fresh, isolated environment with no long-lived state. When a session ends, the Devbox is destroyed, and every model it downloaded, every byte of context it built in memory, is gone. Every new session is a cold start.
We kept hitting the same wall with our own agents. A 50GB local model would finally be warm and working, and then we had to choose between paying for an idle GPU or killing it and losing everything. That trade-off is brutal, and it is baked into the stateless model.
So we set out to build toward a different model through an environment that is ephemeral in billing but stateful in execution. Three ideas drive the vision.
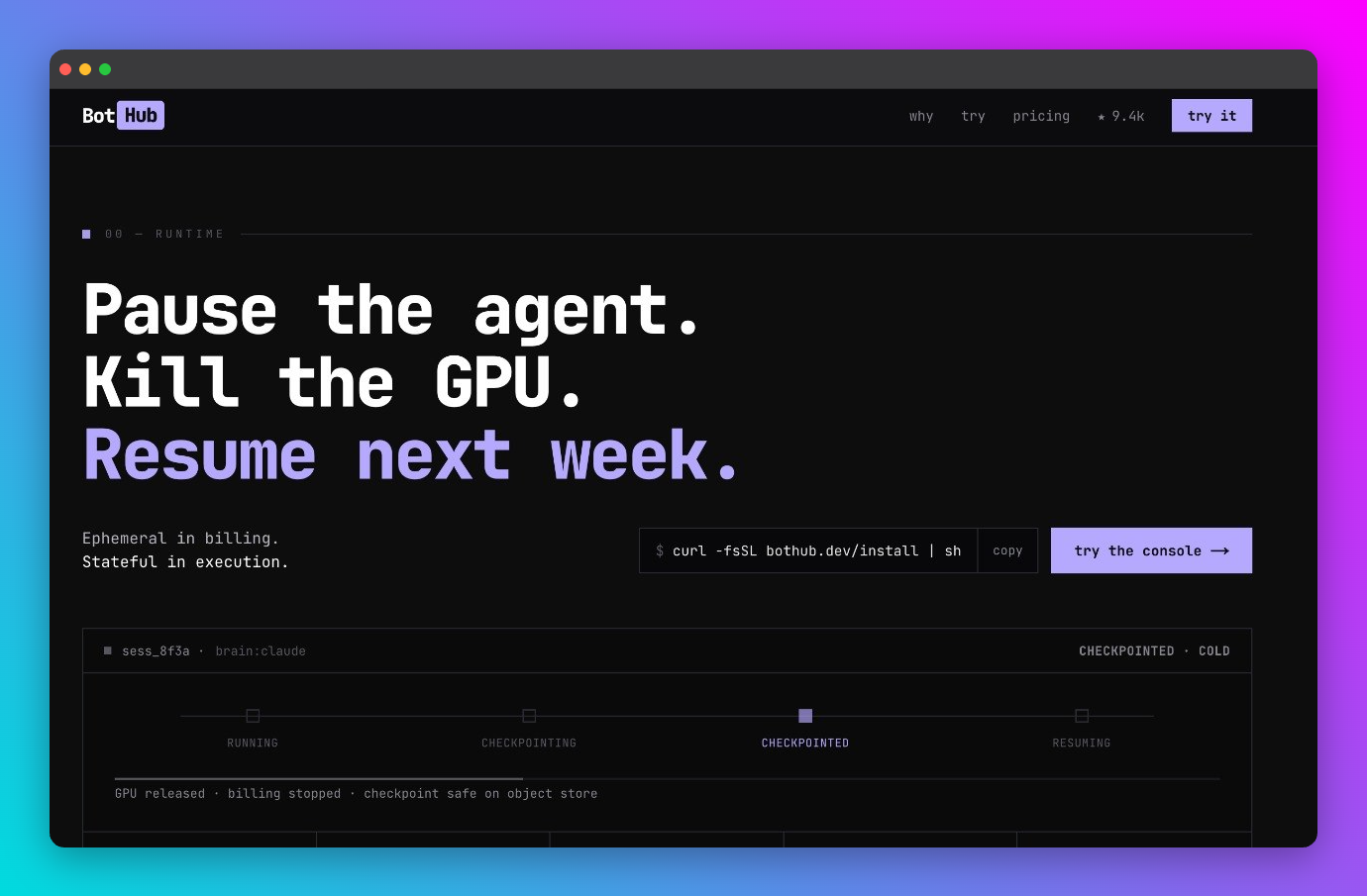
- Stateless vs. stateful ephemerality. Devin throws the environment away. We want to snapshot the live process and VRAM, so you can pause a session, kill the GPU to stop the meter, and resume exactly where it left off next week on a different machine. CRIU and NVIDIA
cuda-checkpointmake this physically possible. Our goal is to wrap it into a usable control plane. - Managed cloud vs. unmanaged bare metal. Devin locks you into managed infrastructure, either its own cloud or a dedicated AWS VPC over PrivateLink or IPSec. Meanwhile Vast.ai, RunPod, and Hyperbolic rent real GPUs for a fraction of AWS prices. They are just unmanaged and rough. We want to make that "Wild West" compute safe and first class, so you can run agents on $0.50/hr spot instances instead of $4.00/hr managed boxes.
