-
-
Poster of our results
Introduction
Modern technological advances have fundamentally changed the intersection between medicine and computer science. Through the fields of artificial intelligence (machine/deep learning), computational models have become valuable tools for both data analysis and classification. In this project, we focus on the latter and aim to compare classification performance across images with and without feature suppression.
We chose to focus on medical imaging data sets and, specifically, X-ray images where bone shadows have been shown to impede visual classification by medical professionals. We therefore aim to investigate whether the suppression of such shadows can also improve disease recognition in computational models. Here we use a Convolutional Neural Network (CNN) for classification and an Auto-encoder for bone suppression. This is a challenging task as images vary highly in quality, contrast and bone shadow intensity. A significant performance increase for bone shadow suppressed images would provide evidence that bone shadow suppression is an effective denoising process that should be applied before X-ray classification models.
Bone Suppression Model
The dataset for the bone suppression model consists of normal x-ray images that contain bone shadows from rib cages and the clavicle. The target images consist of images with these shadows removed from the images.
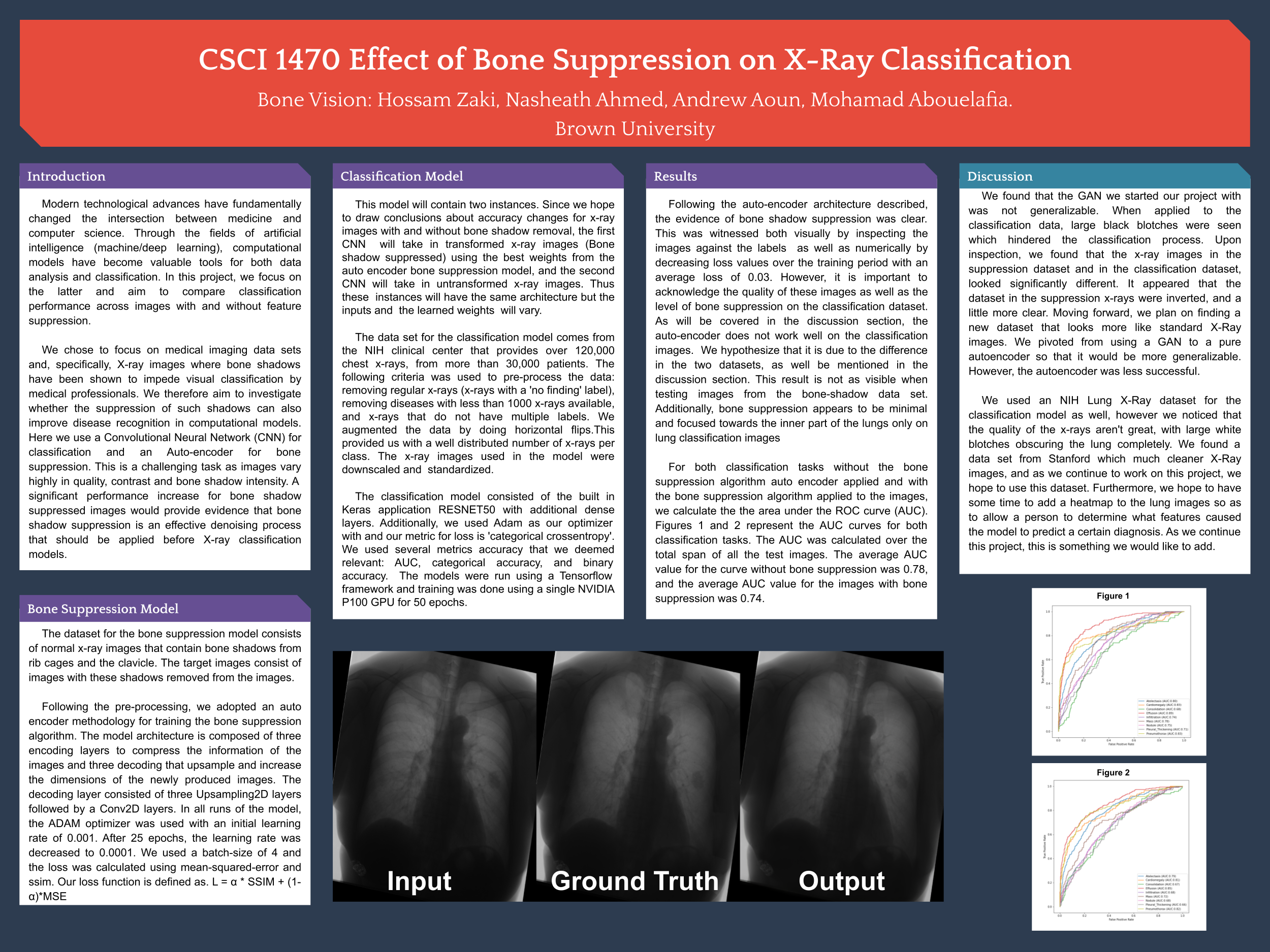
Following the pre-processing, we adopted an auto encoder methodology for training the bone suppression algorithm. The model architecture is composed of three encoding layers to compress the information of the images and three decoding that upsample and increase the dimensions of the newly produced images. The decoding layer consisted of three Upsampling2D layers followed by a Conv2D layers. In all runs of the model, the ADAM optimizer was used with an initial learning rate of 0.001. After 25 epochs, the learning rate was decreased to 0.0001. We used a batch-size of 4 and the loss was calculated using mean-squared-error and ssim. Our loss function is defined as. L = α * SSIM + (1-α)*MSE
Classification Model
This model will contain two instances. Since we hope to draw conclusions about accuracy changes for x-ray images with and without bone shadow removal, the first CNN will take in transformed x-ray images (Bone shadow suppressed) using the best weights from the auto encoder bone suppression model, and the second CNN will take in untransformed x-ray images. Thus these instances will have the same architecture but the inputs and the learned weights will vary.
