-

Logo
-

Goal
-
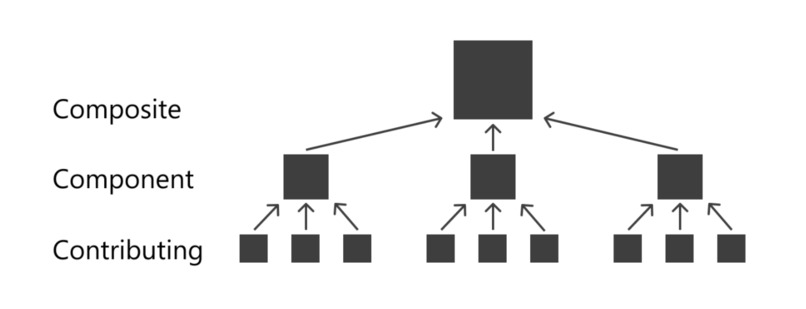
Concept
-

Home Page
-
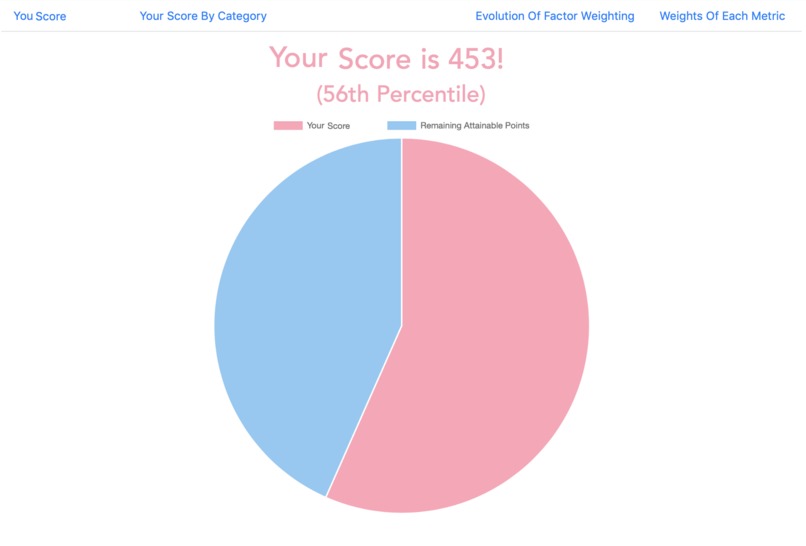
Personal Score Display
-
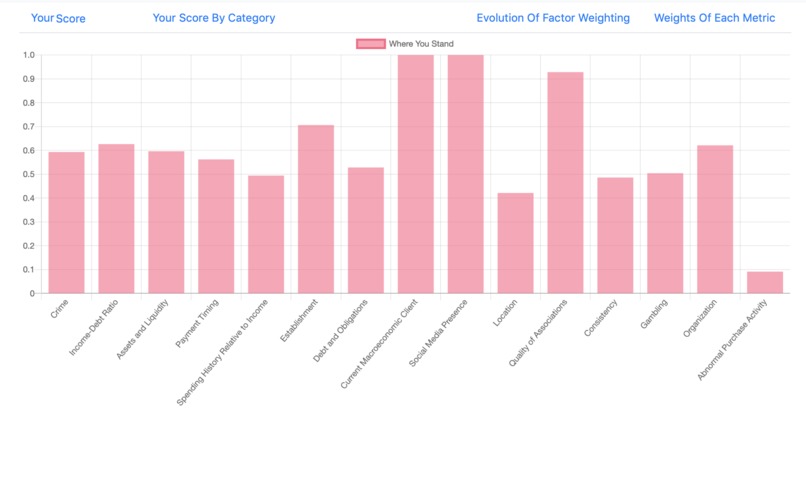
Personal Score Breakdown
-
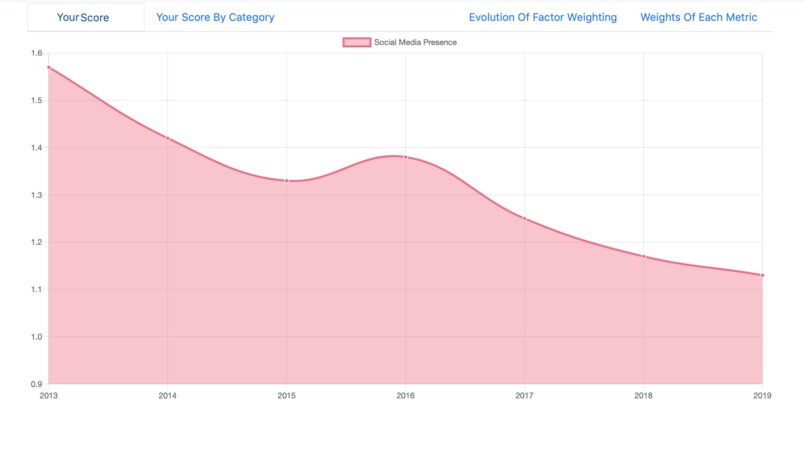
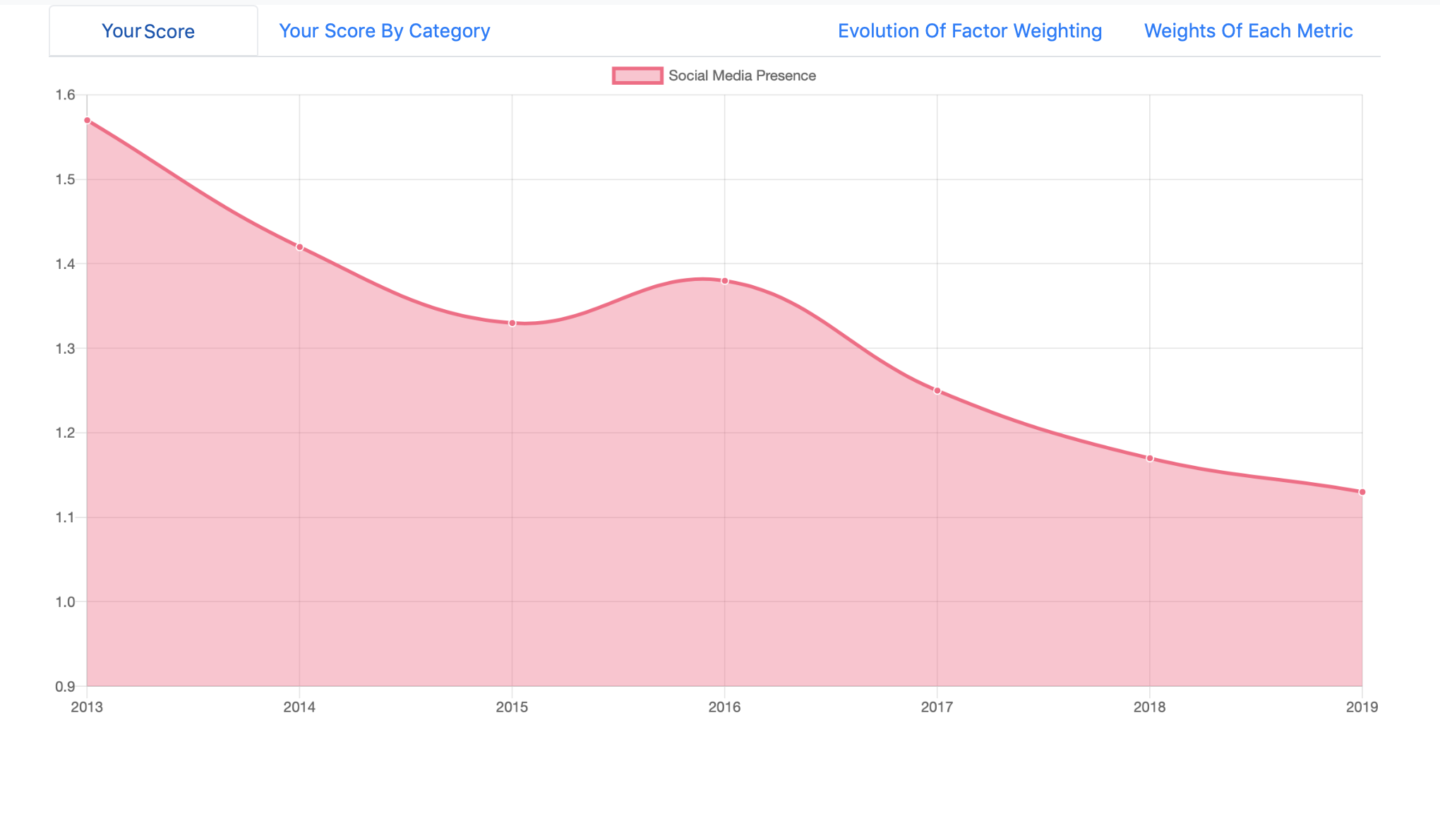
Historical Weighting of an Indicator
-
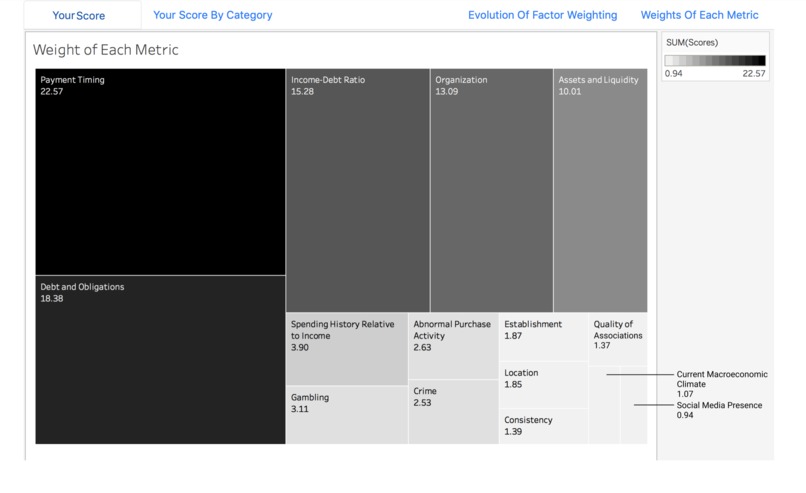
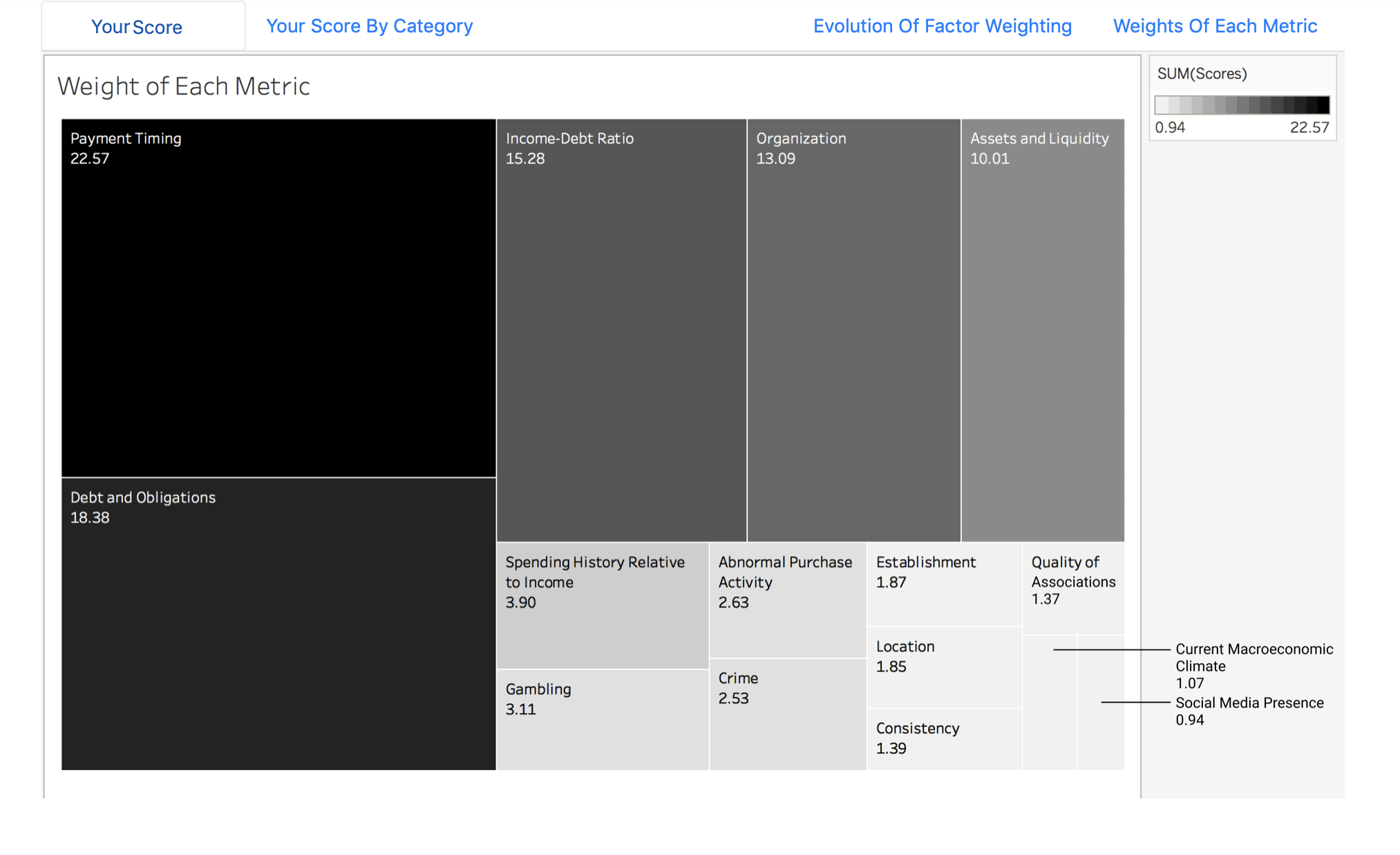
Relative Weighting of Indicators


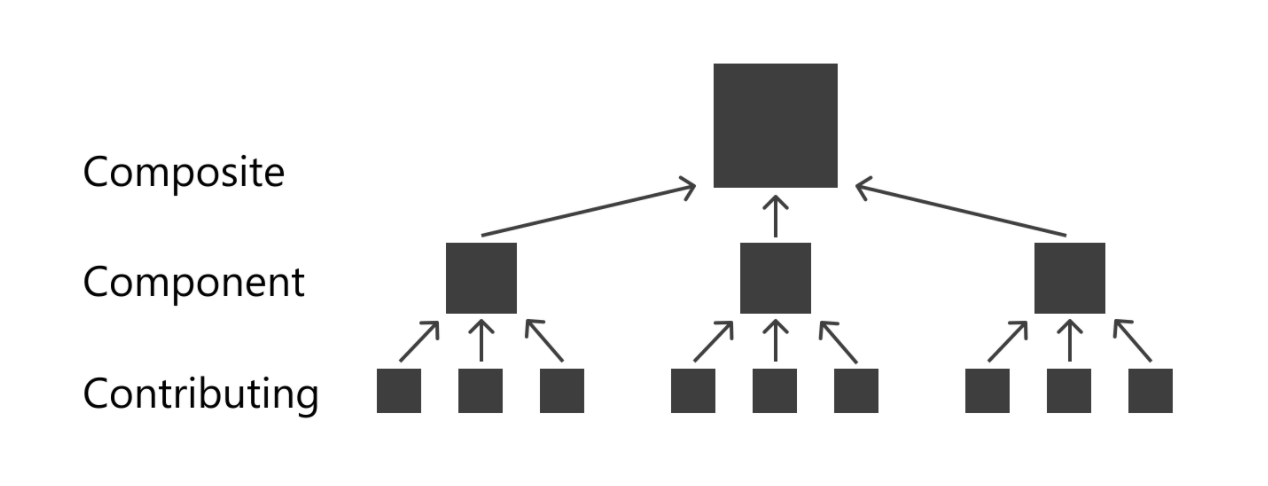

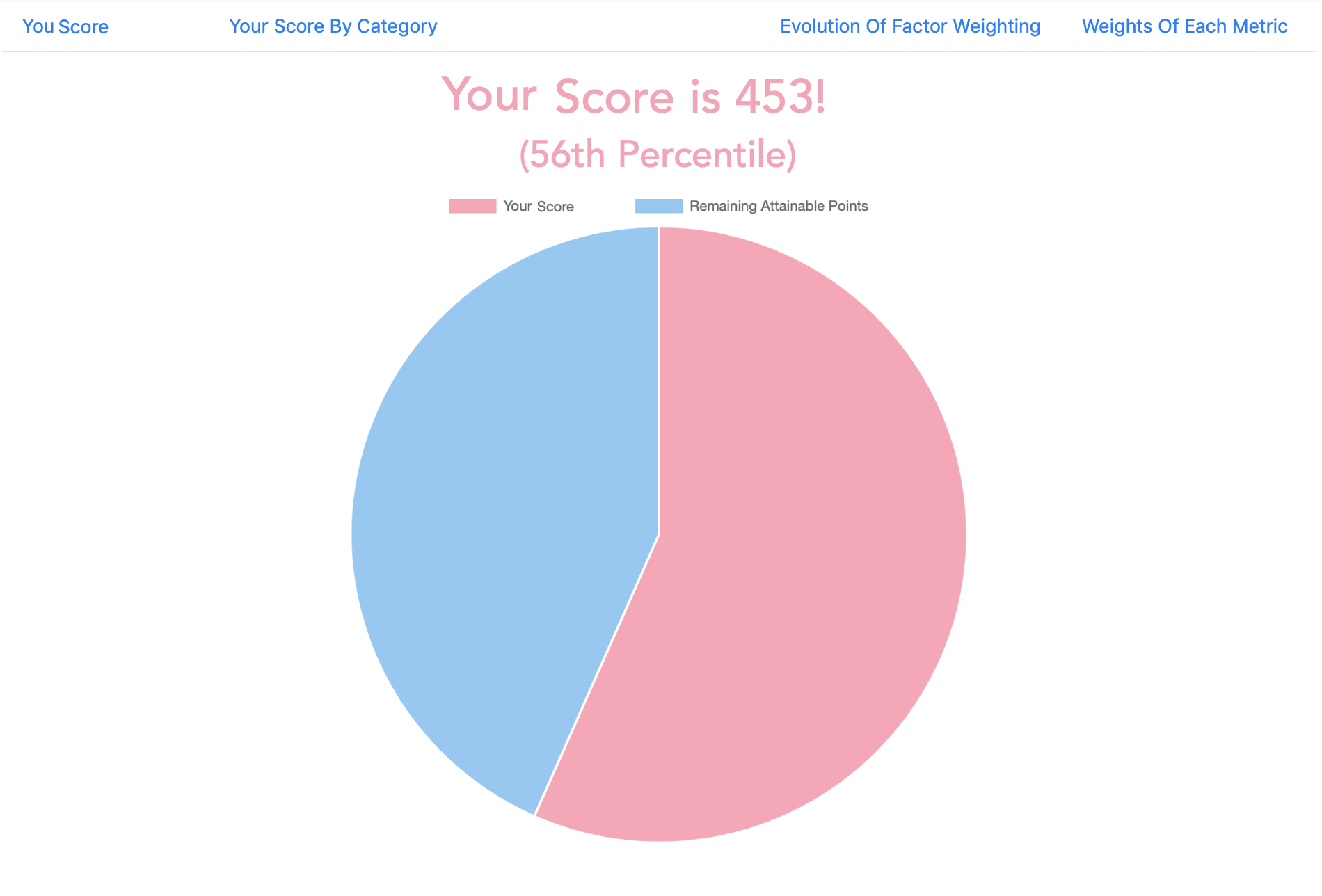
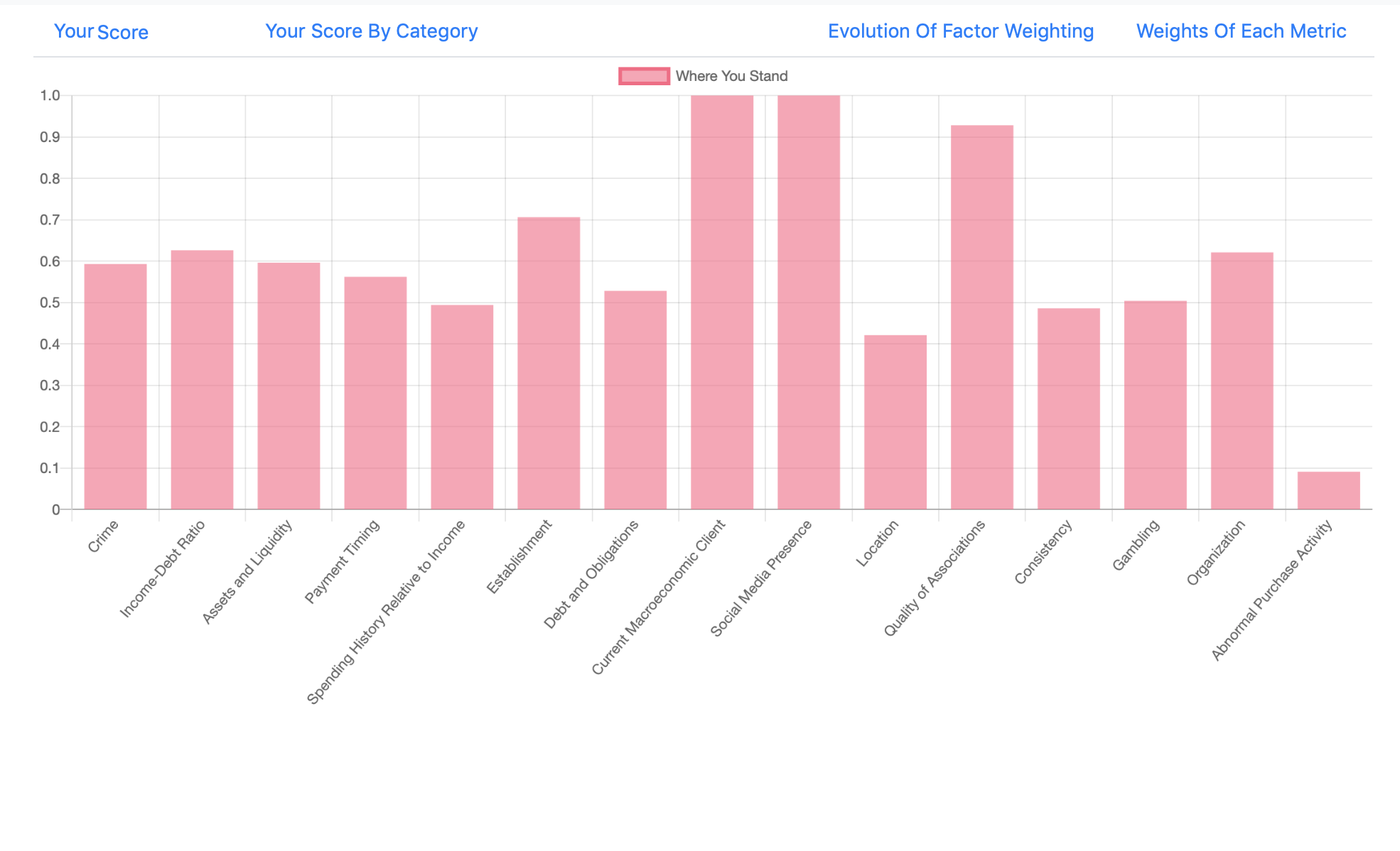
Inspiration
