-
-
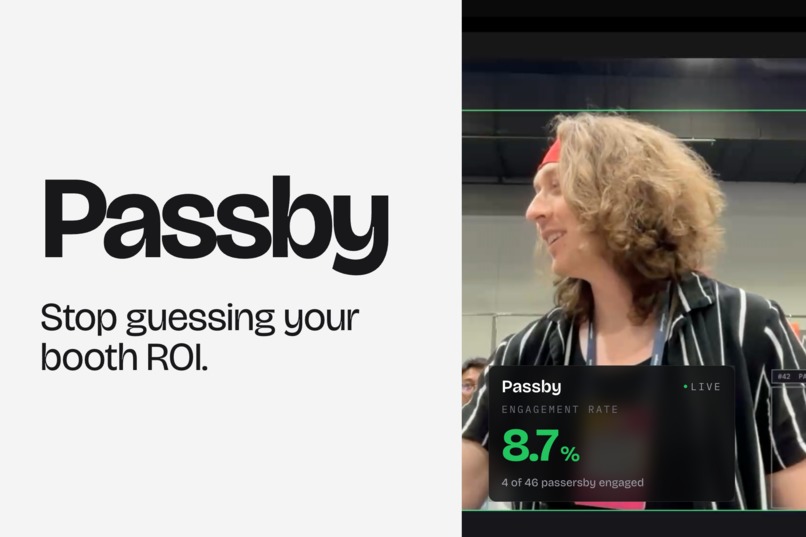
Passby. Stop guessing your booth ROI.
-

Point a laptop. See every passerby.
-

Numbers your team can actually act on.
-

Stop spending blind at trade shows.




Track Your Booth ROI
Live Demo: https://metroxe.github.io/websummit-hackathon/
Video Demo: https://youtu.be/Lt1G3LELPd8
Repo: https://github.com/Metroxe/websummit-hackathon
Inspiration
Sponsoring a booth at a conference is a black box. You pay a lot of money, you stand there for two days, and at the end you have no idea if 200 people walked past or 2000. Tracking it manually is tedious and nobody actually does it. The interesting number is the ratio. Out of everyone who walked by, how many actually got into a conversation.
How it works
Open the page, hit start camera, and the webcam feed fills the screen. Two MediaPipe models run on every frame: a person detector that draws a box around each person, and a face landmarker that locates faces and measures mouth openness from the lip landmarks. A small IOU tracker keeps the same ID on the same person across frames. When a face's mouth opens and closes repeatedly inside someone's bounding box — i.e. they're talking — that person gets upgraded from "walked by" to "engaged" and the box switches color. The HUD in the corner shows the running totals.
Everything runs in the browser. No backend, no video upload, no storage. The page is just static files on GitHub Pages.
What we learned
The biggest thing was that the model pick isn't the hard part. MediaPipe's person detector and face landmarker work fine out of the box. The hard part is the glue. Aligning the canvas overlay to the video element when the aspect ratio is weird. Decoupling inference from the render loop so the brackets don't visibly stutter at the model's frame rate. Picking a mouth-openness threshold that fires on actual speech but not on someone yawning or laughing once.
We also learned that an in-browser detector is way more capable than we expected. We were ready to ship every-other-frame inference and interpolate boxes, but a modern laptop just handles running two models in parallel.
Challenges
The hardest part was the differentiation. We started with a dwell-time heuristic — if someone's centroid stays put for a few seconds, they're engaged — but standing still is too easy. People stop to check their phone or wait for a friend. The signal was full of false positives. We swapped to mouth-movement detection: a second model tracks face landmarks, we compute lip distance normalised to face height, and only flag engagement when the mouth opens past a threshold for enough recent frames. Pairing each face back to a body bounding box is a simple point-in-box test, which is fast but breaks down when people stand very close together.
The IOU tracker is also best-effort. If someone walks out of frame for 10 seconds and comes back they get a new ID, which means they could get double counted. For a hackathon demo this is fine. For a real deployment you'd want proper re-identification, which is a much bigger project.
Built With
- coco-ssd
- html5
- react
- tensorflow.js
- typescript
- vite
- webrtc







Log in or sign up for Devpost to join the conversation.