- Brain lock-in vs. modular orchestration. Devin's "Brain", its proprietary orchestrator, always lives in Cognition's cloud and cannot be swapped. We want the execution sandbox to be brain agnostic, an open standard for the Devbox that you can point Claude, a local Llama, or your own script at.
What it does
bothub is a control plane and orchestration layer for portable, stateful GPU agents on cheap, unmanaged compute. Today it manages the fleet and drives the deploy and freeze workflow over real SSH; the actual checkpoint extraction and cloud-provider calls are stubbed behind interfaces and not yet executed against real hardware.
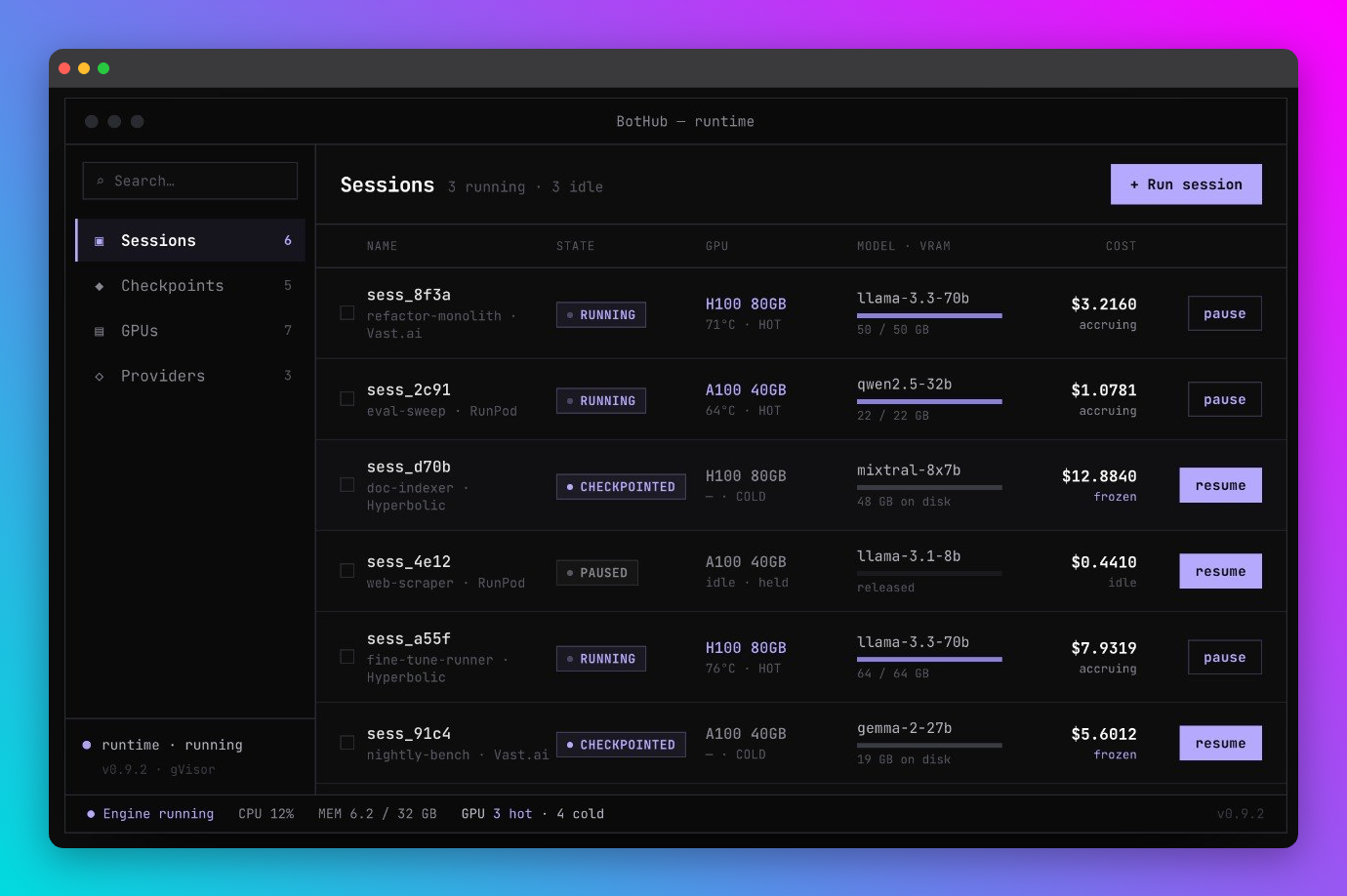
It manages two resources:
- Connections: your fleet of SSH-reachable machines (bare metal, rented RunPod or Vast GPUs, or local boxes), each tracked with its full hardware and driver fingerprint.
- Workspaces: bundled agents (config, MCP servers, SQLite context, entrypoint) plus their (intended) frozen, checkpointed state.
The core loop is deploy, freeze, thaw:
- Deploy (real SSH, partially end to end): pushes an agent's bundle to a machine over SFTP and issues the command to bootstrap it inside a privileged container as PID 1. The command construction and SSH transport are real; we have not yet run it against a live Docker host with a published runtime image.
- Freeze (orchestration real, engine stubbed): drives a four-step pipeline, lock the CUDA API, dump VRAM to host RAM via
cuda-checkpoint, CRIU-dump the process tree and SQLite locks and host RAM, then tar and pull the artifact home and destroy the rented instance. Today steps one to three and the provider teardown are stubs that issue placeholder commands; the tar and SFTP pull are real. No real GPU state has been captured or restored. - Re-deploy (designed): restores a frozen agent onto any compatible machine. The restore path is wired but, like freeze, the CRIU restore call is stubbed.