I got this idea from mobile phone-based finance service M-Pesa based in Kenya and Tanzania. Besides operating similarly to Venmo, M-Pesa allows its users to take out loans, calculating their trustworthiness according to their own set of metrics. Some of these metrics include SMS, phone call, and transaction history. This inspired me to look to unconventional methods of calculating our version of a credit score so we could take into consideration metrics that would create a fuller picture of our users. In this way, Borrowell is more transparent and accurate than other credit scores out there.
What it does
I reinvented the credit score from first principles, defining it as a measure of creditworthiness, then brainstorming indicators of creditworthiness from both intuition, and academic journals on economic behavior.
These indicators are then measured as objectively as possible, and tagged to an individual, along with his historical creditworthiness. By aggregating this data over tens of thousands of users, a Machine Learning algorithm then identifies correlations between indicators and creditworthiness and outputs weightings that are used to make predictions on future users.
How I built it
I wanted a simple, aesthetically pleasing, and easy to use “Single Page Application”. Knowing that a credit score system like mine would require big data scalability and easy processing, I decided to use a NoSQL (MongoDB) database and Angular on the Front End. This would also enable easy communication with our machine learning models in Flask. The REST structure provided by Angular would enable us to easily fetch data from various APIs and store relevant data per-user in my databases.
The machine learning algorithm used Sklearn’s library. I standardized the input indicators to scale from 0.0-1.0 and placed them into a 2D array. Since the datasets I needed do not exist online, I used a python function to generate the dataset and saved it as a CSV file. The Ridge Regression algorithm then learns from this and is used to make predictions. I selected Ridge Regression above other