The data set for the classification model comes from the NIH clinical center that provides over 120,000 chest x-rays, from more than 30,000 patients. The following criteria was used to pre-process the data: removing regular x-rays (x-rays with a 'no finding' label), removing diseases with less than 1000 x-rays available, and x-rays that do not have multiple labels. We augmented the data by doing horizontal flips.This provided us with a well distributed number of x-rays per class. The x-ray images used in the model were downscaled and standardized.
The classification model consisted of the built in Keras application RESNET50 with additional dense layers. Additionally, we used Adam as our optimizer with and our metric for loss is 'categorical crossentropy'. We used several metrics accuracy that we deemed relevant: AUC, categorical accuracy, and binary accuracy. The models were run using a Tensorflow framework and training was done using a single NVIDIA P100 GPU for 50 epochs.
Results
Following the auto-encoder architecture described, the evidence of bone shadow suppression was clear. This was witnessed both visually by inspecting the images against the labels as well as numerically by decreasing loss values over the training period with an average loss of 0.03. However, it is important to acknowledge the quality of these images as well as the level of bone suppression on the classification dataset. As will be covered in the discussion section, the auto-encoder does not work well on the classification images. We hypothesize that it is due to the difference in the two datasets, as well be mentioned in the discussion section. This result is not as visible when testing images from the bone-shadow data set. Additionally, bone suppression appears to be minimal and focused towards the inner part of the lungs only on lung classification images
For both classification tasks without the bone suppression algorithm auto encoder applied and with the bone suppression algorithm applied to the images, we calculate the the area under the ROC curve (AUC). Figures 1 and 2 represent the AUC curves for both classification tasks. The AUC was calculated over the total span of all the test images. The average AUC value for the curve without bone suppression was 0.78, and the average AUC value for the images with bone suppression was 0.74.
Discussion
We found that the GAN we started our project with was not generalizable. When applied to the classification data, large black blotches were seen which hindered the classification process. Upon inspection, we found that the x-ray images in the suppression dataset and in the classification dataset, looked significantly different. It appeared that the dataset in the suppression x-rays were inverted, and a little more clear. Moving forward, we plan on finding a new dataset that looks more like standard X-Ray images. We pivoted from using a GAN to a pure autoencoder so that it would be more generalizable. However, the autoencoder was less successful.
We used an NIH Lung X-Ray dataset for the classification model as well, however we noticed that the quality of the x-rays aren't great, with large white blotches obscuring the lung completely. We found a data set from Stanford which much cleaner X-Ray images, and as we continue to work on this project, we hope to use this dataset. Furthermore, we hope to have some time to add a heatmap to the lung images so as to allow a person to determine what features caused the model to predict a certain diagnosis. As we continue this project, this is something we would like to add.
Ethics
We believe that Deep Learning would be an effective solution to this problem. Since we are looking solely at X-Rays, there will be no bias towards people of color and no reference to their background. The X-Rays, for all people, look the same, so this type of bias will not be seen in our trained model. Also, our dataset is directly from the NIH, and consists of over 30,000 unique patients from all over the country. Our data also has no ways to figure out the person who the X-Ray was taken from. We only have an ID associated with the patient. We do not know which hospital it was taken from, nor the age of the patient. The major stakeholders of this problem are the doctor and the patient. If this doesn’t work properly, then the patient may be misdiagnosed which can be disastrous. For example, as shown in the Related Work section, specificity showed a decrease from 95% without BSI to 90% with the bone suppression algorithm that was written
Important Links
Built With
- keras
- matplot
- python



Log in or sign up for Devpost to join the conversation.