A compatibility gate (fully implemented and tested) enforces NVIDIA's hard rules before any deploy. The target must be a privileged container with the right kernel capabilities, and its driver, CUDA, and GPU topology must exactly match the frozen snapshot, so a UI can grey out the machines that would crash a restore.
How we built it
The backend is a FastAPI plus SQLModel and SQLite control plane exposing a clean REST API (/api/v1) over Connections and Workspaces.
- Real SSH orchestration via paramiko: connecting, pushing bundles over SFTP, running remote commands, pulling artifacts. Verified that it connects and surfaces failures correctly; not yet exercised against a real deploy target.
- The checkpoint dance is modeled as an explicit four-step pipeline (
lock_cuda_api,cuda_checkpoint_dump,criu_dump,teardown_and_pull) that reports the last step reached, so a partial failure is debuggable instead of a black box. Steps one to three currently send placeholder commands. - Everything host specific sits behind an interface: the SSH client, the cloud provider (RunPod, Vast, local), and the CRIU and
cuda-checkpointcalls. That let us build and fully test the entire orchestration, state machine, and compatibility engine without a real GPU, then swap stubs for real tool calls one seam at a time. - The agent is intended to run as PID 1 in a privileged container (
docker run --privileged --cap-add=CAP_CHECKPOINT_RESTORE ...) to satisfy CRIU's PID-stability requirement. - Built test first. 32 tests cover CRUD, validation, the compatibility gate, the freeze pipeline including failure paths, and the full deploy to freeze round-trip (with SSH and providers faked at their interfaces). We also booted the real server and exercised every endpoint over HTTP.