models such as Logistic Regression which would have fit the 0.0 to 1.0 probability model due to the nature of high collinearity within the data.
Challenges I ran into
One challenge I ran into was figuring out how to quantify and weight each indicator since I needed these weightings to be based on statistics and to improve over time. The first plan was to calculate the correlation for each indicator, normalize, then assign them as weightings. However, this assumes conditional independence of each indicator which may not necessarily be true.
Another challenge I encountered was figuring out how to display the information I wanted to in a clean, understandable and visually appealing way. I wanted the data to speak for itself, yet not overwhelm users, so I experimented with various data visualizations until I created charts and graphs that served the purpose well.
Accomplishments that I'm proud of
I am proud of creating a transparent, distributed credit score system where subjective decisions are made from statistics, instead of opinions. I am also proud that I was able to learn and leverage the ridge regression machine learning algorithm.
What I learned
It was interesting learning to navigate and gain experience with the field. It was also really fun getting to hop between different aspects of developing my product, from the theory and equation-forming, to the data visualizations, to the actual development. I am so grateful to have had this opportunity.
What's next for Borrowell
I believe that Borrowell has widespread applications in many facets of our lives. With the Borrowell app, users’ credit could be verified with the scan of a QR code. This would make it very easy to verify your credit-worthiness in a variety of applications, from point-of-sale loans to vehicle test drives. This would also allow for the credit score system to be transparent, distributed, and accurate in a way no other credit score system currently is.

Log in or sign up for Devpost to join the conversation.