Challenges we ran into
- The privilege trap. CRIU needs
CAP_SYS_ADMINandCAP_CHECKPOINT_RESTORE. A plain SSH user cannot freeze a process tree. We made "is this box even capable of a checkpoint?" a first-class, enforced concept rather than something you discover when a freeze blows up. - PID conflicts on restore. CRIU demands the process get its exact original PID back. Running on bare metal would be a lottery, so the agent has to live inside a container with an isolated PID namespace where it is always PID 1.
- The driver and topology lock. You cannot freeze on CUDA driver 535 and thaw on 550, or move from a single A100 to dual 3090s. Encoding this as an exact-match gate over a captured hardware fingerprint, and surfacing why a machine is incompatible, took real care.
- Getting the extraction order right. "Pull the VRAM" is actually four ordered steps. Do them out of order and you corrupt the snapshot or strip the GPU mid flight. Modeling that order correctly was a design focus even though the steps are still stubbed.
- Scoping honestly under a deadline. We could not run real 80GB VRAM checkpoints in a hackathon, so we drew clean interface seams, built and tested the entire orchestration deterministically, and left the low-level tool calls as drop-in stubs rather than fake a working demo.
Accomplishments that we're proud of
- A working, spec-compliant control plane and REST API with a real deploy and freeze state machine.
- A fully implemented compatibility gate that encodes NVIDIA's privilege, PID, driver, and topology constraints and rejects an impossible restore up front instead of discovering it as a crash.
- Real SSH orchestration and a clean, swappable architecture: every host-specific call (SSH, CRIU and
cuda-checkpoint, provider) sits behind an interface, so real implementations drop in without touching the API or the state machine. - 32 passing tests plus a live end-to-end run of the real server over HTTP, including correct error handling when a target is unreachable or incompatible.
- A brain-agnostic design: the sandbox is meant to accept whatever orchestrator you bring.
What we learned
- The mechanics of CRIU and
cuda-checkpoint: how a GPU yields its state, why VRAM moves to host RAM first, and how UUID remapping is meant to make a restore land on different hardware. - That the hard part of this product is not the happy path. It is the constraints (privilege, PID stability, driver and topology), and encoding them as a gate is what would make the whole thing safe to use.
- The power of designing against interfaces. By drawing the line at the SSH, CRIU, and provider boundaries, we could build and verify a complex distributed workflow on a laptop, with no real GPU.
- How much cheaper unmanaged compute is, and how little tooling exists to make it safe, which is exactly the gap bothub aims to fill.
What's next for bothub
This is ordered by what turns the scaffolding into a real product.
- Make the checkpoint real (the headline). Integrate live
cuda-checkpointand CRIU and validate an actual freeze and restore on real NVIDIA hardware. This is the one capability the current build stubs, and it is the whole point. - CRIUgpu and parallel GPU restore so transferring 80GB of VRAM does not lock the box.
- Real provider lifecycle: RunPod, Vast.ai, and Hyperbolic APIs for one-command rent, bootstrap, freeze, and destroy.
- Hardened isolation: a gVisor sandbox inside rented instances so agents run safely on untrusted bare metal.
- A first-class CLI over the API, plus async and background deploy and freeze for long-running VRAM pulls.
- Brain-agnostic MCP injection: drop in Claude, a local Llama, or a custom orchestrator as the agent's brain.
- Production hardening: auth, secret encryption at rest, and live fleet health and topology auto-discovery.
- The bigger vision: an open standard for the stateful Devbox that makes the cheapest GPU on earth feel like a warm, always-resumable workstation.
Built With
- fastapi
- next.js
- paramiko
- pydantic
- pytest
- python
- react
- sqlalchemy
- sqlite
- sqlmodel
- typescript
- uvicorn

Log in or sign up for Devpost to join the conversation.